ought/raft
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ought/raft
下载链接
链接失效反馈资源简介:
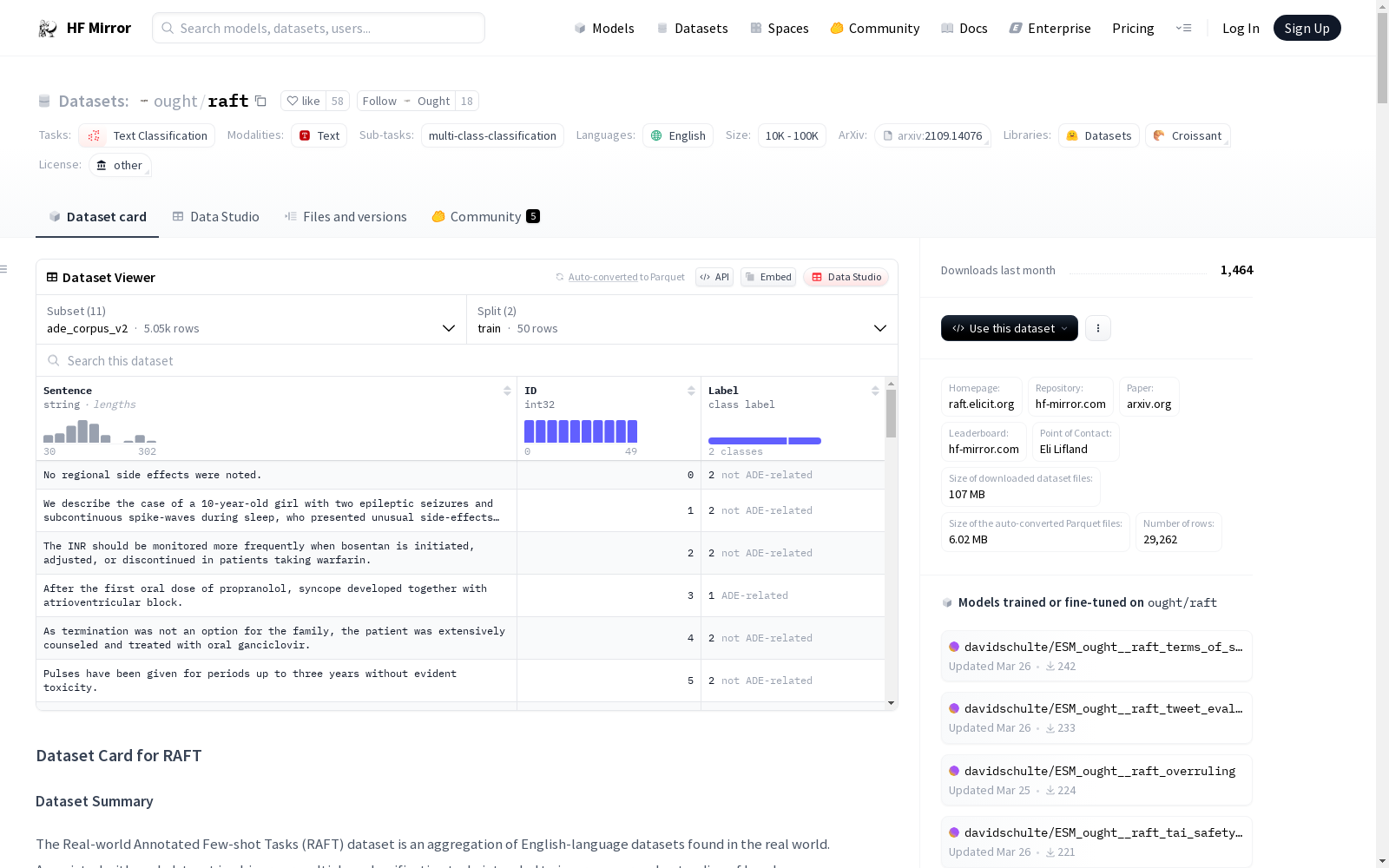
RAFT(Real-world Annotated Few-shot Tasks)数据集是一个聚合了现实世界中英语数据集的集合,每个数据集都关联一个二分类或多分类任务,旨在提高我们对语言模型在具有实际价值的任务上表现的理解。每个数据集仅提供50个标注示例。数据集主要用于文本分类任务,支持的任务包括多类分类,并且可以通过RAFT排行榜提交结果。数据集完全使用美式英语(en-US),包含了多个子数据集,如Ade Corpus V2、Banking 77、NeurIPS Impact Statement Risks等。数据集的创建背景是为了评估NLP模型在真实世界任务上的表现,而不是使用人为构造的数据源。数据集的注释过程由专家和众包人员完成,部分数据集包含敏感信息。
RAFT (Real-world Annotated Few-shot Tasks) dataset is a curated collection of real-world English datasets. Each dataset is paired with a binary or multi-class classification task, aiming to improve understanding of language model performance on tasks with practical utility. Every dataset provides exactly 50 annotated examples. The dataset is primarily designed for text classification tasks, with multi-class classification being one of the supported task types, and results can be submitted via the RAFT Leaderboard. All data uses American English (en-US) and includes multiple sub-datasets such as Ade Corpus V2, Banking 77, and NeurIPS Impact Statement Risks. The dataset was developed to evaluate NLP models' performance on real-world tasks, rather than relying on artificially constructed data sources. The annotation process was completed by experts and crowdworkers, and some sub-datasets contain sensitive information.
提供机构:
ought
原始信息汇总
数据集概述
数据集名称
- 名称: Real-world Annotated Few-shot Tasks (RAFT)
- 别名: RAFT
数据集基本信息
- 语言: 英语(en-US)
- 许可证: 多种,包括MIT License、CC BY 4.0等
- 多语言性: 单语种
- 数据集来源: 原始数据集和扩展数据集(如ade_corpus_v2、banking77等)
- 任务类型: 文本分类(text-classification)
- 任务ID: 多类分类(multi-class-classification)
数据集结构
- 数据实例: 包含多个子数据集,如Ade Corpus V2、Banking 77等,每个子数据集包含文本数据和对应的标签。
- 数据字段: 包括ID和文本数据字段,其中ID用于索引数据点。
- 数据分割: 提供训练数据和未标记的测试数据,训练数据随机选择,不保证类别平衡。
数据集创建
- 采集理由: 为了创建一个不包含人为或人工数据源的NLP模型评估基准。
- 源数据: 多数数据集从现有来源收集,部分数据集如NeurIPS impact statement risks、Semiconductor org types、TAI Safety Research由RAFT团队直接收集。
- 标注: 标注过程包括直接在Google Spreadsheet中输入标注,标注者包括Ought支付的承包商和数据集策展人。
使用数据集的注意事项
- 个人和敏感信息: 部分数据集如Tweet Eval Hate包含高度冒犯性内容,NeurIPS impact statement risks包含作者姓名。
- 数据集限制: 如NeurIPS impact statement risks数据集可能包含未完全校验的文本。
附加信息
- 数据集策展人: 包括Neel Alex, Eli Lifland, 和 Andreas Stuhlmüller等。
- 许可证信息: 每个子数据集有自己的许可证,如Ade Corpus V2为无许可证,Banking 77为CC BY 4.0等。
- 贡献者: 感谢@neel-alex, @uvafan, 和 @lewtun等。
搜集汇总
数据集介绍
构建方式
RAFT数据集旨在通过聚合现实世界中的英文数据集,为NLP模型提供一个真实、有价值的测试基准。每个子数据集都关联一个二分类或多分类任务,仅提供50个标注示例,以模拟少样本学习场景。数据集的创建包括从原始数据源中收集和规范化数据,然后由专家或众包方式进行标注。
使用方法
使用RAFT数据集时,首先需要加载相应的子数据集,然后可以使用训练集进行模型训练,并使用未标注的测试集进行模型评估。数据集的ID字段用于索引数据点,其他字段则包含文本数据,包括句子、标题、摘要等。在处理数据时,需要注意保护个人和敏感信息,并遵守相关法律法规。
背景与挑战
背景概述
在自然语言处理(NLP)领域,小样本学习(few-shot learning)是一个关键的研究课题,旨在使模型能够从少量示例中学习并泛化到未见过的数据。为了评估和推动小样本学习的研究,Ought团队创建了Real-world Annotated Few-shot Tasks (RAFT)数据集。该数据集由多个英语语言的数据集组成,每个数据集都与一个二元或多元分类任务相关联,旨在提高我们对语言模型在具有实际价值的任务上表现的理解。RAFT数据集于2021年发布,由Ought团队负责,包括Neel Alex、Eli Lifland和Andreas Stuhlmüller等研究人员。该数据集通过提供仅50个标记示例的挑战,对NLP领域的小样本学习研究产生了重要影响。
当前挑战
RAFT数据集在解决实际世界中的文本分类任务方面面临多项挑战。首先,由于每个数据集只提供了50个标记示例,模型必须从非常有限的信息中学习,这要求模型具备强大的泛化能力。其次,数据集的构建过程中,研究人员需要从多个来源收集和整合数据,确保数据质量和一致性是一项复杂的任务。此外,由于数据集包含真实世界的文本,因此可能存在潜在的社会偏见和敏感信息,需要谨慎处理以避免不公平的结果。最后,由于数据集的规模和多样性,模型训练和评估的效率也是一个重要的挑战。
常用场景
经典使用场景
在自然语言处理领域,小样本学习(Few-shot Learning)一直是研究的热点,特别是对于文本分类任务。RAFT 数据集作为一个聚合了真实世界英语数据集的集合,其经典使用场景在于为小样本文本分类任务提供一个基准测试。该数据集包含了多个领域的数据集,如金融、科技、社交媒体等,每个数据集都提供了少量标签样本(通常为50个),并设计成二元或多元分类任务,这为模型评估提供了一个真实世界的应用背景。
解决学术问题
RAFT 数据集解决了在小样本学习场景下,NLP 模型评估的基准问题。传统的小样本学习研究往往依赖于人工构造的数据集,这些数据集可能无法反映真实世界中的数据分布和任务复杂性。RAFT 数据集通过聚合真实世界的数据,并设计成具有具体应用价值的小样本分类任务,使得研究人员能够更准确地评估模型在小样本学习场景下的性能,推动了小样本学习技术在真实世界应用中的发展。
实际应用
RAFT 数据集的实际应用场景非常广泛,它可以用于评估和改进小样本学习算法在真实世界文本分类任务中的表现。例如,在金融领域,RAFT 数据集可以用于评估模型对银行服务分类的能力;在科技领域,它可以用于评估模型对学术论文影响声明风险分类的能力;在社交媒体领域,它可以用于评估模型对仇恨言论检测的能力。此外,RAFT 数据集还可以用于开发新的小样本学习算法,以提高模型在真实世界应用中的泛化能力。
数据集最近研究
最新研究方向
在自然语言处理(NLP)领域,小样本学习已成为一个重要的研究方向。RAFT数据集的推出,旨在为NLP模型提供一个基于真实世界的、小样本任务的数据集,以便更准确地评估模型在实际应用中的表现。RAFT数据集涵盖了多个子任务,每个子任务都只提供50个标注样例,这使得研究者在模型训练过程中必须考虑如何有效地利用有限的标注数据。此外,RAFT数据集还提供了 leaderboard,以促进研究者之间的交流和竞争,推动小样本学习技术的发展。
以上内容由遇见数据集搜集并总结生成


