namakoo/idfu-vector-search-specialty
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/namakoo/idfu-vector-search-specialty
下载链接
链接失效反馈官方服务:
资源简介:
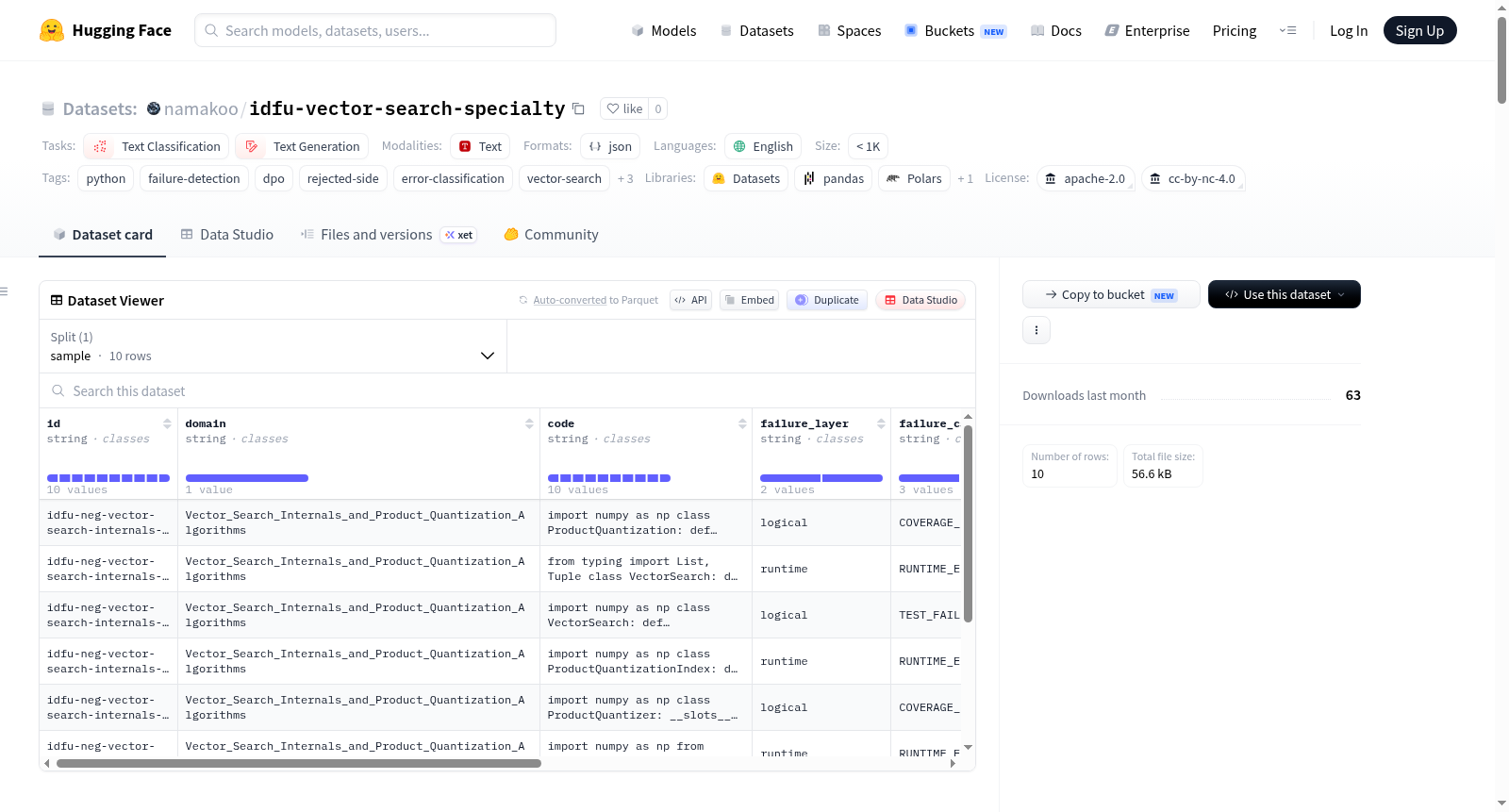
IDFU向量搜索专业包是一个专注于向量搜索内部和产品量化算法的单领域Python失败数据集,设计作为IDFU代码失败数据集家族的低成本入门点。该数据集包含82个样本,其中10个样本作为免费预览提供。数据集价格为9美元,面向RAG/搜索工程师。每个样本包含代码、失败层、失败类别和原始任务描述等字段。数据集经过严格的QA流程验证,保证与其他IDFU版本无重复。预期用途包括领域聚焦的错误检测分类器训练、定向DPO拒绝侧训练数据和代码审查模型微调。
The IDFU Vector Search Specialty Pack is a single-domain Python failure dataset focused on Vector Search Internals and Product Quantization Algorithms, designed as a low-cost entry point to the IDFU Code Failure Dataset family. The dataset includes 82 samples, with a free preview of 10 samples available. Priced at $9 USD, it targets RAG/search engineers. Each sample contains fields such as code, failure_layer, failure_category, and instruction. The dataset undergoes a rigorous QA pipeline and is guaranteed to be unique and non-overlapping with other IDFU releases. Intended uses include domain-focused error detection classifier training, targeted DPO rejected-side training data, and code review model fine-tuning.
提供机构:
namakoo
搜集汇总
数据集介绍
构建方式
该数据集的构建专注于向量搜索与乘积量化算法领域的Python代码失败样本,共包含82条经过严格验证的样本。每条样本均通过α归一化AST的规范哈希去重处理,消除仅因代码风格差异导致的重复。随后,样本需通过静态检查门控(如死函数、类型不一致等规则)和容器化Python执行环境下的pytest测试框架,以捕获实际运行时、语法、逻辑、语义等层面的故障。最终,所有样本还需通过专有的内部质量验证流水线,并附加指令质量过滤(如拒绝占位符去除),从而确保每条样本兼具代码真实失败信号与高质量指令配对结构。
特点
本数据集的最大特色在于其高度聚焦的领域专一性:全部样本均围绕向量搜索与乘积量化算法主题,覆盖PQ训练中的索引越界、高维向量广播错误、索引检索边界条件等典型故障模式。每条样本均包含真实的pytest运行错误追踪、故障层级分类(语法/运行时/逻辑等)以及原始任务指令,使其天然适配DPO训练中的负样本配对需求。此外,该数据集采用与主版本一致的质量认证体系(v3.0架构),并承诺与所有先前发布的IDFU版本无样本重叠,购买多个版本可线性扩充训练数据规模。
使用方法
数据集以JSONL和Parquet格式提供,可通过Python的标准pandas库或HuggingFace datasets库直接加载。典型应用场景包括训练专用于向量检索库(如Faiss、ScaNN)的代码缺陷分类器,或作为DPO微调中的拒绝侧数据,指导模型规避常见的IVF、HNSW及乘积量化实现陷阱。使用时需注意,IDFU数据集仅提供负样本,需配合用户自有正向样本以实现完整对比学习。购买前可访问HuggingFace仓库中的10条免费预览样本及涵盖19个领域的100条通用预览进行充分评估。
背景与挑战
背景概述
IDFU Vector Search Specialty Pack 数据集由 namakoo 团队创建,专注于向量搜索内部机制与乘积量化算法的 Python 代码缺陷检测,于近期在 HuggingFace 平台发布。该数据集旨在为检索增强生成(RAG)与向量搜索工程师提供低成本的试验性训练数据,通过 82 个高质量样本覆盖乘积量化训练失败、高维向量形状不匹配及索引检索边缘用例等关键缺陷模式。其背景源于代码生成模型在向量数据库客户端代码(如 Faiss、ScaNN)中频繁产生产品级错误,亟需领域专用的负样本数据集以提升下游任务的鲁棒性。
当前挑战
该数据集的核心挑战在于解决向量搜索领域代码缺陷的多样性与隐蔽性,包括索引错误、聚类边界异常及维度调度失误等真实运行时故障,这些错误在传统代码数据集(如 HumanEval)中鲜少覆盖。构建过程中,团队面临样本去重与质量验证的难题:通过 AST 规范化哈希去除仅风格差异的重复样本,并利用容器化 Python 执行与 pytest 测试框架捕获真实的执行失败日志,而非依赖 LLM 模拟的伪错误。此外,数据集以低容量(82 样本)作为切入点,需在有限样本量下确保领域聚焦性与标注一致性,同时通过非重叠哈希保证与其他版本的数据互斥性,这对验证管道的严谨性提出了极高要求。
常用场景
经典使用场景
IDFU Vector Search Specialty Pack 数据集专注于向量搜索内部机制与乘积量化算法领域的Python代码失败样本,为检索增强生成(RAG)工程师和搜索系统开发者提供了低成本、高质量的入门级训练数据。该数据集最经典的使用场景包括训练RAG感知的错误分类器,用于在向量检索缺陷进入生产环境之前进行预警;作为DPO(直接偏好优化)训练中的被拒绝侧数据,用以抑制乘积量化、IVF、HNSW等索引算法实现中的常见陷阱;以及微调代码审查模型,专门针对Faiss、ScaNN、Annoy等向量数据库客户端代码的缺陷检测。每个样本均包含原始任务指令和真实的pytest执行日志,使得构建指令驱动的错误识别与修复模型成为可能。
实际应用
在实际工程中,该数据集主要服务于构建向量检索系统的可靠性保障工具链。RAG系统的开发者可以利用它训练专用的错误检测模型,在代码提交阶段自动拦截潜在的检索逻辑缺陷,减少线上事故。对于搜索引擎和推荐系统的运维团队,该数据集中覆盖的乘积量化算法实现错误模式可直接用于增强自动化测试套件,提升对高维向量索引边界情况的覆盖率。此外,代码审查工具可借此数据集微调,使其能够识别向量数据库客户端代码中的特定反模式,如不恰当的维度广播或空簇处理缺失。数据集的低样本量设计(82个样本)使得这些应用可以在单GPU上数小时内完成实验验证,降低了企业尝试新方法论的门槛。
衍生相关工作
该数据集作为IDFU代码失败数据集家族的一员,衍生出了多个相关的高价值工作。同系列的通用版本(v1、v2、v3)以2000样本覆盖19个领域,支持更大规模的代码缺陷研究。其他专项包如OFI/VPIN量化交易、CPython字节码和Transformer泛化领域,延续了相同的质检标准和数据模式,使得跨领域比较与迁移学习成为可能。此外,IDFU团队公开的DPO基准测试表明,在Monte Carlo领域使用500对样本对Qwen2.5-Coder-3B-Instruct进行微调,在HumanEval上取得了3.46个百分点的pass@1提升。这一结果虽然没有直接复制到向量搜索包,但为后续研究提供了方法学参考,催生了更多关于失败样本在代码偏好优化中作用机制的分析工作。
以上内容由遇见数据集搜集并总结生成


