lance-format/textvqa-lance
收藏Hugging Face2026-05-08 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/lance-format/textvqa-lance
下载链接
链接失效反馈官方服务:
资源简介:
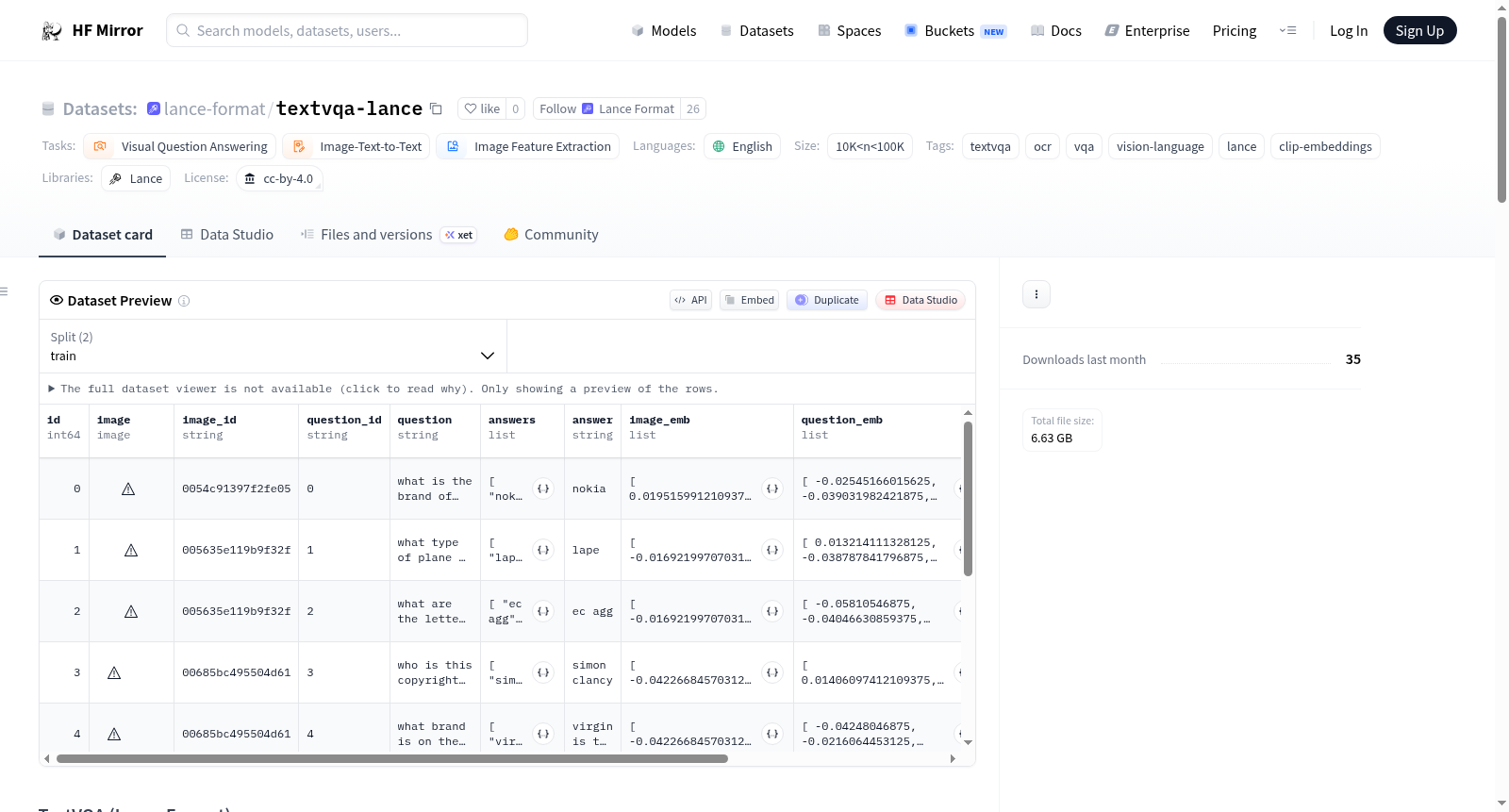
TextVQA(Lance格式)是TextVQA数据集的Lance格式版本,主要用于视觉问答任务,要求模型能够阅读图像中的文本。数据集包含图像字节、问题、10个参考答案、OCR识别的文本标记以及CLIP图像和问题嵌入。数据集分为训练集(34,602行)和验证集(5,000行)。提供了详细的列描述和预构建的索引,支持跨模态文本→图像搜索。数据集采用CC BY 4.0许可证,由Singh等人(Facebook AI Research)发布。
TextVQA (Lance Format) is a Lance-formatted version of the TextVQA dataset, designed for visual question answering tasks that require reading text in the image. The dataset includes image bytes, questions, 10 reference answers, OCR tokens detected on the image, and CLIP image and question embeddings. It is divided into training (34,602 rows) and validation (5,000 rows) splits. The dataset provides detailed column descriptions and pre-built indices, supporting cross-modal text→image search. It is released under CC BY 4.0 by Singh et al. (Facebook AI Research).
提供机构:
lance-format
搜集汇总
数据集介绍
构建方式
TextVQA-Lance数据集是基于原始TextVQA数据集进行格式转换与功能增强的版本。原始TextVQA由Singh等人于2019年提出,聚焦于需要图像中文字阅读能力的视觉问答任务。本数据集从HuggingFace上的`lmms-lab/textvqa`仓库获取原始数据,采用Lance列式存储格式重新组织,将图像字节、问题文本、10个参考答案、OCR检测令牌以及通过OpenCLIP模型提取的图像与问题嵌入向量整合为单一文件。数据划分为训练集(34,602行)与验证集(5,000行),并预构建了IVF_PQ索引、倒排索引(FTS)和B树索引,分别支持嵌入相似性搜索、全文检索与元数据查询。
特点
该数据集的核心优势在于其多模态信息的高度集成与索引优化。每条记录不仅包含原始图文对与问答标注,还附带经OpenCLIP ViT-B-32模型计算并余弦归一化的512维图像嵌入与问题嵌入,可直接用于跨模态检索。预构建的IVF_PQ索引大幅加速了基于嵌入向量的最近邻搜索,而倒排索引则支持对问题与答案文本的快速全文匹配。Lance格式支持模式演化,允许用户在不重写整个数据集的情况下添加新列(如替代OCR结果或模型预测),兼顾了扩展性与查询效率。此外,数据集的OCR令牌字段为文本驱动过滤提供了天然支持。
使用方法
用户可通过Lance Python库便捷地加载与查询数据集。使用`lance.dataset()`函数从HuggingFace路径直接读取训练或验证分片,支持行数统计、模式查看与索引列表获取。对于跨模态文本到图像搜索任务,需利用OpenCLIP模型将查询文本编码为归一化向量,再通过`scanner`方法的`nearest`参数指定图像嵌入列与目标向量,即可返回Top-K相似结果。此外,依托预构建的倒排索引,用户可基于问题或答案字段执行高效的全文搜索;B树索引则支持按图像ID、问题ID或集合名称进行精确查找。
背景与挑战
背景概述
TextVQA-Lance数据集由Facebook AI Research的研究人员于2019年创建,旨在推动视觉问答领域向更高阶的文本理解能力迈进。核心研究问题聚焦于构建能够阅读并理解图像中文字信息的视觉问答模型,这与传统VQA任务主要依赖物体识别和场景理解形成鲜明对比。该数据集包含近四万张图像,每张图像附有手工标注的问题、十个参考答案以及预处理的OCR令牌,覆盖了广告牌、路标、菜单等真实场景中的文字阅读需求。作为TextVQA的高效变体,TextVQA-Lance通过Lance格式整合了图像像素、文本标注和CLIP嵌入,显著降低了跨模态检索和模型训练的存储与计算开销,为图像文本交互研究树立了新的数据范式标准。
当前挑战
TextVQA-Lance解决的领域挑战在于突破传统VQA模型对图像中文字信息的盲区——现有模型常因无法准确识别或理解场景文字而答案错误,该任务要求模型同时具备OCR精度与语义推理能力。构建过程中的挑战体现为多模态数据的紧密耦合:需要将JPEG图像、JSON标注、OCR结果及CLIP嵌入统一存储于列式格式,并保持索引的一致性;此外,如何在不损失检索效率的前提下,对十万人规模的问答对实现跨模态混合搜索(如文本过滤与近邻检索的并行操作),也是工程实现中的核心难点。
常用场景
经典使用场景
TextVQA-Lance数据集专为视觉问答任务中需要理解图像内文字的场景而设计,其核心应用在于推动模型对视觉场景中文本感知与推理能力的发展。该数据集每一幅图像均附有自然语言问题、多个参考答案以及OCR预检测的文本令牌,研究者可借此训练模型在复杂视觉背景下识别并利用图中文字信息回答问题。经典用法涵盖基于CLIP嵌入的跨模态检索:通过将问题编码为文本嵌入,在图像嵌入空间中搜索最相关的图像,进而结合OCR令牌进行答案生成,为构建能够真正“读懂”图像文字的多模态系统提供了标准化评测基准。
实际应用
在真实部署场景中,TextVQA-Lance的应用覆盖了诸多依赖瞬时文字理解的智能系统。例如,在移动拍照翻译工具中,模型需根据用户拍摄的路牌或菜单图片响应“这是什么标志?”或“这道菜包含哪些成分?”等提问;在视障辅助导航中,系统通过读取商铺门头、交通指示牌的文字回答用户关于当前位置与方向的问题。此外,电商商品搜索亦受益于此:用户上传商品图片并询问“这包零食的热量是多少?”时,模型需精准定位图片中营养成分表的内容。这些应用均依赖训练于TextVQA-Lance的模型所具备的文字识别与语义应答能力。
衍生相关工作
基于TextVQA数据集,学术社区衍生出一系列值得关注的工作。Singh等人提出的原始TextVQA论文《Towards VQA Models that Can Read》首次定义了场景文字理解的任务框架,并建立了评估基准。其后,M4C模型采用多模态多步推理机制,融合OCR区域特征与注意力权重,显著提升了端到端问答准确率。TAP(Text-Aware Pre-training)方法则通过预训练文本感知视觉编码器,进一步增强了模型对图像中文字语义的捕获。这些工作均以TextVQA为测试平台,推动了从粗粒度视觉关联到细粒度文字推理的范式跃迁,也为后续工作如Lance格式下的高效双模态检索提供了重要的参考基线。
以上内容由遇见数据集搜集并总结生成


