Style30K Illusion Dataset
收藏arXiv2024-12-11 更新2024-12-12 收录
下载链接:
https://zixuan-ye.github.io/stylemaster/
下载链接
链接失效反馈官方服务:
资源简介:
Style30K Illusion Dataset是一个用于视频风格迁移和风格化生成的数据集,由快手科技和香港科技大学联合创建。该数据集包含30000张风格图像,分为约30个风格组,旨在通过对比学习提升风格提取的准确性。数据集通过模型幻觉技术生成,确保了风格一致性,避免了手动收集和分组的繁琐过程。该数据集主要应用于视频风格迁移和风格化生成任务,旨在解决现有方法在风格一致性和内容泄露方面的不足。
Style30K Illusion Dataset is a dataset for video style transfer and stylized generation, jointly created by Kuaishou Technology and The Hong Kong University of Science and Technology. It contains 30,000 stylized images divided into approximately 30 style groups, aiming to improve the accuracy of style extraction through contrastive learning. The dataset is generated via model hallucination technology, ensuring style consistency and eliminating the tedious process of manual collection and grouping. It is mainly applied to video style transfer and stylized generation tasks, aiming to address the shortcomings of existing methods in terms of style consistency and content leakage.
提供机构:
香港科技大学, 快手科技
创建时间:
2024-12-11
搜集汇总
数据集介绍
构建方式
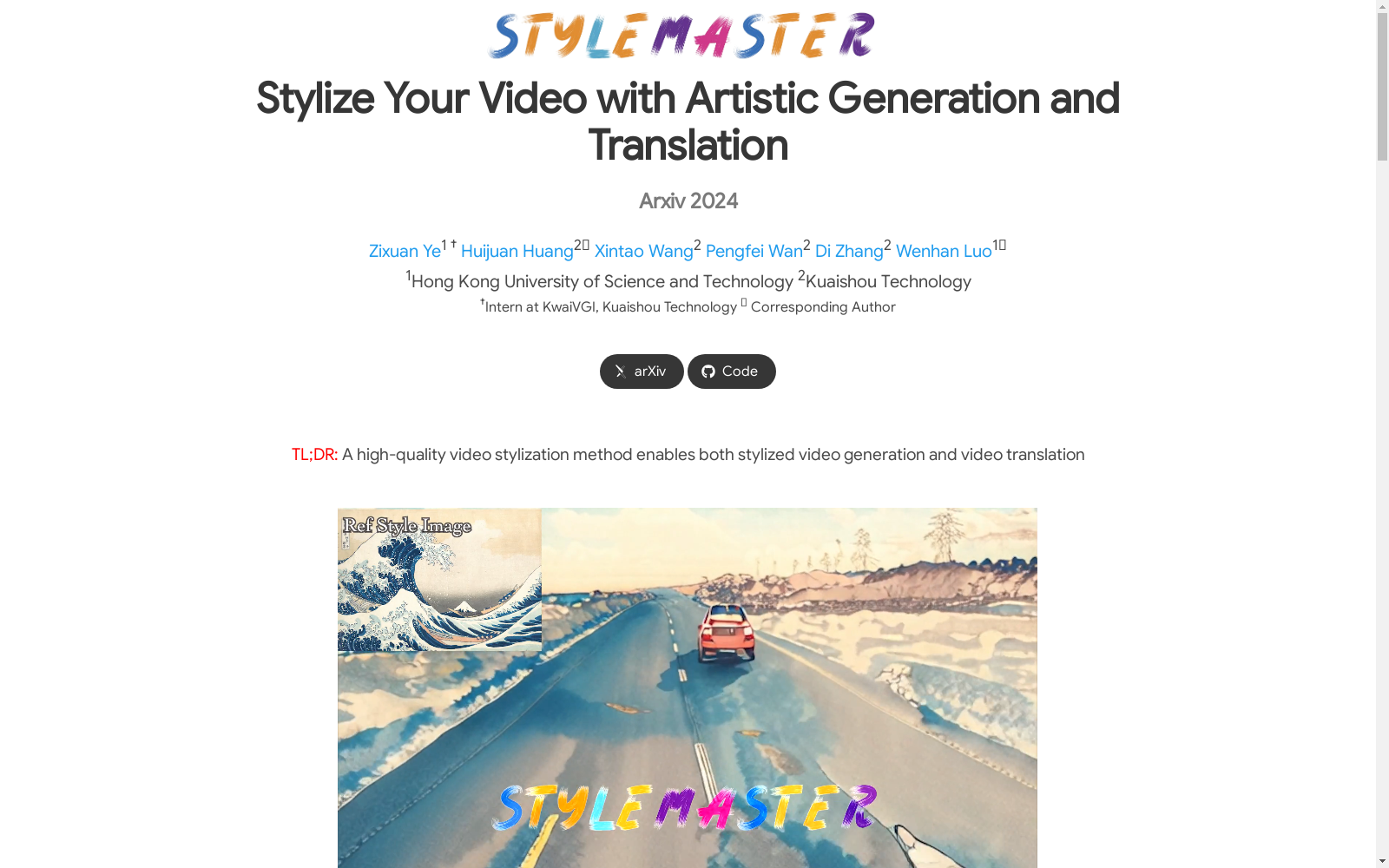
Style30K Illusion Dataset通过模型幻觉(model illusion)技术构建,利用预训练的文本到图像(T2I)模型生成具有绝对风格一致性的配对图像数据集。具体而言,该数据集通过在生成过程中对噪声图像进行视图变换(如旋转、翻转等),并使用不同的文本提示引导噪声预测,从而生成内容不同但风格一致的图像对。这种方法确保了数据集中的每对图像在风格上完全一致,同时避免了手动收集和分组的繁琐过程。
使用方法
Style30K Illusion Dataset主要用于训练风格提取器,特别是在视频风格迁移和图像风格迁移任务中。通过对比学习策略,该数据集能够帮助模型学习到全局和局部的风格特征,从而提升风格迁移的准确性和一致性。研究人员可以将该数据集用于训练轻量级的风格适配器,结合全局投影和局部特征选择,进一步增强模型的风格表示能力。
背景与挑战
背景概述
Style30K Illusion Dataset是由香港科技大学和快手科技的研究团队共同创建的,旨在解决视频风格迁移中的风格一致性和内容泄露问题。该数据集通过模型幻觉技术生成,确保了风格图像对之间的绝对一致性,从而为对比学习提供了高质量的数据支持。主要研究人员包括Zixuan Ye、Huijuan Huang等,他们的研究重点在于通过局部纹理和全局风格的结合,提升视频风格迁移的精确度和一致性。该数据集的创建不仅推动了视频风格迁移技术的发展,还为相关领域的研究提供了新的思路和方法。
当前挑战
Style30K Illusion Dataset在构建过程中面临的主要挑战包括:1) 如何确保风格图像对之间的绝对一致性,避免内容泄露;2) 如何高效生成大量风格数据,减少人工干预。此外,视频风格迁移领域的挑战还包括:1) 如何在保持局部纹理的同时,避免内容泄露;2) 如何实现视频风格迁移中的时间一致性,避免帧间闪烁;3) 如何通过简单的内容控制机制实现高质量的视频风格迁移。这些挑战不仅影响了数据集的构建,也对视频风格迁移技术的实际应用提出了更高的要求。
常用场景
经典使用场景
Style30K Illusion Dataset 主要用于视频风格迁移和艺术化生成任务。该数据集通过模型幻觉技术生成具有绝对风格一致性的配对图像,为对比学习提供了高质量的训练数据。其经典应用场景包括视频风格迁移、图像风格迁移以及文本驱动的艺术化视频生成,特别是在需要高风格一致性和局部纹理保留的任务中表现尤为突出。
解决学术问题
Style30K Illusion Dataset 解决了现有风格迁移方法中常见的风格一致性和内容泄露问题。通过模型幻觉技术生成的配对图像确保了风格的一致性,避免了传统方法中因风格数据集不一致导致的风格提取不准确问题。此外,该数据集通过局部纹理选择策略,有效防止了内容泄露,提升了风格迁移的精确度和稳定性。
实际应用
Style30K Illusion Dataset 在实际应用中广泛用于视频编辑、广告制作、艺术创作等领域。例如,在广告制作中,该数据集可以帮助快速生成符合特定艺术风格的视频内容,提升视觉效果。在艺术创作中,艺术家可以利用该数据集生成具有独特风格的艺术作品,满足个性化创作需求。
数据集最近研究
最新研究方向
Style30K Illusion Dataset在视频风格迁移领域的前沿研究中扮演了重要角色。最新的研究方向集中在通过模型幻觉生成具有绝对风格一致性的配对数据集,以提升风格提取的准确性。研究者们通过对比学习策略,结合全局和局部风格特征,有效解决了现有方法中内容泄露和风格不一致的问题。此外,引入运动适配器和灰砖ControlNet进一步增强了视频的动态质量和内容控制能力,使得视频风格迁移在保持高风格相似度的同时,实现了更好的文本与视频对齐。这些创新不仅推动了视频风格迁移技术的发展,还为相关领域的研究提供了新的思路和方法。
相关研究论文
- 1StyleMaster: Stylize Your Video with Artistic Generation and Translation香港科技大学, 快手科技 · 2024年
以上内容由遇见数据集搜集并总结生成


