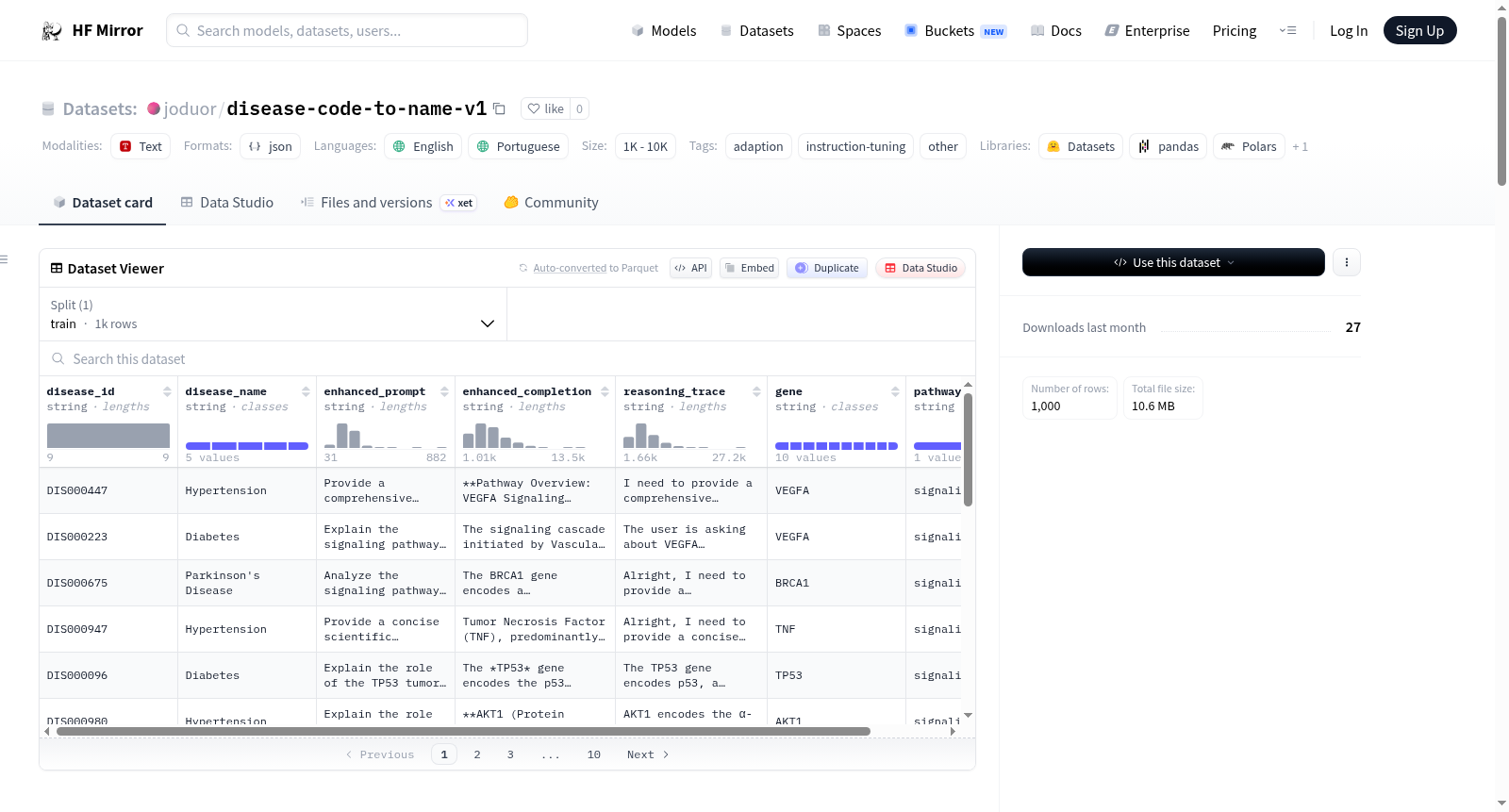
joduor/disease-code-to-name-v1
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/joduor/disease-code-to-name-v1
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators: []
language:
- en
- pt
language_creators: []
license: []
multilinguality:
- multilingual
pretty_name: 'disease_code_to_name'
size_categories:
- 1K<n<10K
source_datasets:
- 'original'
tags:
- adaption
- instruction-tuning
- other
task_categories: []
task_ids: []
---

This dataset is a remastered version prepared using [Adaption's](https://adaptionlabs.ai/app/auth) Adaptive Data platform.
# disease_code_to_name
This dataset consists of pairs mapping unique disease identification codes (e.g., DIS000940) to their corresponding medical condition names. The samples cover a range of chronic diseases including Alzheimer's, Parkinson's, Breast Cancer, Hypertension, and Diabetes. It serves as a lookup resource for translating standardized disease identifiers into human-readable labels.
### Dataset size
There are 1,000 data points in this dataset. This is an instruction tuning dataset.
### Quality of Remastered Dataset
The final quality is B, with a relative quality improvement of 740.0%.
### Domain
- Other (100%)
### Language
- English (96%)
- Portuguese (4%)
### Tone
- Objective (82%)
- Informative (18%)
### Evaluation Results
- **Quality Gains:**
<img src="https://proteus-prod-public.s3.us-east-1.amazonaws.com/temp/44630cda-b211-495b-8dd1-64a1d6ad2e5d.png" alt="QualityGains" style="max-width: 50%; display: block; margin-left: auto; margin-right: auto;" />
- **Grade Improvement:**
<img src="https://proteus-prod-public.s3.us-east-1.amazonaws.com/temp/10a8f936-3049-4f56-9b72-0c92c3f93e23.png" alt="Grade" style="max-width: 50%; display: block; margin-left: auto; margin-right: auto;" />
- **Percentile Chart:**
<img src="https://proteus-prod-public.s3.us-east-1.amazonaws.com/temp/f63c2559-2c33-49e5-b948-15d858d1f4c3.png" alt="Percentile Chart" style="max-width: 50%; display: block; margin-left: auto; margin-right: auto;" />
提供机构:
joduor
搜集汇总
数据集介绍
构建方式
在生物医学信息学领域,标准化疾病编码与可读名称的映射是提升数据互操作性的关键。本数据集依托Adaption的Adaptive Data平台进行重构,通过系统化处理原始数据,生成了包含1000条数据点的指令调优数据集。重构过程显著提升了数据质量,相对质量改善率达到740%,最终质量评级为B,确保了编码与名称对应关系的准确性和一致性。
特点
该数据集以多语言形式呈现,涵盖英语和葡萄牙语,其中英语占比96%,葡萄牙语占比4%,为跨语言医学信息处理提供了便利。数据内容聚焦于慢性疾病,如阿尔茨海默病、帕金森病、乳腺癌、高血压和糖尿病等,每条记录均包含独特的疾病识别码(如DIS000940)及其对应的医学条件名称。整体语调以客观性为主(82%),辅以信息性(18%),结构清晰,适合作为查询参考资源。
使用方法
作为指令调优数据集,其主要应用于自然语言处理模型的训练与优化,特别是在医学文本理解与生成任务中。使用者可借助该数据集构建或增强疾病编码与名称之间的翻译模型,提升模型在识别和转换标准化医学标识符方面的性能。在实际应用中,它可作为查找表,辅助研究人员或临床系统快速将编码转换为可读标签,从而支持更高效的医学数据管理与分析。
背景与挑战
背景概述
在医学信息学与自然语言处理交叉领域,标准化疾病编码与可读名称之间的映射是支撑临床决策支持系统、电子健康记录互操作以及医学知识图谱构建的基础性任务。disease-code-to-name-v1数据集由Adaption Labs通过其自适应数据平台重构而成,旨在提供从唯一疾病标识符(如DIS000940)到对应医学病症名称的精确配对。该数据集聚焦于阿尔茨海默病、帕金森病、乳腺癌、高血压与糖尿病等多种慢性疾病,其多语言特性(涵盖英语与葡萄牙语)进一步拓展了其在全球化医疗语境下的应用潜力,为指令微调等下游任务提供了结构化的参考资源。
当前挑战
该数据集致力于解决医学编码标准化与自然语言理解之间的映射挑战,核心在于确保疾病标识符与临床术语之间的一致性与准确性,以支持自动化医疗文本处理系统。在构建过程中,面临多语言医学术语对齐的复杂性,需协调英语与葡萄牙语间的语义差异与命名规范;同时,数据质量提升涉及原始信息的清洗、去歧义与标准化,以达成较高的相对质量改进,并维持客观、信息性的语料风格,这些步骤均对标注一致性与领域专业性提出了较高要求。
常用场景
经典使用场景
在医学信息学领域,标准化编码与可读标签之间的映射是数据整合的基础环节。disease-code-to-name-v1数据集通过提供疾病识别码与医学名称的配对,为自然语言处理模型在指令微调场景下的性能优化提供了关键资源。该数据集典型应用于训练模型理解并准确转换如DIS000940等编码至阿尔茨海默病、帕金森病等具体疾病名称,从而提升医疗文本的自动化解析效率。
解决学术问题
该数据集直接应对医学数据标准化中的语义鸿沟问题,即如何将结构化的疾病编码系统与人类可读的临床术语进行有效关联。其解决了跨语言医疗信息检索、电子健康记录自动化标注以及多源医学数据库集成等研究挑战,为构建统一的医学知识表示框架提供了实证基础,显著促进了医疗自然语言处理领域的模型泛化能力与解释性研究。
衍生相关工作
基于该数据集的映射关系,衍生出多项经典研究工作,包括用于多语言医疗问答系统的指令微调模型、疾病编码标准化工具的开发以及医学本体对齐算法的优化。这些工作进一步扩展至跨语种医疗知识图谱构建、自适应临床术语推荐引擎等领域,推动了医学人工智能在真实世界应用中的技术演进与范式创新。
以上内容由遇见数据集搜集并总结生成


