coco-2017-vietnamese
收藏COCO-2017-Vietnamese 数据集概述
基本信息
- 数据集名称: COCO-2017-Vietnamese
- 维护团队: AI Enthusiasm
- 官方主页: https://aienthusiasm.vn
- Hugging Face组织: https://huggingface.co/ai-enthusiasm-community
- 语言: 越南语 (vi), 英语 (en)
- 许可证: cc-by-4.0
- 规模: 100k<n<1M
数据集摘要
COCO-2017-Vietnamese 是 Microsoft Common Objects in Context (COCO) 2017 数据集的本地化版本。该版本专为越南语跨模态研究而策划,包含原始英文描述与高质量越南语翻译的配对。它是在双语框架下进行图像描述和多模态学习等任务的综合基准。
任务与标签
- 任务类别: 图像到文本 (image-to-text), 文本到图像 (text-to-image)
- 标签: vision, image-captioning, coco, vietnamese
数据集结构
数据集以扁平化的表格格式提供,针对 Hugging Face Dataset Viewer 和高速 Parquet 处理进行了优化。
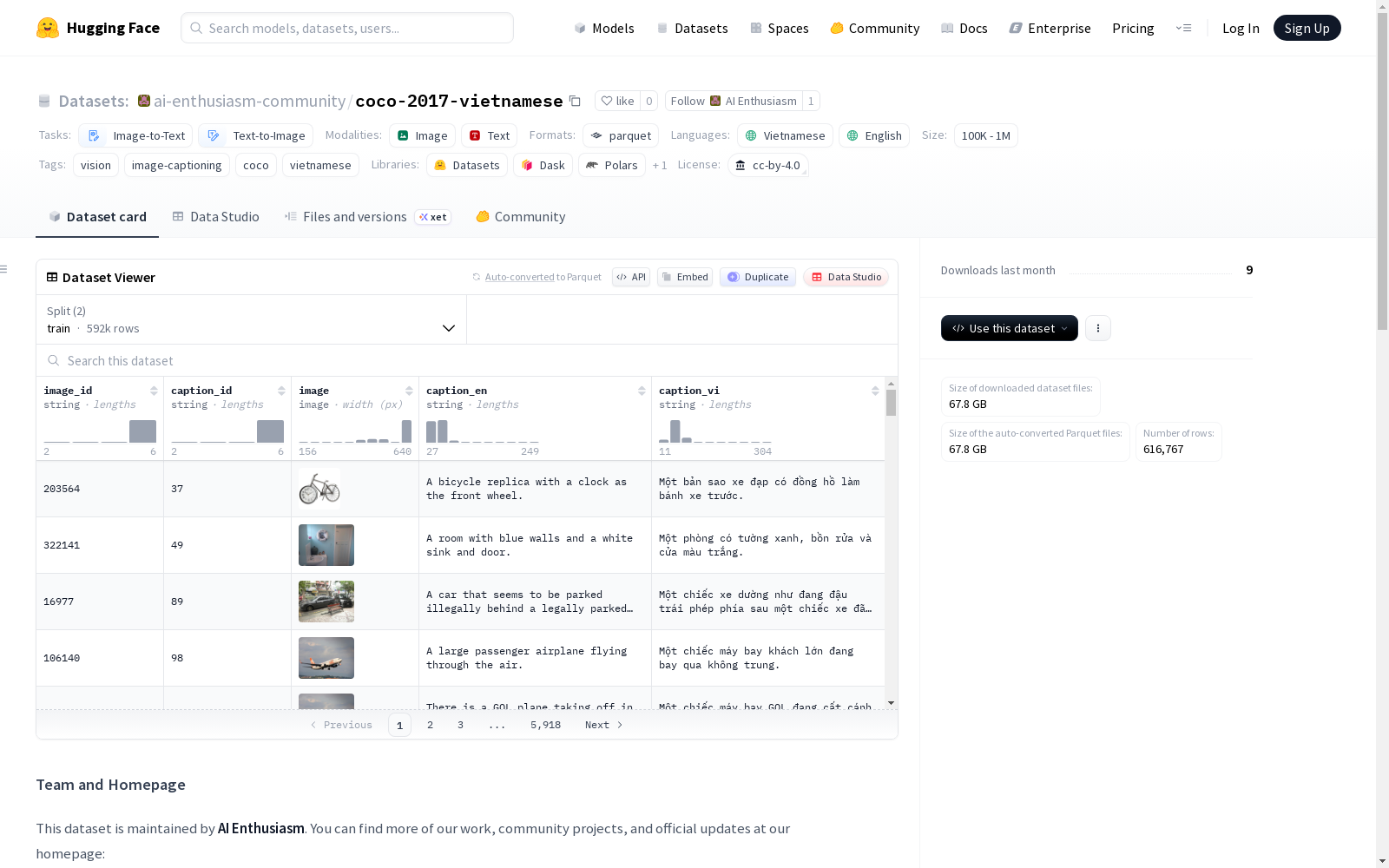
数据实例
每个实例代表一个图像-描述对。为保持与标准训练流程的兼容性,图像数据会为每个关联的描述重复。
数据字段
image_id: 原始 COCO 数据集中的图像 ID。caption_id: 每个特定标注(描述)的唯一 ID。image: 包含视觉数据的图像对象。caption_en: 原始的英文描述文本。caption_vi: 翻译的越南语描述文本。
数据划分与规模
- 训练集 (train):
- 样本数量: 591,753
- 字节大小: 95,104,738,954.827
- 验证集 (validation):
- 样本数量: 25,014
- 字节大小: 3,666,417,387.754
- 下载大小: 67,774,085,459
- 数据集总大小: 98,771,156,342.581
使用方式
可以使用 Hugging Face datasets 库直接访问该数据集:
python
from datasets import load_dataset
dataset = load_dataset("ai-enthusiasm-community/coco-2017-vietnamese")
引用信息
@inproceedings{lin2014microsoft, title={Microsoft coco: Common objects in context}, author={Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll{a}r, Piotr and Zitnick, C Lawrence}, booktitle={Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13}, pages={740--755}, year={2014}, organization={Springer} }