LoraClassBalance
收藏Hugging Face2025-10-31 更新2025-11-01 收录
下载链接:
https://huggingface.co/datasets/ngtranai09/LoraClassBalance
下载链接
链接失效反馈官方服务:
资源简介:
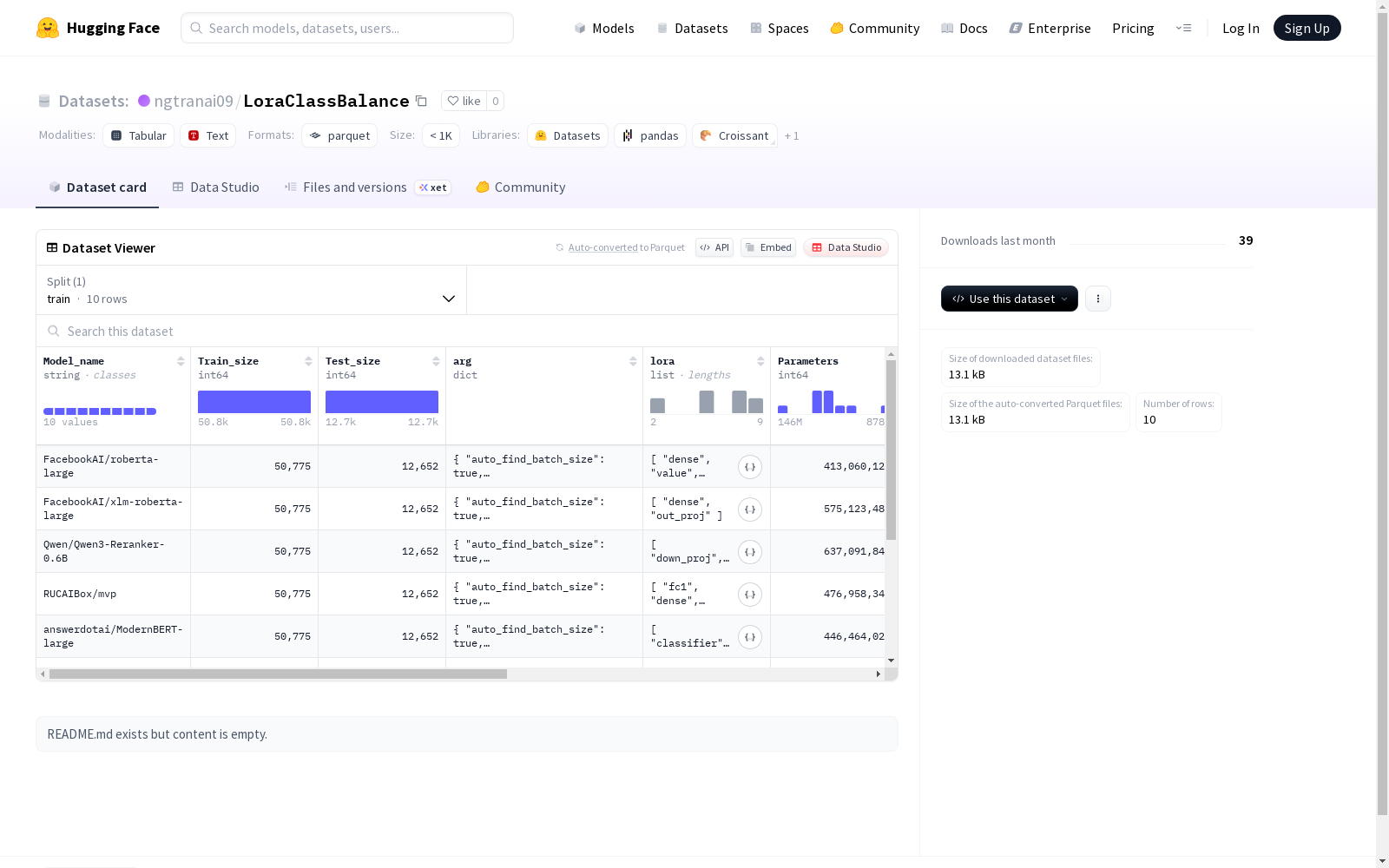
该数据集包含了模型的名称、训练集和测试集的大小、超参数设置、训练性能指标等信息。数据集分为训练集,大小为10个样本,总计占用2838字节。数据集下载大小为13071字节。
创建时间:
2025-10-31
原始信息汇总
LoraClassBalance数据集概述
数据集基本信息
- 数据集名称:LoraClassBalance
- 总大小:2,838字节
- 下载大小:13,071字节
- 训练集样本数量:10个
数据结构特征
- Model_name:字符串类型
- Train_size:整型
- Test_size:整型
- arg:结构体类型,包含以下字段:
- auto_find_batch_size:布尔型
- gradient_accumulation_steps:整型
- learning_rate:浮点型
- logging_steps:整型
- lr_scheduler_type:字符串型
- num_train_epochs:整型
- output_dir:字符串型
- report_to:字符串型
- save_strategy:字符串型
- save_total_limit:整型
- seed:整型
- warmup_steps:整型
- weight_decay:浮点型
- lora:字符串序列
- Parameters:整型
- Trainable_parameters:整型
- r:整型
- Memory Allocation:字符串型
- Training Time:字符串型
- Performance:结构体类型,包含以下指标:
- accuracy:浮点型
- f1_macro:浮点型
- f1_weighted:浮点型
- precision:浮点型
- recall:浮点型
数据配置
- 配置名称:default
- 数据文件路径:data/train-*
搜集汇总
数据集介绍
构建方式
在机器学习模型优化领域,LoraClassBalance数据集通过系统化的实验设计构建而成。该数据集整合了多种模型配置与训练参数,记录了包括模型名称、训练与测试规模、超参数设置及性能指标在内的结构化信息。构建过程注重参数调优与性能评估的协同,确保了数据在模型比较与分析中的科学性与一致性。
特点
LoraClassBalance数据集展现出高度的多维特征集成能力,其结构涵盖模型架构、训练动态及评估指标等多个维度。特征字段如LoRA配置、内存分配和训练时间等,为研究低秩适应技术与分类平衡问题提供了丰富视角。数据集的紧凑设计与性能指标的全面性,使其成为探索高效模型微调与资源优化的理想载体。
使用方法
针对模型开发与实验分析,LoraClassBalance数据集支持直接加载与参数解析,便于研究者复现训练流程或进行跨模型比较。用户可通过配置名称调用默认数据分割,利用训练规模、超参数和性能指标等字段,深入探究不同设置对分类准确性与效率的影响。该数据集适用于机器学习工作流的基准测试与参数敏感性分析。
背景与挑战
背景概述
随着低秩自适应(LoRA)技术在自然语言处理领域的广泛应用,模型微调过程中的类别不平衡问题逐渐凸显。LoraClassBalance数据集由研究机构针对这一核心问题构建,旨在系统评估不同LoRA配置对类别分布不均数据的适应能力。该数据集通过整合多种预训练模型架构与动态训练参数,为研究稀疏参数微调机制下的泛化性能提供了标准化基准,显著推动了高效迁移学习范式的理论发展与实践验证。
当前挑战
在解决文本分类任务中的类别不平衡问题时,LoRA微调方法需应对长尾分布导致的少数类识别精度衰减挑战。数据集构建过程中面临多维度协调困难:需精确控制不同模型架构的LoRA秩参数与训练超参数的组合空间,同时确保内存分配与计算效率的平衡。此外,性能指标的多目标优化要求同步提升准确率与宏F1分数,这对参数空间的采样策略与评估框架设计提出了极高要求。
常用场景
经典使用场景
在机器学习领域,LoraClassBalance数据集主要应用于研究低秩自适应(LoRA)方法在类别不平衡场景下的表现。该数据集通过记录不同模型在特定训练配置下的性能指标,为研究者在参数高效微调领域提供了标准化的评估基准。其精心设计的特征结构使得研究者能够系统分析LoRA超参数对模型性能的影响,特别是在处理类别分布不均的数据时展现出独特价值。
实际应用
在实际部署中,LoraClassBalance数据集为开发资源受限的智能应用提供了重要参考。企业可利用该数据集指导在边缘设备上部署语言模型时的参数调优,特别是在处理用户生成内容中常见的类别不均衡问题时。其记录的训练时间与内存分配数据,直接助力于优化实际生产环境中的计算资源分配策略。
衍生相关工作
基于该数据集的研究催生了多项参数高效微调领域的创新工作。学者们利用其提供的标准化评估框架,发展了新型的类别平衡自适应算法,并在持续学习、领域自适应等方向取得突破。这些衍生研究进一步拓展了LoRA方法在多媒体内容分析、智能客服等实际场景中的应用边界,形成了完整的技术演进脉络。
以上内容由遇见数据集搜集并总结生成


