ManaTTS
收藏arXiv2024-09-11 更新2024-09-13 收录
下载链接:
https://huggingface.co/datasets/MahtaFetrat/Mana-TTS
下载链接
链接失效反馈官方服务:
资源简介:
ManaTTS是一个公开可访问的单说话人波斯语语料库,由沙里夫理工大学计算机工程系创建。该数据集包含约86小时的音频,采样率为44.1 kHz,涵盖24113个独特词汇,涉及多种主题领域。数据集的创建过程包括从Nasl-e-Mana杂志网站爬取数据,并通过一系列处理步骤生成音频-文本对。ManaTTS旨在为低资源语言提供高质量的文本到语音转换工具,解决波斯语领域中缺乏高质量开源TTS模型的挑战。
ManaTTS is a publicly accessible single-speaker Persian corpus created by the Department of Computer Engineering at Sharif University of Technology. This dataset contains approximately 86 hours of audio with a sampling rate of 44.1 kHz, covering 24,113 unique vocabulary items and spanning multiple thematic domains. The dataset creation process involves scraping data from the Nasl-e-Mana magazine website and generating audio-text pairs through a series of processing steps. ManaTTS aims to provide high-quality Text-to-Speech (TTS) tools for low-resource languages, addressing the challenge of the scarcity of high-quality open-source TTS models in the Persian language field.
提供机构:
沙里夫理工大学计算机工程系
创建时间:
2024-09-11
原始信息汇总
ManaTTS Persian: 低资源语言TTS数据集创建方案
数据集概述
Mana-TTS 是一个全面且大规模的波斯语文本到语音(TTS)数据集,专为语音合成和其他语音相关任务设计。该数据集经过精心收集、处理和注释,以确保高质量的数据用于训练TTS模型。
数据来源
原始音频和文本文件来自 Nasl-e-Mana 杂志,该杂志致力于为盲人服务。
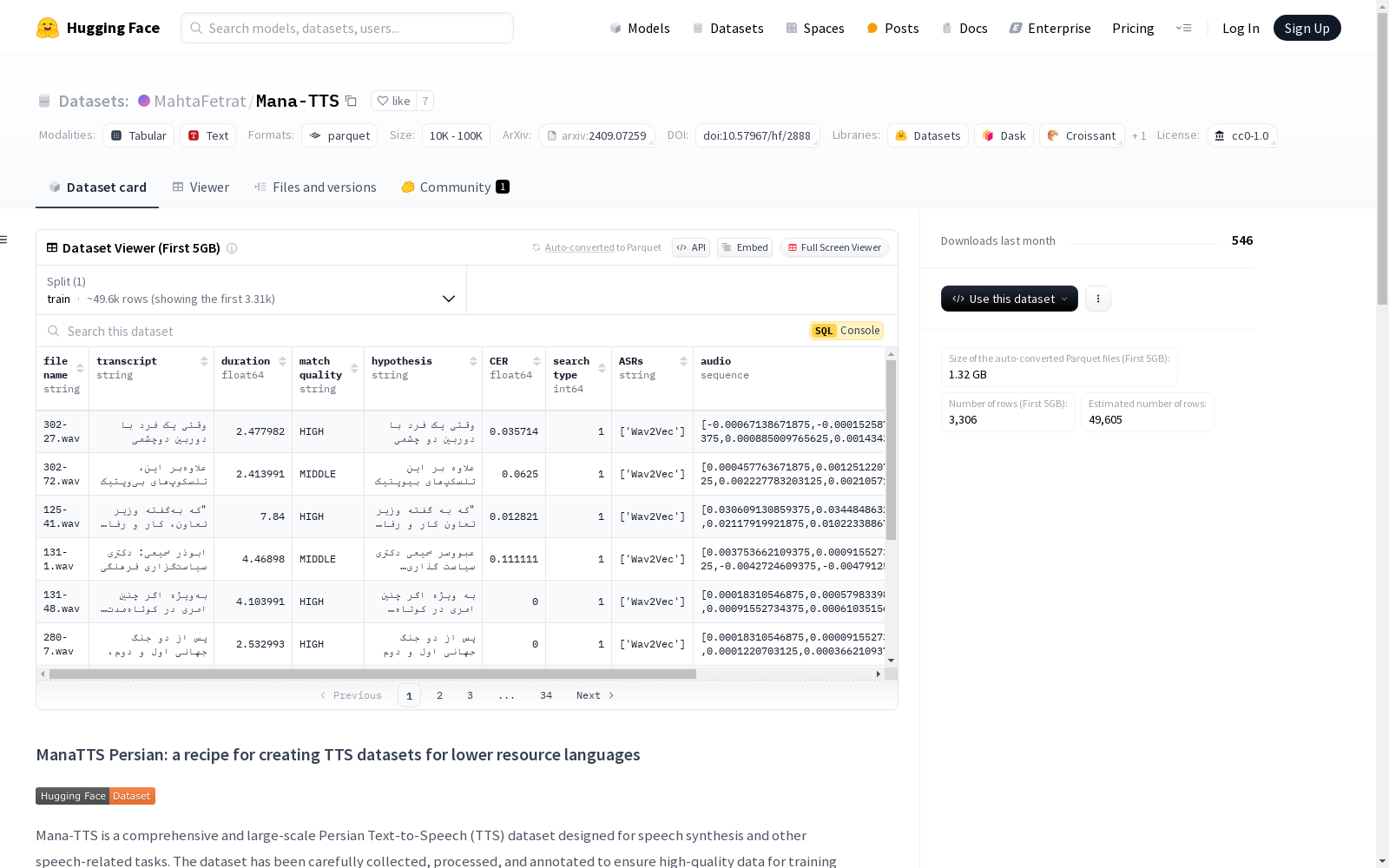
数据列
每个 Parquet 文件包含以下列:
- file name (
string): 音频文件的唯一标识符。 - transcript (
string): 对应音频的地面真值转录。 - duration (
float64): 音频文件的时长(秒)。 - match quality (
string): 匹配质量,"HIGH" 表示CER < 0.05,"MIDDLE" 表示0.05 < CER < 0.2。 - hypothesis (
string): 由ASR生成的最佳转录假设。 - CER (
float64): 地面真值和假设转录之间的字符错误率(CER)。 - search type (
int64): 搜索类型,1表示间隔搜索结果,2表示间隙搜索结果。 - ASRs (
string): 用于找到满意匹配转录的自动语音识别(ASR)系统。 - audio (
sequence): 实际音频数据。 - samplerate (
float64): 音频的采样率。
使用方法
可以通过 Hugging Face datasets 库直接加载数据集: python from datasets import load_dataset
dataset = load_dataset("MahtaFetrat/Mana-TTS", split=train)
也可以下载特定部分或整个数据集: bash
下载特定部分
wget https://huggingface.co/datasets/MahtaFetrat/Mana-TTS/resolve/main/dataset/dataset_part_01.parquet
下载整个数据集
git clone https://huggingface.co/datasets/MahtaFetrat/Mana-TTS
引用
如果使用 Mana-TTS 进行研究或项目,请引用以下论文:
TO BE UPDATED
许可证
该数据集在 cc0-1.0 许可证下可用。然而,该数据集不应被用于恶意目的或不道德活动,包括恶意意图的语音克隆。
搜集汇总
数据集介绍
构建方式
ManaTTS Persian数据集的构建始于对Nasl-e-Mana杂志的音频和文本资料的爬取。这些资料经过预处理,包括音频格式转换和背景音乐移除,以及文本文件的规范化、链接和参考文献的去除、数字的口语化处理等。接下来,通过一个基于自动语音识别(ASR)模型的自适应对齐模块进行音频和文本的匹配。该模块利用多个ASR模型生成候选转录本,并通过多数投票和长度筛选确保转录的准确性。对齐后的音频和文本被分割成更小的片段,以便用于文本到语音(TTS)模型的训练。
使用方法
使用ManaTTS Persian数据集时,首先需要下载并安装必要的开源工具和库。然后,可以按照数据集提供的处理流程,对原始的音频和文本文件进行预处理、对齐和分割。对齐后的数据片段可以直接用于训练TTS模型。数据集还提供了一个基于Tacotron2的TTS模型的训练示例,该模型在ManaTTS数据集上取得了3.76的平均意见得分(MOS),与使用相同声码器和自然频谱图生成的语音的MOS 3.86非常接近,并且与自然波形生成的MOS 4.01相比也表现出色。数据集的开放性和可扩展性使得它非常适合用于波斯语TTS模型的研究和开发。
背景与挑战
背景概述
语音合成技术,即文本到语音(TTS)转换,长期以来一直是人工智能领域的一个重要研究方向。它不仅在导航系统、在线教育和内容提供等方面得到广泛应用,更重要的是为视障人士提供阅读辅助,将电子设备屏幕上的文字内容转换为可听的语音。然而,高质量的波斯语TTS模型和数据的缺乏限制了这一技术在波斯语用户群体中的应用。ManaTTS数据集的创建旨在解决这一问题,它提供了一个包含约86小时音频的大型单发音人波斯语语料库,并配备了一个用于收集波斯语语音转写数据集的全面框架。该数据集以开放的CC-0许可证发布,为教育、研究和商业用途提供了便利。ManaTTS数据集的发布不仅填补了波斯语TTS数据集的空白,而且通过其高质量、大规模和开放性的特点,为波斯语语音合成研究提供了宝贵资源。
当前挑战
尽管ManaTTS数据集为波斯语TTS研究做出了重要贡献,但仍存在一些挑战。首先,现有的波斯语TTS数据集通常规模较小、质量较低,且限于特定领域,这限制了模型的泛化能力。其次,构建高质量TTS数据集需要解决语音和文本之间的对齐问题,特别是在低资源语言中。ManaTTS数据集通过集成多个自动语音识别(ASR)模型并实施多数投票机制,有效缓解了这一问题。此外,由于英语的普遍性,波斯语文本中可能包含英语单词和短语,而ManaTTS数据集的构建流程尚未考虑这一点。最后,对于特定格式的数字和符号的语音和书面形式的匹配,数据集中仍存在一些挑战。为了应对这些挑战,未来的研究需要进一步提高ASR模型的准确性,并探索新的文本处理工具,以更好地处理跨语言和特定格式的数据。
常用场景
经典使用场景
ManaTTS Persian数据集主要用于训练文本到语音(TTS)模型,尤其是在波斯语这种低资源语言中。由于该数据集的规模和质量,它成为了波斯语TTS研究的重要资源。此外,ManaTTS数据集还被用于评估语音识别(ASR)模型,尤其是在强制对齐任务中。
解决学术问题
ManaTTS数据集解决了波斯语TTS领域的一个关键问题,即缺乏高质量、开源和可访问的TTS数据集。现有的波斯语TTS数据集要么不可访问,要么缺乏明确的许可证,或者受到限制。ManaTTS数据集的发布填补了这一空白,为研究人员和开发者提供了宝贵的数据资源,以推动波斯语TTS技术的发展。
实际应用
ManaTTS数据集的实际应用场景包括开发波斯语语音助手、语音合成工具和辅助技术,以帮助有视觉障碍的人士。此外,该数据集还可以用于开发波斯语自动语音识别(ASR)系统,从而实现语音到文本的转换,为各种应用程序和场景提供支持。
数据集最近研究
最新研究方向
ManaTTS Persian数据集的推出填补了波斯语TTS领域的空白,为低资源语言的语音合成提供了宝贵的资源。该数据集不仅规模庞大,而且质量高,为训练高质量的TTS模型提供了可能。此外,ManaTTS Persian的开放性和可扩展性也为未来的研究提供了便利。目前,该数据集已被用于训练Tacotron2-based的TTS模型,并取得了令人满意的MOS评分。未来,ManaTTS Persian有望在低资源语言TTS领域发挥更大的作用,推动该领域的研究和应用发展。
相关研究论文
- 1ManaTTS Persian: a recipe for creating TTS datasets for lower resource languages沙里夫理工大学计算机工程系 · 2024年
以上内容由遇见数据集搜集并总结生成


