UCR time series classification archive
收藏arXiv2025-03-26 更新2025-03-28 收录
下载链接:
http://www.cs.ucr.edu/~eamonn/time_series_data/
下载链接
链接失效反馈官方服务:
资源简介:
UCR时间序列分类档案是一个包含128个异构单变量时间序列数据集的存储库,来自于各种应用领域,其中112个数据集具有相等的序列长度。该数据集被广泛用于时间序列分类方法的研究和评估。文中指出,当前基准数据集中有许多数据集的表格特征较为明显,或者已经进行了良好的分段,这使得时间信息在分类中的重要性降低。为此,作者提出了UCR Augmented基准,通过向数据集中引入失配来减少表格特征的影响,强调时间信息的重要性。
The UCR Time Series Classification Archive is a repository containing 128 heterogeneous univariate time series datasets from diverse application domains, among which 112 datasets have uniform sequence lengths. This dataset collection has been widely utilized for the research and evaluation of time series classification methods. It is noted that many datasets in current benchmark datasets exhibit prominent tabular-like features or have been properly segmented, which reduces the importance of temporal information in classification tasks. To address this issue, the authors proposed the UCR Augmented benchmark, which introduces mismatches into the datasets to mitigate the impact of tabular-like features and emphasize the significance of temporal information.
提供机构:
新南威尔士大学
创建时间:
2025-03-26
搜集汇总
数据集介绍
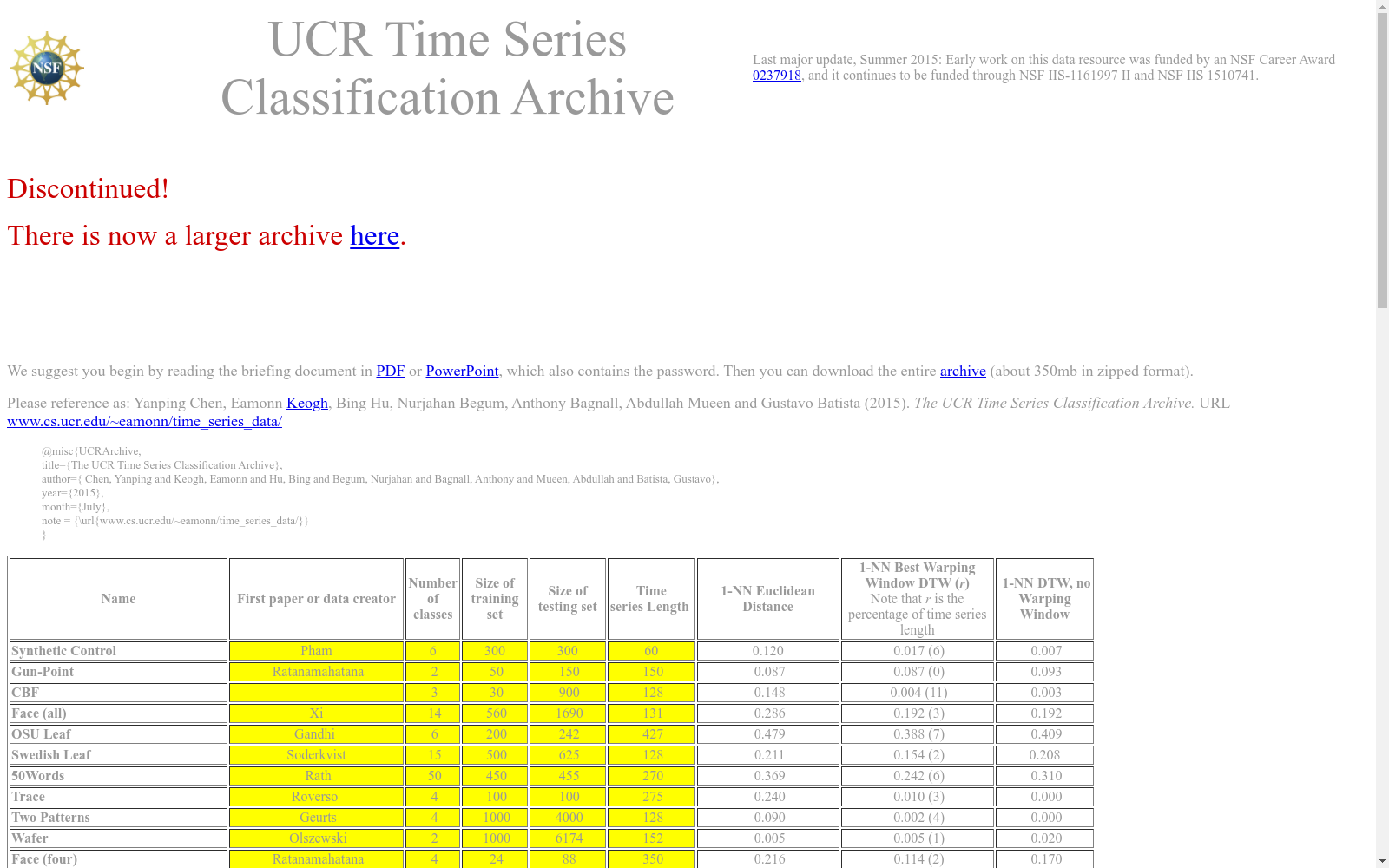
构建方式
UCR时间序列分类档案的构建基于多元化的实际应用场景,涵盖了128个异构的单变量时间序列数据集。这些数据集来自不同领域,其中112个具有等长序列,确保了基准的统一性和可比性。数据集的构建过程严格遵循时间序列的标准化处理流程,包括归一化和分段对齐,以保留时间序列的时序特征。此外,数据集通过手动或基于领域知识的预处理,确保了数据的质量和一致性,为时间序列分类研究提供了可靠的基准。
使用方法
使用UCR时间序列分类档案时,研究者可通过标准化流程加载和预处理数据,确保实验的可重复性。数据集通常用于评估分类器在原始序列和经过时序置换的序列上的性能差异,以验证时序信息的贡献。此外,通过引入UCR Augmented基准,用户可进一步测试分类器在强调时序信息的环境下的表现。具体操作包括对原始序列添加高斯随机游走填充以引入错位,从而削弱表格化特征的影响,迫使分类器依赖时序信息进行分类。
背景与挑战
背景概述
UCR时间序列分类档案库作为时间序列分类领域最具影响力的基准数据集之一,由加州大学河滨分校团队于2015年创建。该档案库收录了来自光谱分析、医疗监测、工业传感等多元领域的128个单变量时间序列数据集,其中112个具有等长序列特性。其核心价值在于为学术界提供了评估时序分类算法提取时间依赖特征能力的标准化平台,推动了动态时间规整(DTW)、形状变换(STC)等系列重要算法的发展。Chen等人通过统一的数据预处理和评估协议,显著提升了不同研究方法间的可比性,使该档案库成为近十年时间序列分类领域方法创新的核心验证基准。
当前挑战
该数据集面临的双重挑战主要体现在:从领域问题维度,约34%的数据集经置换检验揭示其分类性能不受时序信息破坏的影响,暴露出当前基准对真正依赖时序特征的分类任务评估存在偏差,部分数据集实质上更接近表格数据特性;从构建过程维度,数据集存在完美对齐和过度分割现象——光谱分析类数据因固定波长索引失去时序意义,而人工标注数据则因过度清洗削弱了真实时序的相位变化。这些局限性促使研究者提出UCR Augmented新基准,通过高斯随机游走填充策略引入可控的错位,强化时序特征在分类中的决定性作用。
常用场景
经典使用场景
UCR时间序列分类档案作为时间序列分类领域的黄金标准,广泛应用于算法性能评估和模型比较研究。该数据集包含128个异构单变量时间序列数据集,涵盖医疗监测、运动识别、光谱分析等多个领域,为研究者提供了丰富的基准测试场景。特别是在评估基于形状、间隔和特征的时间序列分类方法时,UCR档案能够有效验证算法捕捉时序模式的能力。
解决学术问题
该数据集解决了时间序列分类中时序信息重要性评估的关键问题。通过引入置换测试和UCR Augmented基准,研究者能够区分真正依赖时序信息的分类任务与本质上是表格数据的伪时序任务。这项工作纠正了长期以来对时序分类器评估的偏差,为开发真正利用时序特征的算法提供了理论依据,推动了时间序列分类研究向更严谨的方向发展。
实际应用
在实际工业应用中,UCR档案指导了故障预测、行为识别等重要场景的模型开发。例如在设备状态监测中,基于该基准优化的Shapelet变换分类器能准确识别机械振动异常;在医疗领域,通过UCR Augmented验证的Mini-Rocket算法可有效分析心电图时序特征。这些应用显著提升了工业预测性维护和医疗诊断的准确率。
数据集最近研究
最新研究方向
在时间序列分类领域,UCR时间序列分类档案作为最广泛使用的基准数据集,近期研究揭示了其部分数据集对时间信息的依赖性较低。通过引入时间信息去除测试,研究发现约34%的数据集在时间信息被破坏后分类准确率未显著下降,表明这些数据集本质上更接近表格数据。为解决这一问题,研究者提出了UCR Augmented基准,通过引入高斯随机游走填充来增强时间信息的重要性。实验表明,传统依赖表格特征的方法(如Rotation Forest)在新基准上性能显著下降,而基于形状的方法(如STC)则展现出更强的鲁棒性。这一发现为时间序列分类器的评估提供了更严谨的框架,并推动了对相位无关方法的重新关注。
相关研究论文
- 1Revisit Time Series Classification Benchmark: The Impact of Temporal Information for Classification新南威尔士大学 · 2025年
以上内容由遇见数据集搜集并总结生成


