ER-FFppset
收藏Hugging Face2026-01-18 更新2026-01-19 收录
下载链接:
https://huggingface.co/datasets/Codebee/ER-FFppset
下载链接
链接失效反馈官方服务:
资源简介:
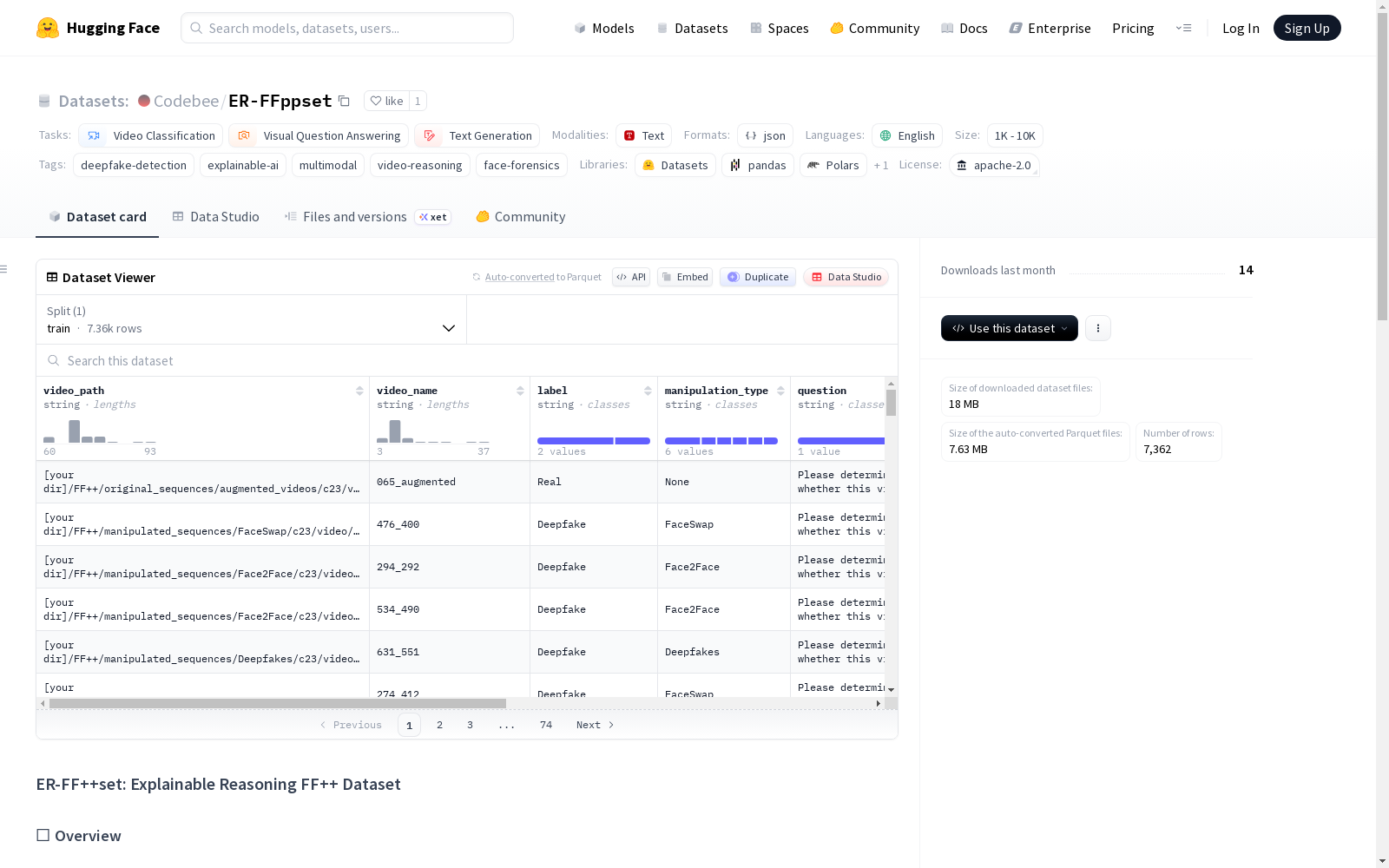
可解释推理FF++数据集(ER-FF++set)是一个新颖的基准数据集,专为可解释的深度伪造视频检测(EDVD)任务设计。与传统仅提供二元标签(真实/伪造)的数据集不同,ER-FF++set提供了适合训练多模态大语言模型(MLLMs)的视觉语言样本。该数据集基于广泛使用的FaceForensics++数据集构建,通过结构化数据对视频进行注释,提供可验证的推理解释,确保质量控制,并支持检测和推理的双重监督。数据集包含7,362个视频片段,其中真实视频2,362个(32.1%),伪造视频5,000个(67.9%),操纵类型均匀分布在Deepfakes、Face2Face、FaceSwap、FaceShifter和NeuralTexture中。
The Explainable Reasoning FF++ Dataset (ER-FF++set) is a novel benchmark dataset specifically designed for the Explainable Deepfake Video Detection (EDVD) task. Unlike traditional datasets that only provide binary labels (real/fake), ER-FF++set offers vision-language samples suitable for training Multimodal Large Language Models (MLLMs). Built upon the widely adopted FaceForensics++ dataset, this dataset annotates videos with structured data, provides verifiable reasoning explanations, ensures quality control, and supports dual supervision for both detection and reasoning. The dataset contains 7,362 video clips, including 2,362 real videos (32.1%) and 5,000 forged videos (67.9%), with manipulation types evenly distributed across Deepfakes, Face2Face, FaceSwap, FaceShifter, and NeuralTexture.
创建时间:
2026-01-10
原始信息汇总
ER-FF++set: Explainable Reasoning FF++ 数据集概述
数据集简介
ER-FF++set(Explainable Reasoning FF++ Dataset)是一个专为可解释性深度伪造视频检测(EDVD)任务设计的新型基准数据集。与传统仅提供二元标签(真实/伪造)的数据集不同,该数据集提供适用于训练多模态大语言模型的视觉-语言样本。它利用结构化数据为视频标注可验证的推理解释,确保质量控制,并支持检测与推理的双重监督。
数据集结构
数据集的视频源完全来自广泛使用的**FaceForensics++**数据集。通过对这些源视频进行处理,创建了一个富含结构化文本标注的专用子集。
数据字段
每个样本通常包含以下字段:
video_path: 视频文件路径(源自FaceForensics++)。label: 二元分类标签(0代表真实,1代表伪造)。manipulation_type: 使用的特定深度伪造技术(例如:Deepfakes、Face2Face、FaceSwap、FaceShifter、NeuralTexture或Real)。question: 提供给模型的指令提示(例如:“分析视频中的深度伪造伪影...”)。rationale: 详细、结构化的文本解释,描述视频为何是真实或伪造的,重点关注特定区域(眼睛、嘴巴、边界)和伪影。answer: 最终决策和摘要。
数据统计
- 总片段数: 7,362
- 真实视频数: 2,362(32.1%)
- 伪造视频数: 5,000(67.9%)
- 伪造类型分布: 在Deepfakes、Face2Face、FaceSwap、FaceShifter和NeuralTexture中均匀分布。
构建方法
数据集的构建采用严格流程以确保高质量、无幻觉的解释:
- 数据收集: 直接从**FaceForensics++**中采样视频,涵盖五种主流伪造方法。
- 结构化标注:
- 掩码生成: 通过真实帧与伪造帧的像素级比较生成伪造掩码。
- 面部区域分析: 将人脸划分为多个区域(嘴巴、鼻子、眼睛)。
- 定量评估: 对每个区域的伪造程度进行定量评估,形成结构化标签。
- LLM辅助原理生成: 利用预训练的多模态大语言模型(Qwen2.5-VL),在特定提示和结构化标签的引导下生成精确的文本描述。该过程通过将文本基于可验证的视觉伪影(例如:“重复的眉毛”、“边缘伪影”、“光照不一致”)来抑制幻觉。
使用目的
该数据集专为训练和评估用于深度伪造视频检测的多模态大语言模型而设计。它使模型不仅能学习什么是伪造的,还能理解为什么是伪造的。
基础信息
- 许可证: apache-2.0
- 任务类别: 视频分类、视觉问答、文本生成
- 语言: 英语
- 标签: 深度伪造检测、可解释人工智能、多模态、视频推理、人脸取证
- 规模类别: 1K<n<10K
搜集汇总
数据集介绍
构建方式
在深度伪造检测领域,构建高质量数据集对于推动可解释性研究至关重要。ER-FF++set的构建基于广泛使用的FaceForensics++数据集,从中精选视频样本并采用结构化标注流程。首先通过像素级比对生成伪造掩码,将面部区域细分为嘴、鼻、眼等关键部位进行定量评估,形成结构化标签。随后借助预训练的多模态大语言模型,以结构化标签为引导生成精确的文本解释,有效抑制幻觉现象,确保解释基于可验证的视觉伪影,如重复眉毛或边缘异常。
特点
该数据集的核心特点在于其融合了视觉与语言的多模态结构,为可解释深度伪造检测提供了系统化基准。与传统仅提供二元标签的数据集不同,ER-FF++set为每个样本配备了结构化推理解释,详细描述视频真伪的判断依据,聚焦于特定面部区域及伪影特征。数据分布涵盖五种主流伪造技术,样本量超过七千条,其中伪造视频占比约68%,真实视频占32%,确保了数据多样性与平衡性。这种设计使模型不仅能学习检测伪造,更能理解背后的视觉逻辑。
使用方法
ER-FF++set适用于训练和评估多模态大语言模型在深度伪造视频检测任务中的性能。使用者可通过加载数据集中视频路径、标签、伪造类型及配套的问答与解释字段,构建端到端的训练流程。模型能够同时学习检测任务与推理任务,利用提供的结构化解释增强其可解释性能力。该数据集支持视觉问答与文本生成等任务,为研究者探索深度伪造的细粒度分析及可信人工智能系统开发提供了坚实基础。
背景与挑战
背景概述
随着深度伪造技术的快速发展,其在视频内容中的滥用已引发广泛的社会信任危机。为应对这一挑战,学术界亟需构建能够同时实现检测与解释的基准数据集。ER-FF++set数据集由研究团队于近期提出,其核心研究聚焦于可解释的深度伪造视频检测任务。该数据集基于广泛使用的FaceForensics++数据集构建,通过引入结构化视觉-语言样本,为多模态大语言模型提供了同时学习分类与推理能力的训练资源。其创新之处在于不仅标注视频的真伪标签,还提供了基于视觉伪影的详细解释,推动了深度伪造检测向可解释人工智能方向的演进,对提升模型透明度和可信度具有重要意义。
当前挑战
在深度伪造检测领域,传统方法主要面临模型决策过程缺乏可解释性、难以让用户理解检测依据的挑战。ER-FF++set旨在解决这一核心问题,即实现可解释的深度伪造视频检测,使模型不仅能判断真伪,还能提供基于视觉伪影的推理依据。在数据集构建过程中,主要挑战包括确保解释的准确性与可靠性,避免大语言模型产生幻觉性描述;同时,需要设计严谨的标注流程,通过像素级掩码生成和面部区域定量分析,将视觉伪影转化为结构化的文本解释,以支撑高质量的双重监督学习。
常用场景
经典使用场景
在深度伪造检测领域,ER-FF++set数据集为多模态大语言模型提供了经典的应用场景。该数据集通过视觉-语言样本,支持模型在分析视频时不仅判断真伪,还能生成可解释的推理过程。研究者通常利用其结构化标注,训练模型识别面部区域(如眼睛、嘴巴、边界)的伪造痕迹,从而提升检测的透明度和可信度,这在推动可解释人工智能的发展中具有关键作用。
解决学术问题
ER-FF++set数据集解决了深度伪造检测中常见的学术研究问题,特别是传统方法仅提供二元标签而缺乏解释性的局限。它通过引入可验证的推理解释,支持双重监督机制,使模型能够同时学习检测和推理任务。这一创新不仅增强了检测结果的可靠性,还为理解伪造技术的具体机制提供了数据基础,对提升人工智能系统的可解释性和鲁棒性产生了深远影响。
衍生相关工作
ER-FF++set数据集衍生了一系列经典研究工作,其中最突出的是其原始论文中提出的EDVD-LLaMA模型,该模型利用多模态大语言模型进行可解释深度伪造视频检测。其他相关研究包括基于该数据集的结构化标注开发的新型检测算法,以及将可解释推理扩展到其他视觉任务中的方法。这些工作共同推动了深度伪造检测领域向更透明、更可靠的方向发展。
以上内容由遇见数据集搜集并总结生成


