ViDiC-1K
收藏Hugging Face2025-12-04 更新2025-12-05 收录
下载链接:
https://huggingface.co/datasets/NJU-LINK/ViDiC-1K
下载链接
链接失效反馈官方服务:
资源简介:
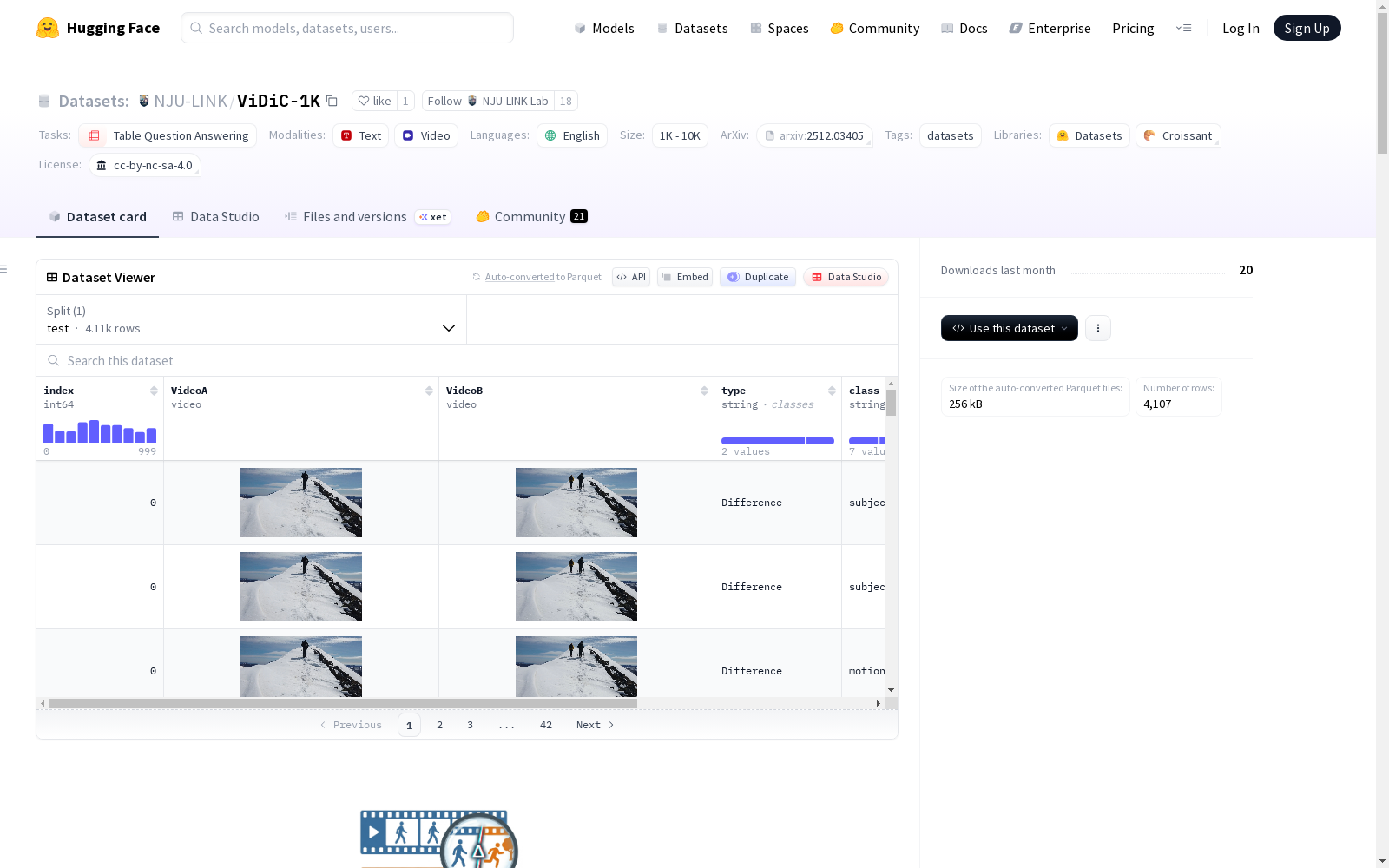
ViDiC(视频差异描述)是一个新的任务,将差异描述扩展到视频领域。ViDiC-1K基准测试旨在评估多模态大语言模型(MLLMs)对视频对之间相似性和差异性的细粒度描述能力。该基准测试超越了传统的视频相似性或视频编辑指标,专注于编辑理解而非编辑执行。ViDiC-1K数据集包含1000个精心挑选的视频对,标注了超过4000个比较检查项,采用双检查表评估框架,分别评估相似性(检查幻觉)和差异性(检查感知)。数据集还提供了可扩展的LLM-as-a-Judge自动评估协议,使用GPT-5-Mini量化与人工验证的真实情况的准确性。
创建时间:
2025-12-01
原始信息汇总
ViDiC-1K 数据集概述
基本信息
- 数据集名称: ViDiC-1K (Video Difference Captioning)
- 维护者: NJU-LINK
- 托管地址: https://huggingface.co/datasets/NJU-LINK/ViDiC-1K
- 许可证: CC-BY-NC-SA-4.0
- 任务类别: 表格问答 (Table Question Answering)
- 主要语言: 英语 (en)
- 数据规模: 1K < n < 10K
- 数据文件: 包含一个测试集 (
test.csv)
任务与目标
- 核心任务: 视频差异描述 (Video Difference Captioning, ViDiC)
- 任务描述: 扩展差异描述任务至视频领域,要求模型对视频对之间的相似性和差异性提供细粒度的描述。该任务侧重于编辑理解,而非编辑执行。
- 评估重点: 评估多模态大语言模型 (MLLMs) 对视频对的描述性、比较性和时序性理解能力。
数据集构成
- 视频对总数: 1,000 对 (包含真实与合成数据)
- 检查项总数: 约 4,100 项 (其中 1,056 项为相似性检查,3,051 项为差异性检查)
- 评估维度: 7 个类别 (主体、风格、背景、摄像机、运动、位置、播放技术)
- 视频时长: 主要为 2-12 秒
- 数据来源: 精选自 8 个以上公共数据集 (如 VidDiffBench, LMArena) 以及自生成的合成数据 (使用 Veo3 和帧拼接技术)。
关键特性
- 首个视频差异描述基准: 一个需要描述性、比较性和时序性理解的统一任务。
- 双检查表评估框架: 严格的评估框架,分别评估相似性 (检查幻觉) 和差异性 (检查感知)。
- 可扩展的 LLM 即法官评估: 使用 GPT-5-Mini 的自动化、可解释评估协议,根据人工验证的基准事实量化事实准确性。
基准测试结果摘要
- 性能领先模型: Gemini-2.5-Pro (总体平均分 66.72) 和 Qwen3-VL-32B (总体平均分 61.38,开源模型中最佳)。
- 主要发现:
- 显著差距: 描述时序差异 (运动、摄像机) 比描述静态属性 (风格、主体) 困难得多。
- 权衡: “思考”模型提高了差异检测能力,但常在相同区域产生幻觉 (导致相似性得分降低)。
- 关键弱点: 几乎所有模型在播放技术 (如倒放、慢动作) 类别上都表现不佳。
使用与访问
-
快速下载: bash hf download NJU-LINK/ViDiC-1K --local-dir ./ViDiC-1K
-
相关资源:
- GitHub 项目: https://github.com/NJU-LINK/ViDiC-1K
- 论文地址: https://arxiv.org/abs/2512.03405
- 项目主页: https://vidic-1k.github.io/
引用信息
如果研究中使用 ViDiC,请考虑引用相关论文: bibtex @misc{wu2025vidicvideodifferencecaptioning, title={ViDiC: Video Difference Captioning}, author={Jiangtao Wu and Shihao Li and Zhaozhou Bian and Yuanxing Zhang and Jialu Chen and Runzhe Wen and An Ping and Yiwen He and Jiakai Wang and Jiaheng Liu}, year={2025}, eprint={2512.03405}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2512.03405}, }
搜集汇总
数据集介绍
构建方式
在视频理解领域,构建能够精准描述动态场景差异的数据集面临诸多挑战。ViDiC-1K数据集通过精心策划的流程构建而成,其核心在于收集并标注了1000对视频对。数据来源融合了来自VidDiffBench、LMArena等八个以上公开数据集的真实视频,并辅以利用Veo3模型结合帧拼接技术生成的高质量合成数据。每个视频对均经过人工标注,生成了覆盖七个维度的、超过4100个细粒度比较检查项,从而确保了数据在编辑理解任务上的丰富性与严谨性。
使用方法
该数据集主要服务于多模态大语言模型在视频差异描述任务上的评估与能力提升。研究者可通过Hugging Face平台便捷下载数据集,并利用其提供的结构化测试集进行评估。使用流程通常涉及将视频对输入目标模型,引导模型生成描述文本,随后依据数据集中提供的细粒度检查表,通过自动化评估协议(如基于GPT-5-Mini的LLM-as-a-Judge方法)对生成描述的准确性进行量化评分。这为系统性地衡量模型在理解视频间复合性、空间性与时序性变化方面的能力提供了标准化的基准平台。
背景与挑战
背景概述
视频理解作为计算机视觉与自然语言处理交叉领域的前沿课题,其核心在于赋予机器解析动态视觉场景并生成语义描述的能力。传统图像差异描述任务已能处理静态画面的语义变化,但面对蕴含连续运动、事件演进与编辑一致性的视频序列时,其局限性日益凸显。为突破这一瓶颈,南京大学LINK实验室于2025年提出了ViDiC-1K数据集,旨在将差异描述任务拓展至视频领域,系统评估多模态大语言模型对视频对的细粒度相似性与差异性进行描述的能力。该数据集的构建标志着视频编辑理解研究从执行层面转向深度语义解析,为模型在动态场景中的比较感知与时空推理设立了新的基准。
当前挑战
ViDiC-1K数据集所应对的核心领域挑战在于推动模型实现视频对的复合性、空间性与时序性差异理解。现有视觉语言系统在捕捉运动连续性、事件演化轨迹及编辑一致性方面存在显著不足,难以对摄像机运动、播放技术等动态属性进行精准描述。在数据集构建过程中,研究者面临多重挑战:需从超过八个公开数据源中筛选并整合视频对,同时生成合成数据以确保多样性;设计涵盖主体、风格、背景、摄像机、运动、位置与播放技术等七个维度的细粒度标注体系;建立基于双重检查表的评估框架,以分离评估相似性描述中的幻觉问题与差异性描述的感知准确性,这要求标注具备高度的严谨性与一致性。
常用场景
经典使用场景
在视频理解与多模态人工智能领域,ViDiC-1K数据集为视频差异描述任务提供了首个标准化基准。该数据集的核心使用场景在于评估多模态大语言模型对视频对的精细化比较与描述能力。模型需要分析两个视频在七个维度上的异同,包括主体、风格、背景、摄像机运动、物体运动、位置以及播放技术,并生成结构化的自然语言描述。这一过程不仅检验模型对静态视觉属性的感知,更挑战其对动态时序变化的捕捉与连贯叙述能力,为视频编辑理解、内容审核等下游任务奠定了评估基础。
解决学术问题
ViDiC-1K数据集旨在解决现有视觉语言系统在动态场景比较理解方面的核心局限。传统图像差异描述方法无法捕捉视频中运动连续性、事件演变或编辑一致性等时序特征。该数据集通过引入视频差异描述任务,将研究焦点从简单的视频相似性度量或编辑执行,转向更深层的编辑理解。它系统性地量化了模型在感知动态差异与避免幻觉之间的权衡,揭示了当前多模态模型在摄像机运动、播放技术等时序维度上的显著弱点,从而推动了视频级细粒度理解评估框架的发展。
实际应用
该数据集的实际应用价值广泛体现在需要对视频内容进行自动化比较与分析的场景中。在视频内容审核领域,系统可借助此类能力自动识别篡改、深度伪造或违规编辑行为。在影视后期制作与教育领域,它能辅助自动化生成剪辑说明或教学视频的差异分析报告。此外,在智能监控与自动驾驶系统中,对连续场景变化的精准描述有助于理解环境动态与异常事件。ViDiC-1K为这些应用提供了可靠的性能评测基准,促进了鲁棒且可解释的视频比较技术的落地。
数据集最近研究
最新研究方向
在视频理解与多模态大语言模型领域,ViDiC-1K数据集的推出标志着视频差异描述任务的前沿探索。该任务要求模型超越静态图像的语义比较,深入解析视频对之间在主体、运动、背景、相机视角、风格及播放技术等七个维度的动态差异与相似性,从而推动模型对时序连续性、事件演化及编辑一致性的精细感知。当前研究热点聚焦于利用双清单评估框架,结合可扩展的大语言模型作为评判者,系统量化模型在差异感知与幻觉抑制之间的权衡,尤其针对相机运动与播放技术等时序性强的薄弱环节进行性能突破。这一方向不仅为视频编辑理解、内容审核及自动摘要等应用提供了新的评估基准,也揭示了多模态模型在复杂时空推理能力上的关键局限与未来改进路径。
以上内容由遇见数据集搜集并总结生成


