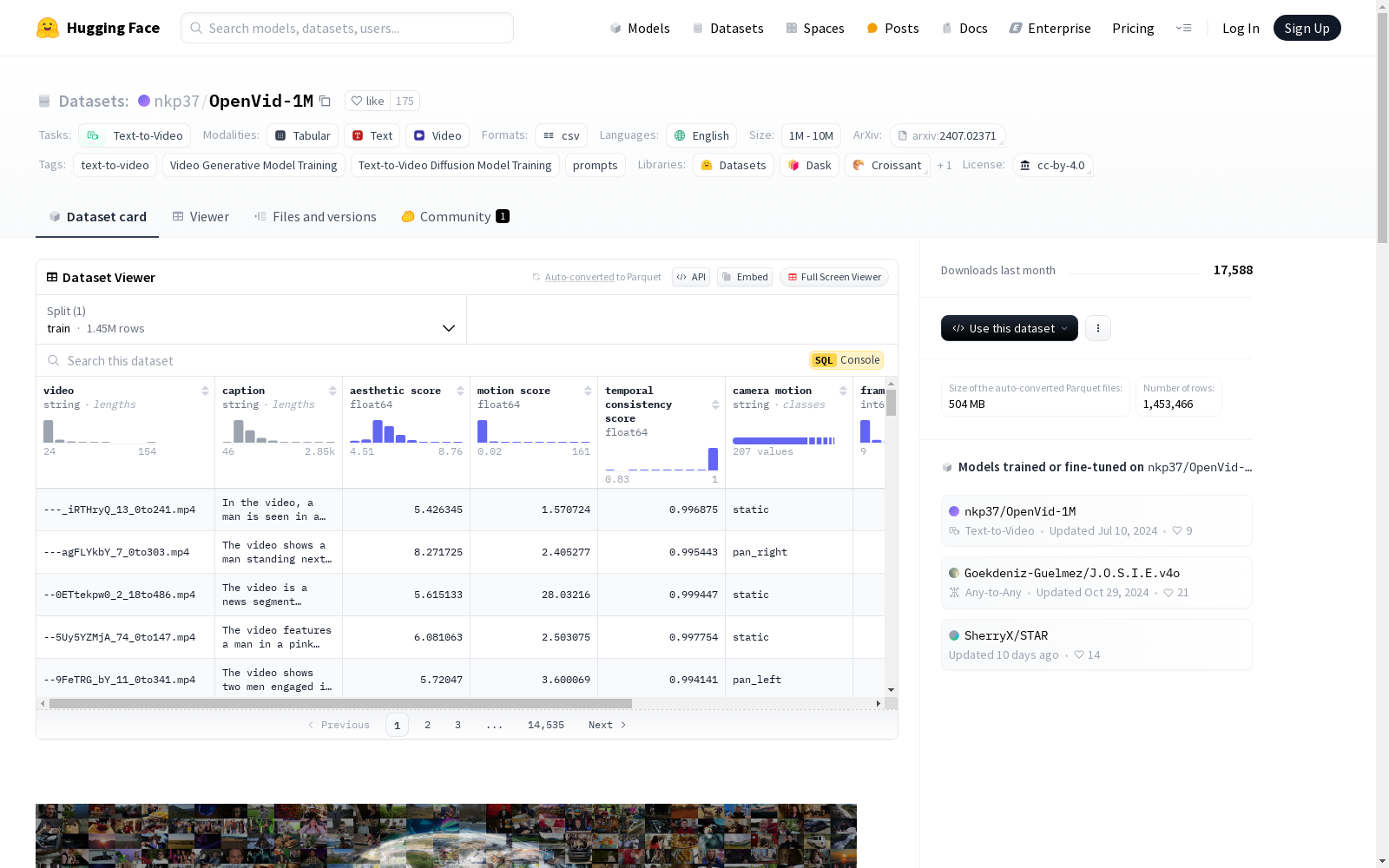
OpenVid-1M
收藏数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类别: 文本到视频
- 语言: 英语
- 标签: 文本到视频, 视频生成模型训练, 文本到视频扩散模型训练, 提示
- 数据集名称: OpenVid-1M
- 数据集大小: 1M<n<10M
数据集描述
OpenVid-1M 是一个高质量的文本到视频数据集,专为研究机构设计,旨在提升视频质量。该数据集具有高美学、清晰度和分辨率,可用于直接训练或作为其他视频数据集的质量调优补充。所有视频的分辨率至少为 512×512,并且从中精选了 433K 1080p 视频创建了 OpenVidHD,以推进高清视频生成。
数据集结构
DATA_PATH └─ data └─ train └─ OpenVid-1M.csv └─ OpenVidHD.csv └─ OpenVid_part0.zip └─ OpenVid_part1.zip └─ OpenVid_part2.zip └─ ...
下载方式
数据集可通过提供的下载脚本或使用 wget 命令进行下载。
使用方法
数据集文件可通过 unzip 命令解压,部分大文件已拆分为多个小文件,可通过 cat 命令恢复。OpenVid-1M.csv 和 OpenVidHD.csv 包含文本-视频对,可通过 pandas 读取。
模型权重
提供了在 OpenVid-1M 上预训练的模型权重。
许可证
数据集以 CC-BY-4.0 许可证发布,视频样本来自公开可用的数据集,用户必须遵守相关许可证。
引用
@article{nan2024openvid, title={OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation}, author={Nan, Kepan and Xie, Rui and Zhou, Penghao and Fan, Tiehan and Yang, Zhenheng and Chen, Zhijie and Li, Xiang and Yang, Jian and Tai, Ying}, journal={arXiv preprint arXiv:2407.02371}, year={2024} }