HiTZ/flores_plus_gender
收藏Hugging Face2026-05-08 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/HiTZ/flores_plus_gender
下载链接
链接失效反馈官方服务:
资源简介:
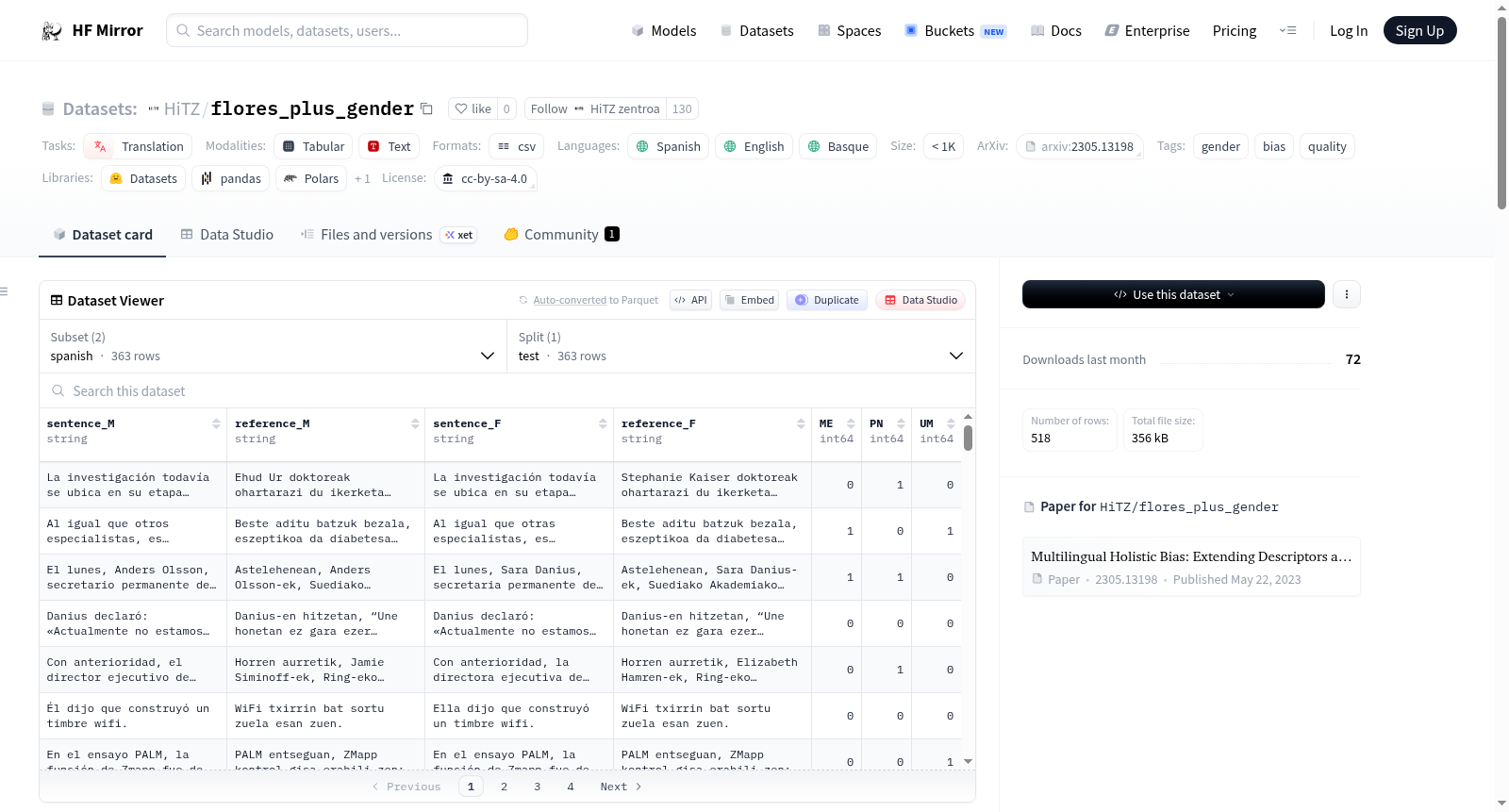
FLORES+Gender数据集基于Meta开发的FLORES+基准,旨在评估机器翻译系统中的性别偏见。与通常从无性别语言翻译到有性别语言的方法不同,该数据集采用Costa-jussà等人(2023)的方法,反向分析从有性别语言(西班牙语或英语)翻译到无性别语言(巴斯克语)时,源句子的主要语法性别是否影响翻译质量。数据集包含每个源语言的两种对比版本:一种为阳性形式句子,另一种为阴性形式句子。西班牙语集包含363个带有性别参考的句子,英语集包含155个句子。所有句子均经过手动调整以保持语义等效性。此外,每个实例还手动标注了可能影响翻译行为的三个语言和上下文因素:多实体(ME)、专有名词(PN)和无标记阳性(UM,仅适用于西班牙语)。这些注释支持更细粒度地分析不同语言线索如何与翻译质量中的性别偏见相互作用。
FLORES+Gender builds on the FLORES+ benchmark, developed by Meta to assess gender bias in machine translation (MT) systems. Unlike the typical approach of translating from a genderless language into a gendered one, this dataset follows the methodology of Costa-jussà et al. (2023) and reverses the direction to analyse whether translation quality is affected by the predominant grammatical gender of the source sentence when translating from a gendered language (Spanish or English) into a genderless one (Basque). For each source language, the dataset includes two contrastive versions: one containing all sentences in masculine form and another with the same sentences in feminine form. The Spanish set comprises 363 sentences with gendered references, while the English set contains 155. All sentences were manually adapted to produce gender-controlled pairs while maintaining semantic equivalence. Additionally, each instance was manually annotated for three linguistic and contextual factors that may influence translation behaviour: Multiple Entities (ME), Proper Names (PN), and Unmarked Masculine (UM, only in Spanish). These annotations enable more fine-grained analyses of how different linguistic cues interact with gender bias in translation quality.
提供机构:
HiTZ
搜集汇总
数据集介绍
构建方式
FLORES+Gender数据集在Meta开发的FLORES+基准测试基础上构建,旨在评估机器翻译系统中的性别偏见。不同于传统方法从无性别语言译为有性别语言,该数据集遵循Costa-jussà等人(2023)的方法,反向考察从有性别语言(西班牙语或英语)译为无性别语言(巴斯克语)时,源句主导语法性别是否影响翻译质量。针对每种源语言,数据集包含两个对比版本:所有句子分别为阳性形式和阴性形式。西班牙语集包含363个含性别指称的句子,英语集包含155个。所有句子均经过手动调整,以确保在保持语义等价的前提下生成性别控制的配对。此外,每个实例还手动标注了三种可能影响翻译行为的语言和语境因素:多实体存在、专有名词使用以及无标记阳性(仅适用于西班牙语)。
特点
该数据集的核心特点在于其精细化的控制实验设计,通过构建语法性别完全对称的对比语料对,为量化翻译质量中的性别偏见提供了严谨的测试平台。其创新之处在于逆转了传统偏见检测方向,专注于性别标记语言向无性别语言翻译时的质量差异。额外的三层手动标注(多实体、专有名词、无标记阳性)赋予数据集进行细粒度分析的能力,允许研究者探究不同语言线索与性别偏见之间的交互作用。数据集规模精炼,西班牙语和英语分别包含363和155个句子,确保高质量标注的可行性,同时覆盖了丰富的情境变体。
使用方法
数据集以TSV格式提供,包含西班牙语和英语两个配置,分别对应flores_es.tsv和flores_en.tsv文件。数据集中每条记录包含阳性句子及其巴斯克语参考译文、阴性句子及其巴斯克语参考译文,以及ME、PN和UM(仅西班牙语)三个二元标注字段。研究者可将该数据集用于评估机器翻译系统在性别维度上的翻译质量一致性与公平性,通过对比系统对阳性与阴性句子的翻译输出,量化潜在偏见。典型的评估流程包括:加载特定语言配置,将句子批量输入翻译模型,获取译文后与参考译文比较质量,并结合标注信息分析特定语境下的偏见模式。
背景与挑战
背景概述
FLORES+Gender数据集由西班牙巴斯克大学的研究人员于2026年创建,旨在评估机器翻译中的性别偏见。该数据集基于Meta开发的FLORES+基准,创新性地将翻译方向从有语法性别的语言(西班牙语、英语)转向无语法性别的语言(巴斯克语),探索源句的语法性别是否影响翻译质量。通过构建成对的男性与女性版本句子,并手动标注多实体、专有名词和未标记阳性等语言因素,该数据集为细粒度分析性别偏见与翻译质量的交互提供了重要工具。其研究对低资源语言机器翻译的公平性评估具有深远影响,推动了多语言环境下性别平等评价体系的发展。
当前挑战
该数据集面临的挑战首先体现在领域问题层面:机器翻译系统在处理性别信息时存在系统性偏见,尤其是从有语法性别的语言翻译到性别中立语言时,模型往往偏好阳性形式,导致女性指代的质量下降。在构建过程中,研究人员需手动为363句西班牙语句子和155句英语句子生成内容对等但性别相反的对照版本,这一过程要求严格保持语义等价性,避免引入额外变量。此外,对西班牙语中未标记阳性的标注(即雄性形式泛指所有人)需要语言学家深入判断,增加了数据构建的复杂性和主观性挑战。
常用场景
经典使用场景
FLORES+Gender数据集专为评估机器翻译系统中的性别偏见而设计,其经典使用场景在于衡量源语言语法性别对译文质量的影响,尤其是当从西班牙语或英语这类有语法性别的语言,翻译至巴斯克语这类无性别语言时。该数据集提供了成对的阳性与阴性对照句,使研究者能够精准对比同一句子在不同性别形式下的翻译表现,从而量化翻译模型对某一性别是否存在系统性偏好。这种对照实验范式构成了该数据集最核心的应用方式。
衍生相关工作
依托FLORES+Gender,研究者已催生出若干衍生工作。原始基准FLORES+为跨200种语言的大规模翻译评价提供了基础,而本数据集注入了性别细粒度视角,进一步启发了WinoMTeus这类面向巴斯克语的职业性别偏见评测资源。同时,该数据集促进了语言特定公平性评估框架的发展,并助力构建了兼容多重语言学特征(如专有名词、泛指阳性)的翻译质量分析工具链,为未来低资源语言环境下的性别公平翻译研究奠定了重要的方法论基础。
数据集最近研究
最新研究方向
当前,自然语言处理领域对机器翻译系统中的性别偏见问题日益关注,而FLORES+Gender数据集的发布恰逢其时地为这一前沿探索提供了关键评估工具。该数据集创新性地颠覆传统偏见检测方向,聚焦于从具有语法性别特征的语言(如西班牙语、英语)向无性别语言(如巴斯克语)翻译时,源语句的语法性别如何影响翻译质量。通过构建成对的阴阳性对照句对,并引入多实体、专有名词和未标记阳性等细粒度标注,研究者得以深入剖析语言线索与性别偏见的复杂互动。这一工作不仅回应了低资源语言评估资源匮乏的痛点,更推动了跨语言性别公平评估方法论的革新,其揭示的模型对阳性形式系统性偏袒的结论,警示业界需在模型设计与训练数据中融入更多性别敏感维度。
以上内容由遇见数据集搜集并总结生成


