Detecting-Semantic-Concerns-in-Tangled-Code-Changes-Using-SLMs
收藏Hugging Face2025-08-08 更新2025-08-09 收录
下载链接:
https://huggingface.co/datasets/Berom0227/Detecting-Semantic-Concerns-in-Tangled-Code-Changes-Using-SLMs
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含用于软件工程任务训练和评估的提交数据,特别是用于识别和分离多关注点提交中的关注点。数据集分为两种主要配置:sampled配置包含单一关注点的原子提交,tangled配置包含将多个原子提交组合在一起的多关注点提交。
创建时间:
2025-08-02
原始信息汇总
数据集概述:Detecting-Semantic-Concerns-in-Tangled-Code-Changes-Using-SLMs
基本信息
- 许可证: MIT
- 任务类别: 文本生成、文本分类
- 语言: 英语
- 标签: 代码、Git、提交记录、软件工程、关注点分离
- 规模: 1K<n<10K
数据集描述
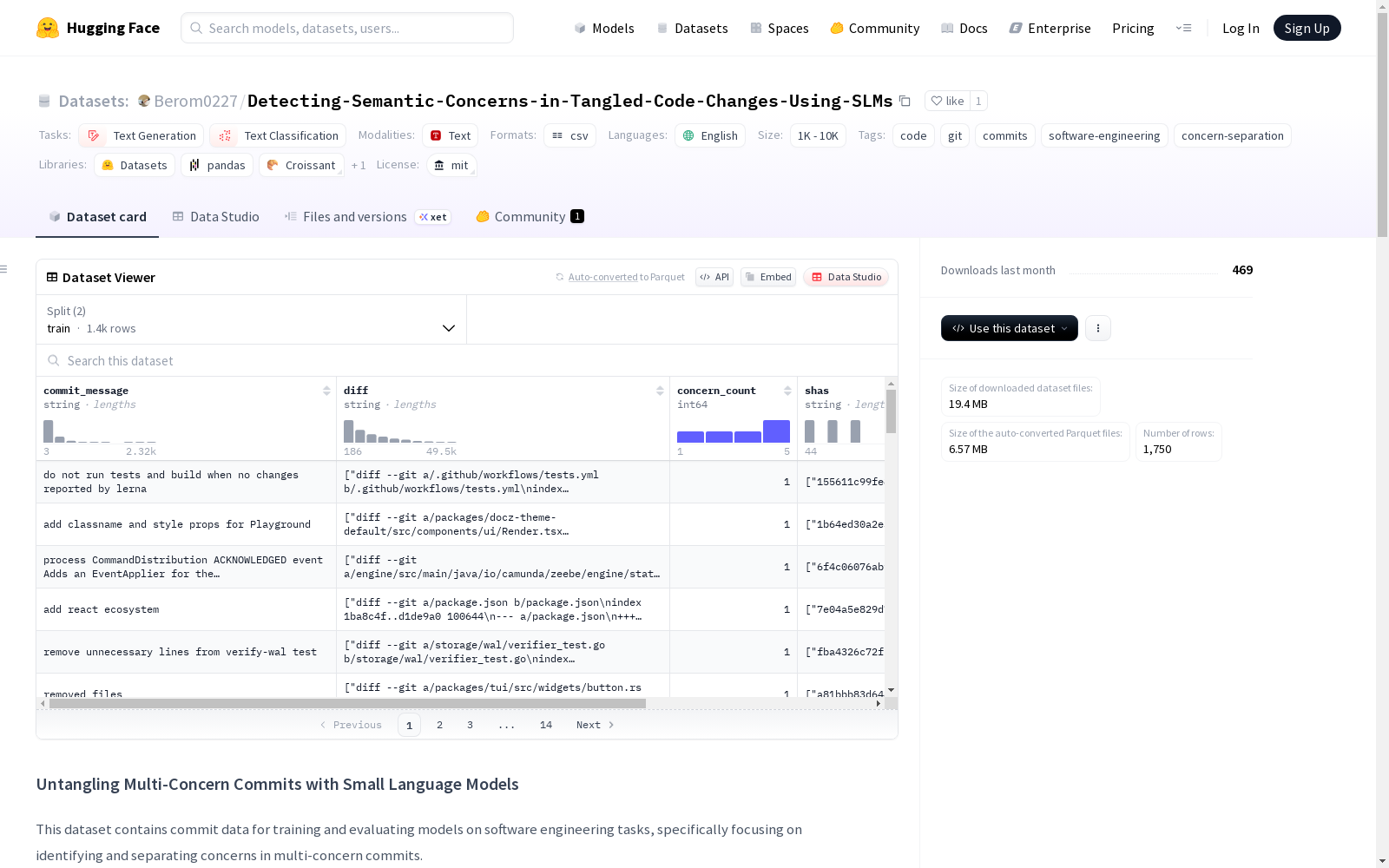
该数据集包含两种主要配置:
1. 采样数据集 (sampled)
- 文件:
data/sampled_ccs_dataset.csv - 描述: 包含单一关注点的原子提交记录
- 特征:
annotated_type: 提交记录中的关注点/变更类型masked_commit_message: 敏感信息被屏蔽的提交消息git_diff: 以diff格式表示的实际代码变更sha: Git提交记录的SHA哈希值
2. 纠缠数据集 (tangled)
- 文件:
data/tangled_ccs_dataset.csv - 描述: 包含多个关注点的复合提交记录
- 特征:
description: 所有关注点的组合描述diff: 所有变更的组合diffconcern_count: 组合的关注点数量shas: 包含原始提交记录SHA哈希值的JSON字符串types: 包含关注点类型的JSON字符串
数据集统计
- 采样数据集: ~1.3MB,包含原子提交记录
- 纠缠数据集: ~7.1MB,包含人工合成的复合关注点提交记录
使用场景
- 提交消息生成: 为代码变更生成合适的提交消息
- 关注点分类: 分类提交记录中的关注点类型
- 提交记录分解: 将复合关注点提交记录分解为单个关注点
- 代码变更分析: 理解代码变更与其描述之间的关系
数据收集与处理
数据集创建过程包括:
- 从软件仓库收集原子提交记录
- 基于质量标准采样和过滤提交记录
- 人工合成原子提交记录以创建复合关注点示例
- 在保留语义内容的同时屏蔽敏感信息
引用
bibtex @dataset{css_commits_dataset, title={Untangling Multi-Concern Commits with Small Language Models}, author={Your Name}, year={2024}, url={https://huggingface.co/datasets/Untangling-Multi-Concern-Commits-with-Small-Language-Models} }
脚本与工具
包含多个Python脚本用于数据处理和分析:
sample_ccs_dataset.py: 用于采样和过滤提交记录的脚本generate_tangled.py: 用于创建复合关注点提交记录的脚本clean_ccs_dataset.py: 数据清洗和预处理工具show_sampled_diffs.py: 采样提交记录diff的可视化show_tokens_distribution.py: 数据集中令牌分布的分析
许可证
该数据集采用MIT许可证发布。
数据集加载
可使用Hugging Face datasets库加载该数据集:
python
from datasets import load_dataset
加载采样数据集
sampled_data = load_dataset("Untangling-Multi-Concern-Commits-with-Small-Language-Models", "sampled")
加载纠缠数据集
tangled_data = load_dataset("Untangling-Multi-Concern-Commits-with-Small-Language-Models", "tangled")
搜集汇总
数据集介绍
构建方式
在软件工程领域,代码提交的语义分析对于理解开发意图至关重要。本数据集通过系统化流程构建:首先从软件仓库采集原子提交,经过质量筛选后保留符合标准的单关注点提交;随后采用人工合成策略,将多个原子提交组合成复杂的多关注点提交实例,同时对所有敏感信息进行掩码处理以保护隐私并保持语义完整性。
特点
该数据集呈现双模态结构:采样数据集包含约1.3MB的单关注点原子提交,每条记录包含标注类型、掩码提交信息和代码差异;纠缠数据集约7.1MB,通过人工构造的多关注点提交展现复合特征,包括混合描述、组合差异及原始提交的哈希序列。这种设计有效模拟了真实开发环境中代码变更的复杂性。
使用方法
研究者可通过Hugging Face数据集库加载两个子集:采样数据集适用于提交消息生成和关注点分类任务,纠缠数据集专用于提交解构和代码变更分析。典型应用场景包括训练模型识别提交中的语义关注点,或将多关注点提交分解为原子变更,为软件维护研究提供重要数据支撑。
背景与挑战
背景概述
在软件工程领域,代码提交的语义分析一直是版本控制系统研究的核心议题。Detecting-Semantic-Concerns-in-Tangled-Code-Changes-Using-SLMs数据集由研究团队于2024年构建,专注于解决多关注点提交中的语义分离问题。该数据集通过收集原子提交并人工构建复杂提交样本,为小语言模型在代码变更理解、提交消息生成等任务提供了重要基准,显著推动了智能编程辅助工具的发展。
当前挑战
该数据集致力于解决软件工程中多关注点提交的语义分离挑战,包括准确识别混合提交中的独立关注点、生成精确的提交消息以及实现代码变更的自动分解。构建过程中面临数据质量控制的复杂性,需要确保原子提交的纯净性;同时人工构建多关注点提交时需保持语义一致性,避免引入噪声;此外还需处理敏感信息的掩蔽问题,确保数据隐私安全。
常用场景
衍生相关工作
围绕该数据集已衍生出多项经典研究工作,包括基于小语言模型的提交消息生成系统、多任务学习的关注点分类框架,以及结合图神经网络的代码变更分析模型。这些工作显著推进了自动化软件工程领域的发展,为智能代码审查和软件质量保障提供了新的技术路径。
数据集最近研究
最新研究方向
在软件工程智能化研究领域,该数据集正推动基于小型语言模型的代码变更语义分析前沿探索。研究者们聚焦于多关注点提交的自动解构技术,通过结合自然语言处理与代码差异分析,实现复杂提交的语义分离和分类。这一方向与当前DevOps自动化流程优化、代码审查智能化等热点紧密结合,为提升软件维护效率和质量提供了重要数据支撑。相关研究不仅促进了提交信息自动生成技术的精进,更为理解开发人员意图与代码变更间的深层关联开辟了新途径,对智能编程助手和代码质量保障系统的发展具有显著意义。
以上内容由遇见数据集搜集并总结生成


