sunday_journal_voices
收藏Hugging Face2025-06-22 更新2025-06-23 收录
下载链接:
https://huggingface.co/datasets/freococo/sunday_journal_voices
下载链接
链接失效反馈官方服务:
资源简介:
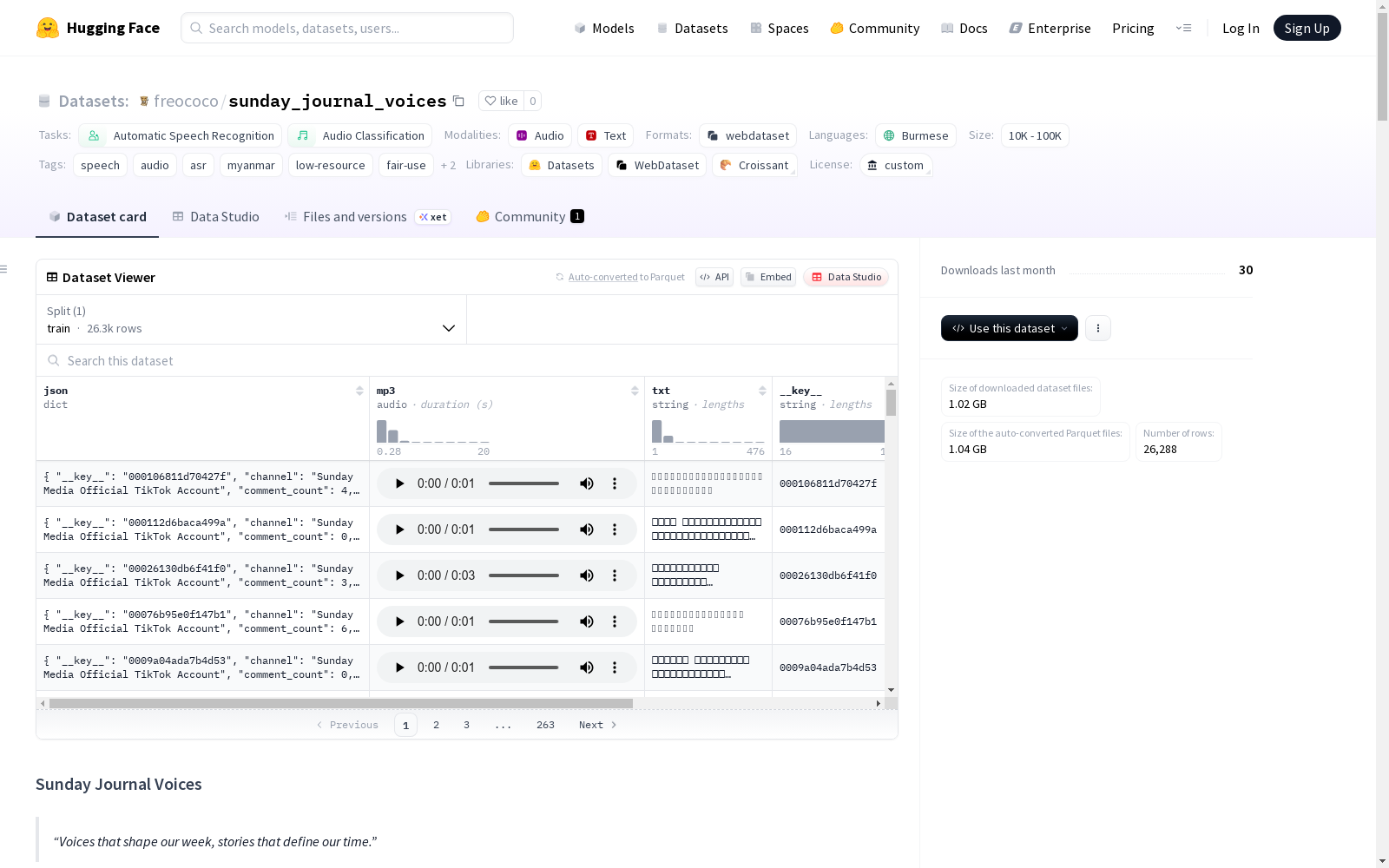
Sunday Journal Voices是一个大规模的缅甸语音频数据集,包含26,288个短音频片段,总时长约为18小时。这些音频片段来源于Sunday Journal的公共视频,是一个领先的缅甸数字媒体平台,以其深入的报道和访谈而闻名。数据集适用于自动语音识别和音频分类任务。
创建时间:
2025-06-21
原始信息汇总
Sunday Journal Voices 数据集概述
基本信息
- 名称: Sunday Journal Voices
- 简介: 包含26,288个短音频片段(约18小时)的缅甸语语音数据集,源自缅甸领先数字媒体平台Sunday Journal的公开视频
- 语言: 缅甸语 (my)
- 标签: speech, audio, asr, myanmar, low-resource, fair-use, tiktok, webdataset
- 任务类别: 自动语音识别, 音频分类
数据集内容
- 音频数量: 26,288个音频文本块
- 总时长: 17小时44分31秒
- 内容类型:
- 新闻分析与评论
- 公众人物、专家和社区领袖的深度访谈
- 社会、经济和文化话题讨论
- 实地报道和人文故事
数据集结构
- 格式: WebDataset格式的.tar.gz存档
- 文件组成:
.mp3: 从视频中提取的短音频块.json: 包含转录和上下文信息的对齐元数据
元数据字段
| 字段 | 描述 |
|---|---|
file_name |
音频文件名 |
original_file |
源视频的.mp3文件名 |
transcript |
缅甸语字幕 |
duration |
音频块时长(秒) |
video_url |
原始视频链接 |
language |
语言代码("my") |
title |
视频标题 |
description |
视频描述 |
view_count |
观看次数 |
like_count |
点赞数 |
comment_count |
评论数 |
repost_count |
转发/分享数 |
channel |
发布者名称 |
upload_date |
上传日期(YYYYMMDD格式) |
hashtags |
描述中的标签列表 |
thumbnail |
视频缩略图URL |
source |
来源(Sunday Journal) |
使用方式
- Hugging Face Datasets加载: python from datasets import load_dataset ds = load_dataset("freococo/sunday_journal_voices", split="train", streaming=True)
限制
- 自动字幕错误: 可能存在缺失词缀、拼写不一致等问题
- 未经人工校正: 反映自动化系统的原始性能
- 音频质量: 可能包含背景噪音、音乐叠加等
- 方言代表性不足: 主要为标准缅甸语
许可
- 类型: 公平使用/仅限研究许可
- 用途: 非商业研究、教育、语言保护、缅甸语开放AI开发
引用
bibtex @misc{freococo2025sundayjournalvoices, title = {Sunday Journal Voices: A WebDataset for Burmese ASR and Speech Research}, author = {freococo}, year = {2025}, howpublished = {Hugging Face Datasets}, url = {https://huggingface.co/datasets/freococo/sunday_journal_voices} }
搜集汇总
数据集介绍
构建方式
Sunday Journal Voices数据集通过系统化采集缅甸领先数字媒体平台Sunday Journal的公开视频构建而成,包含26,288个经过分段的音频文本对。数据源涵盖新闻评论、专家访谈和社会议题讨论等丰富内容,采用自动化字幕生成技术提取文本转录,并保留完整的视频元数据。所有内容以WebDataset格式封装为.tar.gz压缩包,每个音频片段均配有包含12项元数据的JSON文件,形成标准化的语音-文本对齐结构。
特点
该数据集作为缅甸语稀缺语音资源的重要补充,具有鲜明的领域特征。18小时的清晰正式缅甸语语音覆盖政治经济、社会文化等多领域话题,音频片段平均时长2.43秒,适合端到端语音模型训练。独特的价值在于其真实场景下的专业播音质量,配合视频观看量、点赞数等社交指标,为语音研究提供多维分析可能。尽管存在自动转录的固有局限,其规模仍居当前公开缅甸语数据集前列。
使用方法
数据集支持Hugging Face Datasets和WebDataset两种主流加载方式。通过streaming模式可实现动态流式读取,避免全量下载的存储压力。典型使用场景包括:自动语音识别模型的预训练与微调,音频特征提取研究,以及结合元数据的多模态分析。建议使用者针对自动转录文本实施质量过滤,或引入人工校验环节以提升数据可靠性。为遵守许可协议,商业应用需直接联系原始内容权利人获取授权。
背景与挑战
背景概述
Sunday Journal Voices数据集由缅甸领先的数字媒体平台Sunday Journal的公开视频构建而成,收录了26,288个短音频片段,总计约18小时的缅甸语语音数据。该数据集由freococo于2025年发布,旨在解决缅甸语作为低资源语言在人工智能领域中的代表性不足问题。数据集涵盖了新闻分析、专家访谈、社会文化讨论等多种内容,语音清晰且正式,为缅甸语语音技术研究提供了宝贵资源。该数据集的创建不仅填补了缅甸语语音数据的空白,也为全球研究者提供了研究低资源语言语音识别的新机遇。
当前挑战
Sunday Journal Voices数据集面临多重挑战。在领域问题方面,缅甸语作为低资源语言,其语音识别研究长期受限于数据稀缺,该数据集需应对方言多样性不足、自动转录错误等问题。在构建过程中,数据集面临自动字幕准确性问题,包括缺失词缀、拼写不一致等;音频质量受背景噪音、音乐叠加等因素影响;且缺乏人工校对环节。此外,数据集主要反映标准缅甸语,对地区口音和民族语言变体的覆盖有限,这些因素均对构建高精度语音识别模型提出了挑战。
常用场景
经典使用场景
在语音识别技术的研究中,Sunday Journal Voices数据集为缅甸语(Burmese)这一低资源语言提供了宝贵的语音数据资源。该数据集广泛应用于自动语音识别(ASR)系统的训练与评估,特别是在处理正式、清晰的缅甸语语音时表现出色。研究人员利用其丰富的音频文本对,能够有效提升模型在复杂语境下的识别准确率。
解决学术问题
该数据集显著缓解了缅甸语在语音技术研究中的数据匮乏问题,为低资源语言的ASR模型开发提供了坚实的基础。通过其多样化的语音样本,研究者能够深入探讨方言识别、多说话人检测以及噪声环境下的语音处理等前沿课题,进一步推动了语音技术在全球语言平等中的实践。
衍生相关工作
基于该数据集,多项经典研究工作得以展开,包括低资源语言ASR模型的优化、跨语言语音识别的迁移学习,以及语音情感分析在缅甸语中的应用。这些工作不仅丰富了语音技术的研究范畴,也为后续的学术探索和工业应用奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


