omniASR-igbo-blindspots
收藏omniASR Igbo 盲点数据集概述
数据集基本信息
- 语言: 伊博语 (ig)
- 许可证: CC-BY-4.0
- 任务类别: 自动语音识别
- 标签: 非洲语言、低资源语言、声调语言、ASR偏见、模型评估、伊博语
- 规模类别: n<1K
研究问题
本数据集探讨了关于多语言ASR在声调语言性能上的三个相互关联的问题:
- 操作定义: 当一个模型声称支持1600多种语言时,“语言支持”意味着什么?覆盖范围是否意味着在语言学的有意义的区分上具有功能性的准确度?
- 诊断有效性: 声调变音符号的保留能否作为低资源语言中声学能力与正字法模式匹配的诊断指标?
- 系统性评估: facebook/omniASR-CTC-1B模型在伊博语中是否表现出系统性的声调塌缩?如果是,会出现哪些错误模式?
数据集概述
本数据集提供了一个受控的诊断性评估,用于评估facebook/omniASR-CTC-1B模型在处理伊博语(ibo_Latn)时的声调保真度。伊博语是一种声调的尼日尔-刚果语系语言,拥有约4500万使用者。通过21个系统性设计的音频样本,我们记录了在声调标记上75.5%的变音符号丢失率(bootstrap 95% CI: [57.1%, 89.7%];基于话语级别重采样的bootstrap均值估计;原始聚合计数:30/49 = 61.2%),并提供了与概率性变音符号生成而非稳健的声学条件反射相一致的证据。
关键发现: 该模型在声调标记上表现出75.5%的变音符号丢失率,无法区分声调最小对立对,并且反常地在单一声调语音上幻觉生成变音符号。
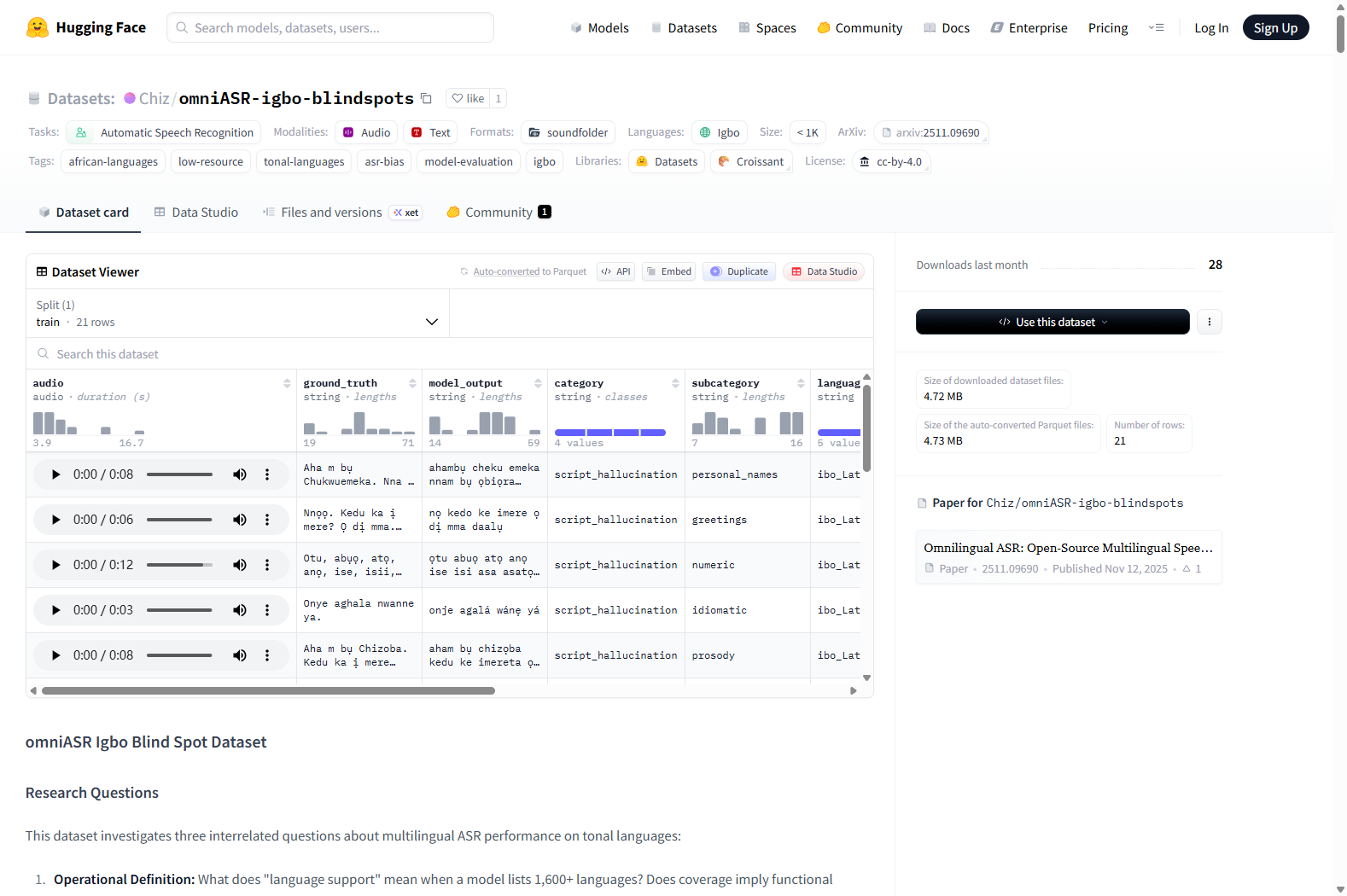
数据集结构
huggingface_dataset/ ├── audio/ # 21个WAV文件 (16kHz 单声道) ├── metadata.csv # 真实标签、模型输出、错误指标 └── README.md # 说明文件
元数据模式
| 列名 | 描述 |
|---|---|
file_name |
音频文件路径 |
ground_truth |
带有声调标记的正确转录 |
model_output |
omniASR-CTC-1B的预测结果 |
category |
错误类别(见下文分类) |
subcategory |
具体的测试条件 |
language |
语言代码 (ibo_Latn, yor_Latn, fra_Latn, mixed) |
character_error_rate |
字符级错误率 (0-1) |
diacritics_expected |
真实标签中的声调标记数量 |
diacritics_produced |
模型输出中的声调标记数量 |
diacritic_loss |
变音符号净差值(负值表示幻觉生成) |
错误分类与发现
1. 跨语言正字法干扰(5个样本)
假设: 模型将其他语言的不正确正字法惯例应用于伊博语文本。 发现: 模型经常在不存在的地方添加不正确的变音符号(-38.9%的净变音符号丢失率 = 38.9%的幻觉生成率),表明存在来自其他支持语言的跨语言干扰。
2. 音位声调敏感性(6个样本)
假设: 模型无法区分伊博语中具有音位对比性的声调。 发现:
- 75.5%的变音符号丢失率(bootstrap估计;原始计数:30/49个声调标记)
- Bootstrap 95% CI: [57.1%, 89.7%]
- 在单一声调语音上CER为74.4%,而模型添加了不存在的声调
- 模型输出将多个声调最小对立对形式塌缩为一个共享的正字法表示,表明在此评估设置中声调可分离性较弱
3. 语言边界效应(5个样本)
假设: 英语-伊博语语码转换(在尼日利亚语音中极为常见)扰乱了语言特定的处理。 发现: 14.3%的变音符号丢失率。英语部分转录完美,而相邻的伊博语丢失了声调标记(例如,“The ụlọ is beautiful” → “te ulọ is beautiful”),表明语言检测边界影响了正字法保真度。
4. 领域特定词汇覆盖(5个样本)
假设: 模型难以处理训练分布之外的文化特定术语、地名和惯用表达。 发现:
- 最佳的变音符号保留率(6.3%丢失率),但词级错误率高(30% CER)
- 地名被破坏:“Owerri” → “weri”(音节缺失)
- 高资源语言法语表现意外地差(捷克/斯拉夫字符幻觉生成)
定量总结
| 类别 | 样本数 | 变音符号丢失率 | 平均CER |
|---|---|---|---|
| 音位声调敏感性 | 6 | 75.5% | 50.6% |
| 跨语言正字法干扰 | 5 | -38.9% (幻觉生成) | 28.8% |
| 领域特定词汇覆盖 | 5 | 6.3% | 30.1% |
| 语言边界效应 | 5 | 14.3% | 20.0% |
| 总计 | 21 | 26.8% | 32.5% |
统计分析
- 原始变音符号丢失率 (RDD): 音位声调敏感性类别的原始丢失计数为30/49,原始RDD为61.2%。
- 变音符号错误率 (DER): 总体DER为26.8%,音位声调敏感性DER为75.5%。
- Bootstrap不确定性估计:
- 音位声调敏感性:Bootstrap平均DER为75.5%,95% CI: [57.1%, 89.7%]
- 总体变音符号丢失率(仅丢失):Bootstrap平均RDD为52.6%,95% CI: [30.3%, 69.7%]
- 字符错误率 (CER):总体CER为0.333,95% CI: [0.267, 0.402]
关键音频示例
06_tonal_akwa.wav- 声调最小对立对(4个不同的词塌缩为随机输出)09_tonal_flat.wav- 带有幻觉生成变音符号的单一声调语音11_codesw_en2ig.wav- 语码转换(英语完美,伊博语丢失声调)
性能差距:声称 vs. 实测
- Meta的omnilingual ASR论文声称:omniASR在78%的支持语言上实现CER <10%,伊博语(ibo_Latn)被列为1600多种支持语言之一。
- 本数据集发现:
- 总体CER: 32.5%(比声称阈值差3.25倍)
- 声调类别CER: 50.6%(比声称阈值差5倍)
- 最差样本CER: 74.4%(比声称阈值差7.4倍)
使用案例
本数据集设计用于:
- ASR开发者: 为非洲语言进行声调准确性的基准测试