SSA-MTE
收藏Hugging Face2025-07-22 更新2025-07-23 收录
下载链接:
https://huggingface.co/datasets/McGill-NLP/SSA-MTE
下载链接
链接失效反馈官方服务:
资源简介:
SSA-MTE是一个大规模人工注释的多语言翻译评估数据集,包含多种非洲语言的翻译数据,用于评估机器翻译质量,特别是针对资源匮乏的非洲语言。
提供机构:
McGill NLP Group
创建时间:
2025-07-22
原始信息汇总
SSA-MTE 数据集概述
基本信息
- 数据集名称: ssa-mte
- 许可证: cc-by-sa-4.0
- 多语言支持: 是
- 语言列表:
- 英语 (en)
- 法语 (fr)
- 葡萄牙语 (pt)
- 阿姆哈拉语 (am)
- 豪萨语 (ha)
- 基库尤语 (ki)
- 卢旺达语 (rw)
- 伊博语 (ig)
- 约鲁巴语 (yo)
- 尼扬贾语 (ny)
- 卢奥语 (luo)
- 特威语 (tw)
- 约鲁巴语 (yor)
- 埃维语 (ee)
- 祖鲁语 (zu)
- 林加拉语 (lin)
- 沃洛夫语 (wo)
- 埃马库瓦语 (vmw)
- 斯瓦希里语 (sw)
- 塞索托语 (sot)
- 数据规模: 1M < n < 10M
- 标签: news-topic
数据集配置
- eng-amh: 阿姆哈拉语
- 训练集: train/Amharic.json
- 验证集: dev/Amharic.json
- eng-hau: 豪萨语
- 训练集: train/Hausa.json
- 验证集: dev/Hausa.json
- eng-ibo: 伊博语
- 训练集: train/Igbo.json
- 验证集: dev/Igbo.json
- eng-kik: 基库尤语
- 训练集: train/Kikuyu.json
- 验证集: dev/Kikuyu.json
- eng-kin: 卢旺达语
- 训练集: train/Kinyarwanda.json
- 验证集: dev/Kinyarwanda.json
- eng-luo: 卢奥语
- 训练集: train/Luo.json
- 验证集: dev/Luo.json
- eng-twi: 特威语
- 训练集: train/Twi.json
- 验证集: dev/Twi.json
- eng-yor: 约鲁巴语
- 训练集: train/Yoruba.json
- 验证集: dev/Yoruba.json
- eng-zul: 祖鲁语
- 训练集: train/Zulu.json
- 验证集: dev/Zulu.json
- fra-ewe: 埃维语
- 训练集: train/Ewe.json
- 验证集: dev/Ewe.json
- fra-lin: 林加拉语
- 训练集: train/Lingala.json
- 验证集: dev/Lingala.json
- fra-wol: 沃洛夫语
- 训练集: train/Wolof.json
- 验证集: dev/Wolof.json
- por-nya: 尼扬贾语
- 训练集: train/Nyanja.json
- 验证集: dev/Nyanja.json
- por-vwm: 埃马库瓦语
- 训练集: train/Emakhuwa.json
- 验证集: dev/Emakhuwa.json
- eng-swa: 斯瓦希里语
- 训练集: train/Swahili.json
- 验证集: dev/Swahili.json
- eng-sot: 塞索托语
- 训练集: train/Sesotho.json
- 验证集: dev/Sesotho.json
相关论文
- 标题: SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?
- 链接: https://arxiv.org/abs/2506.04557
搜集汇总
数据集介绍
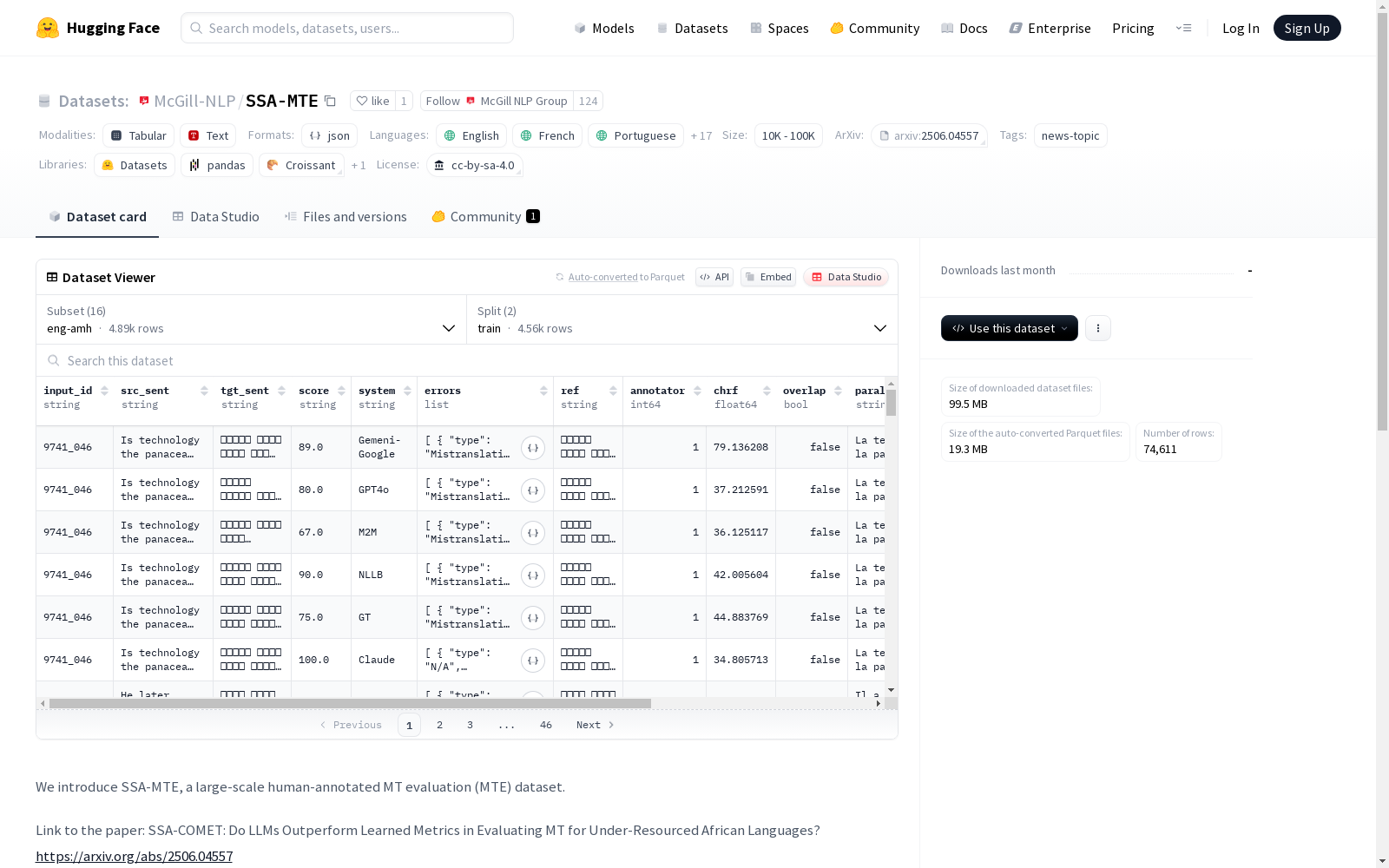
构建方式
在机器翻译评估领域,SSA-MTE数据集通过专家人工标注的方式构建,涵盖了16种非洲语言与英语、法语、葡萄牙语之间的翻译对。该数据集源自原创数据,采用严格的质控流程,其中4种语言的原始数据因未通过质量检验正在进行二次筛选。数据规模介于100万到1000万条之间,遵循CC-BY-SA 4.0许可协议,体现了对非洲低资源语言研究的特殊考量。
使用方法
研究者可通过HuggingFace平台按语言对配置名称(如eng-amh)直接调用特定语种的训练集和验证集。该数据集专为机器翻译质量评估任务设计,建议结合配套论文SSA-COMET中提出的评估框架使用。对于暂未发布的4个语种数据,用户可关注后续更新公告获取经过二次筛选的高质量版本。使用时需注意遵守CC-BY-SA 4.0协议要求,并合理考虑非洲语言特有的语言学特征。
背景与挑战
背景概述
SSA-MTE数据集是一项针对非洲低资源语言机器翻译评估(MTE)的大规模人工标注数据集,由研究团队于2024年发布,相关成果发表于论文《SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?》。该数据集涵盖了包括阿姆哈拉语、豪萨语、约鲁巴语等16种非洲语言,旨在解决非洲语言在机器翻译领域数据稀缺、评估标准缺失的核心问题。其多语言特性与专家标注机制为非洲语言自然语言处理研究提供了重要基准,显著提升了低资源语言在机器翻译质量评估领域的可见度。
当前挑战
SSA-MTE面临双重挑战:在领域问题层面,非洲语言普遍存在形态复杂、方言变体多样等语言学特性,传统评估指标难以准确捕捉其翻译质量差异;低资源语言缺乏平行语料库,导致评估模型易受数据偏差影响。在构建过程中,部分语种(如斯瓦希里语、祖鲁语等)因标注一致性不足需二次过滤,凸显了多语言标注质量控制难题;同时,小语种专业标注人才稀缺,专家标注成本与数据规模平衡成为关键制约因素。
常用场景
经典使用场景
在机器翻译研究领域,SSA-MTE数据集为评估非洲低资源语言的翻译质量提供了重要基准。该数据集覆盖16种非洲语言与英语、法语、葡萄牙语之间的翻译对,通过专家标注的翻译质量评分,成为训练和验证神经机器翻译模型的黄金标准。尤其在跨语言迁移学习和多语言模型优化中,研究者通过该数据集可系统分析语言结构差异对翻译性能的影响。
解决学术问题
该数据集有效解决了低资源语言机器翻译评估中标注数据匮乏的核心难题。传统评估方法在非洲语言中面临语义对齐模糊、文化特定表达缺失等挑战,SSA-MTE通过严谨的人工标注体系,为建立语言无关的自动评估指标(如COMET)提供数据支撑。其包含的韵律特征标注更推动了音系学感知的翻译质量研究。
实际应用
在非洲地区多语言信息服务平台建设中,SSA-MTE支持开发高精度的新闻资讯翻译系统。联合国机构利用该数据集优化了豪萨语与法语的灾害预警信息互译,尼日利亚媒体则基于约鲁巴语翻译模块实现地方新闻的自动化传播。数据集特有的文化负载词标注方案,显著提升了医疗信息本地化翻译的准确性。
数据集最近研究
最新研究方向
在低资源语言机器翻译评估领域,SSA-MTE数据集正成为研究焦点。该数据集覆盖16种非洲语言,填补了传统评估方法在非洲语言上的空白。最新研究聚焦于探索大语言模型(LLMs)在低资源语言翻译评估中的表现,如SSA-COMET论文所探讨的LLMs与传统学习型评估指标的对比。随着非洲数字化进程加速,该数据集为提升机器翻译在本地化应用中的质量提供了关键基准。当前研究还关注如何通过数据过滤提升斯瓦希里语等语言的标注质量,以应对低资源语言数据稀疏的挑战。
以上内容由遇见数据集搜集并总结生成


