urdu-ocr-1M
收藏Hugging Face2026-02-01 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/PuristanLabs1/urdu-ocr-1M
下载链接
链接失效反馈官方服务:
资源简介:
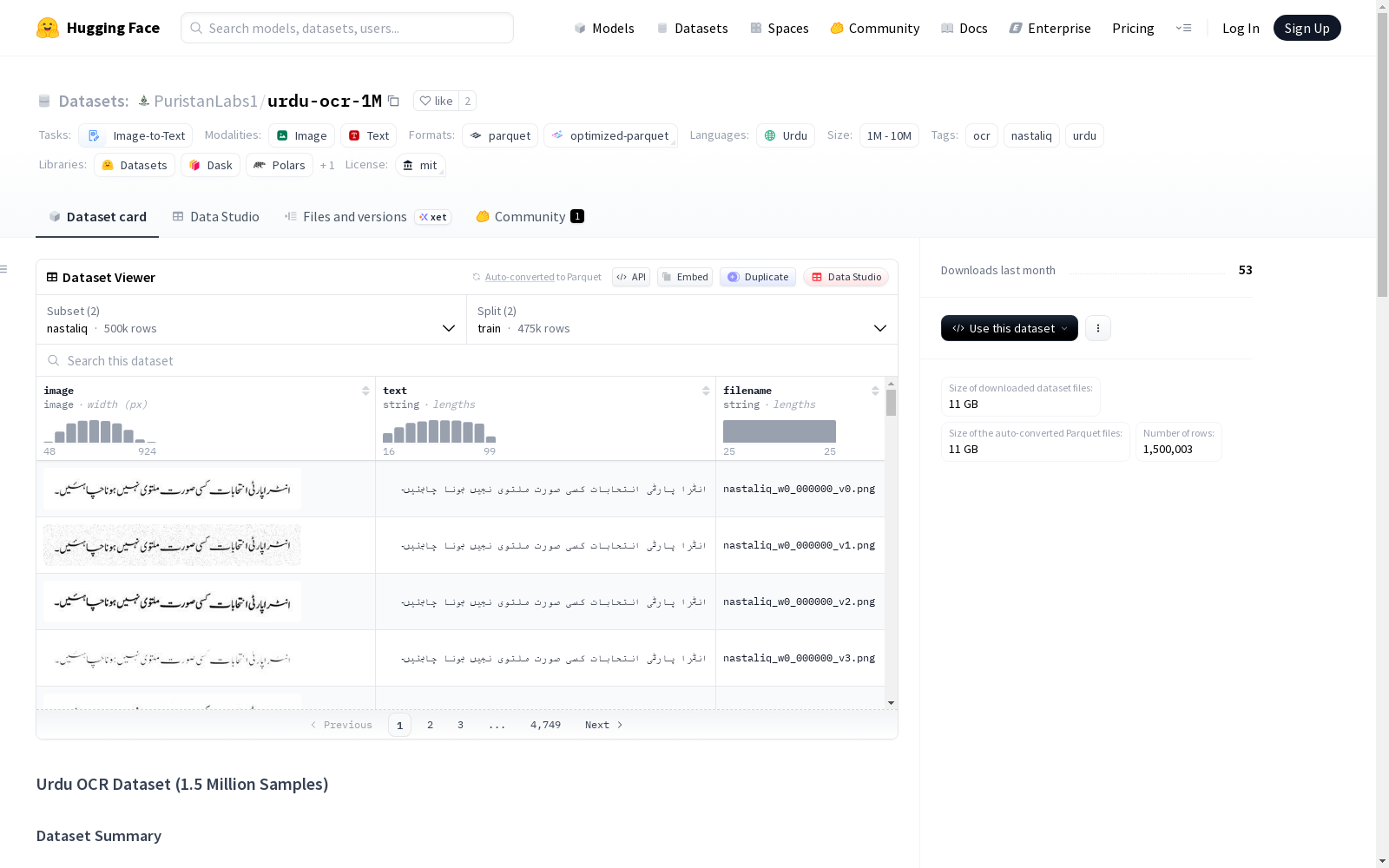
这是一个用于乌尔都语光学字符识别(OCR)的大规模合成数据集,包含突破性的Nastaliq集合和稳健的Naskh基础。数据集总共有150万个样本,其中Nastaliq部分包含约50万个样本,使用真实的Jameel Noori Nastaliq连字通过自定义的基于Chromium的渲染管道生成;Naskh部分包含1,000,160个样本,采用标准的乌尔都语字体用于基线OCR任务。数据集以优化的分片Parquet格式提供,支持高效流式处理。数据模式包括'image'(渲染的乌尔都语文本图像,高度标准化为64像素)、'text'(真实乌尔都语字符串)、'filename'(源文件和变体类型的引用)和'style'('nastaliq'或'naskh')。Nastaliq部分通过高保真渲染、手动质量控制和1:5的增强技术,模拟真实世界扫描文档的复杂性。数据集适用于图像到文本的任务,特别适用于乌尔都语OCR研究。
创建时间:
2026-01-29
原始信息汇总
Urdu OCR Dataset (1.5 Million Samples) 数据集概述
数据集摘要
这是一个用于乌尔都语光学字符识别(OCR)的大规模合成数据集,包含开创性的Nastaliq字体集合和稳健的Naskh字体基础。
- Nastaliq(主要):包含499,845个样本,使用自定义的基于Chromium的渲染流程,以真实的Jameel Noori Nastaliq连字渲染。
- Naskh:包含1,000,160个样本,使用标准乌尔都语字体,用于基线OCR任务。 总计150万个样本,该数据集以优化的分片Parquet格式提供,以实现高效流式传输。
数据集结构
| 样式 | 样本数量 | 描述 |
|---|---|---|
| Nastaliq | 约500,000 | 真实的级联连字 + 强力的扫描增强。 |
| Naskh | 1,000,160 | 标准水平渲染。 |
数据模式
image:渲染的乌尔都语文本图像(高度标准化为64像素)。text:真实的乌尔都语字符串。filename:源文件和变体类型的引用。style:"nastaliq" 或 "naskh"。
配置
- 配置名称:
nastaliq(默认)- 数据文件:
- 训练集分割:
nastaliq/train-*.parquet - 验证集分割:
nastaliq/val-*.parquet
- 训练集分割:
- 数据文件:
- 配置名称:
naskh- 数据文件:
- 训练集分割:
data/train-*.parquet - 验证集分割:
data/val-*-of-00001.parquet
- 训练集分割:
- 数据文件:
数据集特点
- 任务类别:图像到文本
- 语言:乌尔都语(ur)
- 标签:ocr, nastaliq, urdu
- 规模类别:1M-10M
- 许可证:mit
Nastaliq数据生成方法(第二阶段)
为捕捉Nastaliq字体的复杂性,采用了超越标准图像渲染的方法:
- 高保真渲染:使用无头Chromium引擎(通过Playwright)渲染文本,实现100%真实的Jameel Noori Nastaliq字距和垂直堆叠。
- 人工质量控制:由母语者手动审查试点批次,识别并移除"乱码"或裁剪不当的样本。从最终的50万数据集中清除了31种特定的低质量模式。
- 强力的1:5增强:每条约10万条独特文本行用于生成4种独特的"破坏"变体,专门用于模拟现实世界中的扫描文档:
- V1: 灰尘扫描:灰度颗粒 + 胡椒噪声。
- V2: 细/压缩:形态学侵蚀 + JPEG压缩。
- V3: 浓墨:形态学膨胀(墨水渗色) + 高斯软化。
- V4: 雪地:粗颗粒 + 盐噪声(白点)。
使用示例
python from datasets import load_dataset
加载新的Nastaliq配置
dataset = load_dataset("PuristanLabs1/urdu-ocr-1M", "nastaliq", streaming=True) sample = next(iter(dataset["train"])) sample["image"].show()
致谢
由Puristan Labs制作。专业的Nastaliq流程使用基于Chromium的渲染和保留字符的形态学增强技术开发。
搜集汇总
数据集介绍
构建方式
在光学字符识别领域,乌尔都语因其独特的书写风格而面临特殊挑战。该数据集通过创新的合成方法构建,特别针对Nastaliq字体采用了基于Headless Chromium引擎的高保真渲染技术,确保连字和垂直堆叠的完全真实性。构建过程中进行了严格的人工质量控制,由母语者审查并剔除了31种低质量模式。此外,每个文本行都经过1:5的增强处理,生成了四种模拟真实扫描文档的破坏性变体,包括灰尘扫描、压缩变形、墨水扩散和雪花噪声等形态学增强,最终形成了包含约150万样本的大规模数据集。
特点
该数据集在乌尔都语OCR领域展现出显著特点,其核心在于首次大规模整合了Nastaliq字体样本,该字体以其复杂的连字和垂直堆叠结构著称,传统渲染方法难以准确呈现。数据集提供两种主要风格:Nastaliq配置包含约50万样本,采用真实连字和增强扫描模拟;Naskh配置则包含100万样本,提供标准水平渲染的基准数据。所有图像均统一为64像素高度,并附带原始文本、文件名和样式标签,以优化的Parquet分片格式存储,支持高效流式处理,为研究乌尔都语文字识别提供了前所未有的资源基础。
使用方法
研究人员和开发者可通过Hugging Face的datasets库便捷地访问该数据集。使用load_dataset函数并指定“nastaliq”或“naskh”配置,结合streaming=True参数即可实现流式加载,适用于大规模数据处理场景。加载后,数据集以迭代器形式提供,每个样本包含图像、文本等字段,图像可通过标准方法显示或进一步预处理。这种设计不仅简化了数据获取流程,还支持灵活的实验设置,助力于乌尔都语OCR模型的训练、评估及跨字体比较研究。
背景与挑战
背景概述
在光学字符识别领域,针对非拉丁语系文字的研究长期面临数据稀缺的挑战。urdu-ocr-1M数据集由Puristan Labs于近期创建,旨在解决乌尔都语,特别是其复杂书法体Nastaliq的自动识别问题。该数据集包含约150万样本,分为Nastaliq与Naskh两种字体风格,核心研究聚焦于如何通过高保真合成与数据增强技术,构建能够模拟真实扫描文档的大规模、高质量训练资源。这一工作显著推动了乌尔都语OCR技术的发展,为多语言信息处理与数字人文研究提供了关键基础设施。
当前挑战
该数据集致力于应对乌尔都语光学字符识别,尤其是Nastaliq连字手写体识别中的核心难题:Nastaliq字体独特的垂直堆叠、复杂连字与笔画粘连特性,使得传统OCR模型难以准确分割与识别。在构建过程中,挑战主要源于如何生成保真度高的合成数据。标准图像渲染库无法正确处理乌尔都语连字,迫使研究团队转向基于无头Chromium引擎的定制化渲染管线。此外,为确保数据质量,需进行人工审查以剔除无意义样本,并设计针对性的破坏性增强策略,以模拟现实世界中扫描文档的各种退化情况,如墨迹洇染、噪声干扰与压缩伪影。
常用场景
经典使用场景
在光学字符识别领域,特别是针对复杂书写系统的研究中,urdu-ocr-1M数据集为乌尔都语文本识别提供了关键资源。该数据集最经典的使用场景是训练和评估乌尔都语OCR模型,尤其是针对具有垂直堆叠和连字特征的Nastaliq字体。研究人员利用其大规模合成样本,能够构建鲁棒的深度学习架构,如卷积循环神经网络,以准确识别扫描文档或数字图像中的乌尔都语文字。
衍生相关工作
基于该数据集,学术界衍生了一系列经典研究工作。例如,研究者开发了专门针对Nastaliq字体的端到端识别模型,如改进的CRNN架构和注意力机制网络。这些工作不仅优化了乌尔都语OCR性能,还启发了其他波斯-阿拉伯文字系统的处理方案。此外,数据集的合成方法也为低资源语言的文本生成提供了参考,推动了多模态机器学习在文字识别中的创新应用。
数据集最近研究
最新研究方向
在乌尔都语光学字符识别领域,urdu-ocr-1M数据集以其大规模合成数据与针对Nastaliq字体的高保真渲染技术,正推动着多语言OCR模型的前沿探索。该数据集通过模拟真实扫描文档的增强策略,如灰尘噪声与形态学变形,为复杂手写体风格的识别提供了关键训练资源,促进了跨字体鲁棒性研究。其结合Chromium引擎的渲染方法,不仅提升了乌尔都语文本的视觉真实性,还激发了低资源语言OCR系统中数据合成与质量控制的创新实践,对数字文档保存与多语言信息处理具有深远影响。
以上内容由遇见数据集搜集并总结生成


