CDDB
收藏arXiv2022-11-14 更新2024-06-21 收录
下载链接:
https://github.com/Coral79/CDDB
下载链接
链接失效反馈官方服务:
资源简介:
CDDB(持续深度伪造检测基准)是由苏黎世联邦理工学院和新加坡管理大学等机构共同创建的数据集,专注于研究持续出现的深度伪造检测问题。该数据集收集了来自已知和未知生成模型的深度伪造数据,设计了多种评估方案,以检测模型在面对简单、困难和长期序列的深度伪造任务时的表现。CDDB的应用领域主要集中在提高深度伪造检测的准确性和效率,解决隐私、社会安全和民主等方面的问题。
CDDB (Continuous Deepfake Detection Benchmark) is a dataset co-developed by institutions including ETH Zurich and Singapore Management University, focusing on research into continuous deepfake detection. This dataset collects deepfake data from both known and unknown generative models, and designs multiple evaluation protocols to assess model performance on deepfake detection tasks involving simple, challenging, and long-sequence inputs. The primary application domains of CDDB are centered on improving the accuracy and efficiency of deepfake detection, and addressing issues related to privacy, social security, and democracy.
提供机构:
苏黎世联邦理工学院
创建时间:
2022-05-11
搜集汇总
数据集介绍
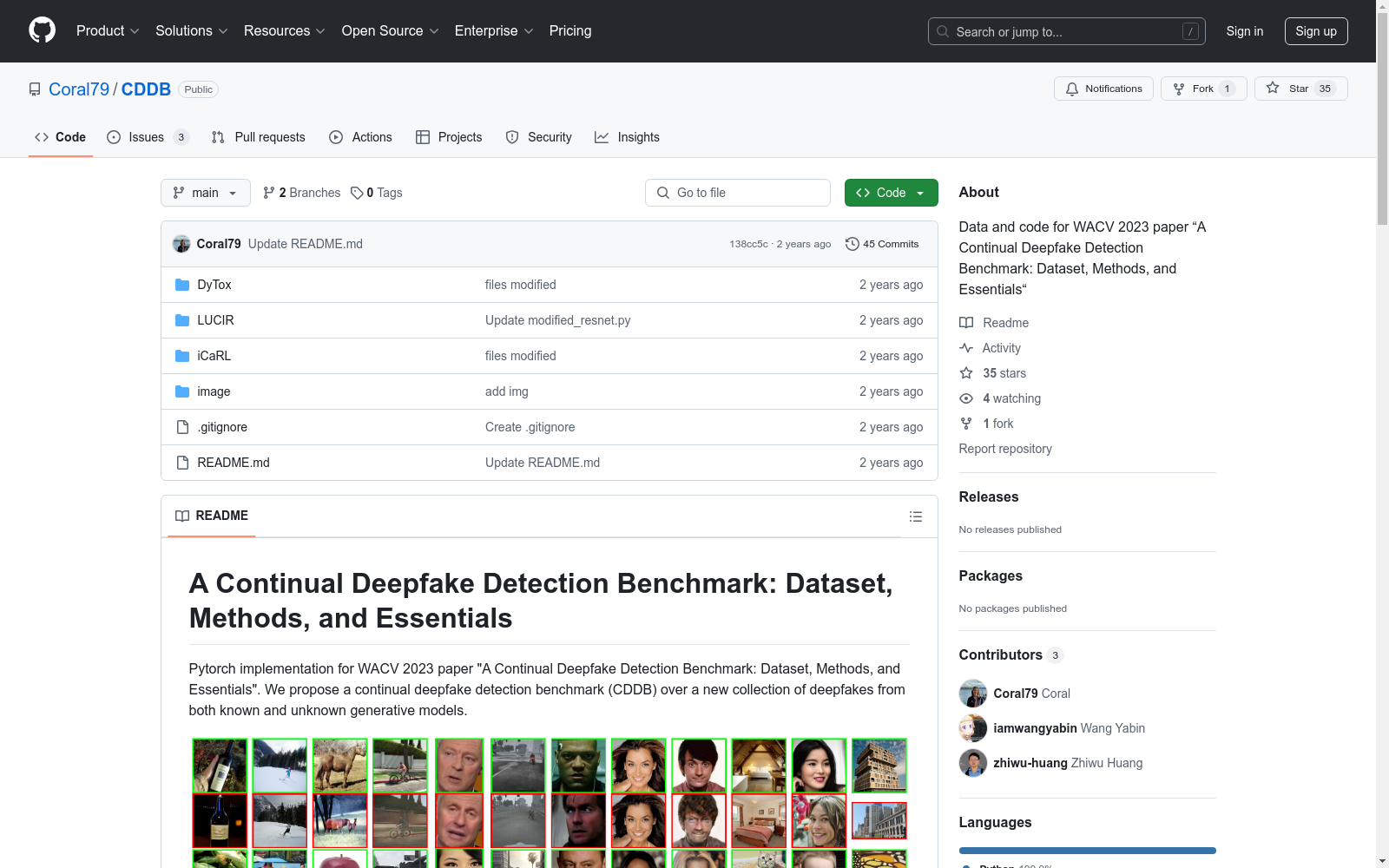
构建方式
CDDB数据集的构建方式旨在模拟真实世界中深度伪造(deepfake)的动态演化。该数据集汇集了来自已知和未知生成模型的深度伪造图像和视频,涵盖了多种生成技术,如GAN、Glow和CycleGAN等。通过逐步引入这些深度伪造数据,CDDB设计了多种评估场景,包括简单、困难和长序列任务,以全面评估检测器在不同情境下的性能。
特点
CDDB数据集的主要特点在于其高度异质性和动态性。它不仅包含了多种已知的深度伪造技术,还引入了未知来源的伪造数据,模拟了真实世界中深度伪造技术的多样性和不断变化的特性。此外,CDDB还提供了多种评估协议,从简单到复杂,从短序列到长序列,以全面评估检测方法的适应性和鲁棒性。
使用方法
使用CDDB数据集时,研究者可以采用多种方法进行深度伪造检测。首先,可以通过预训练模型在数据集上进行微调,以适应特定的深度伪造任务。其次,可以利用增量学习方法,逐步训练模型以应对新出现的深度伪造数据,同时避免灾难性遗忘。此外,CDDB还支持多任务学习,允许模型同时处理多个深度伪造检测任务,从而提高整体性能。
背景与挑战
背景概述
随着深度生成模型,如自动编码器[38]、生成对抗网络(GANs)[25]和生成归一化流(Glows)[18]的快速发展,深度伪造(deepfakes)技术变得无处不在。这导致了对隐私、社会安全和民主的潜在威胁。为了应对这一问题,许多深度伪造检测数据集(如[40, 44, 46, 21, 64, 19, 31])和检测技术(如[87, 4, 80, 57, 56, 5])被提出。然而,现有的大多数研究集中在静态设置下的深度伪造检测,即一次性提供大量相对同质的深度伪造数据。本文提出了一种动态(持续)设置下的深度伪造检测场景,即可能异质的深度伪造数据流随时间依次出现,而非一次性提供。
当前挑战
持续深度伪造检测(CDD)面临的主要挑战包括:1) 在现实世界场景中,深度伪造数据流可能来自已知或未知的生成模型,这增加了检测的复杂性;2) 构建过程中遇到的挑战,如数据流的异质性、隐私问题和存储限制,导致早期出现的深度伪造数据无法完全访问;3) 标准神经网络在处理新任务时,往往会忘记之前学习到的知识,即灾难性遗忘问题。此外,现有的基准测试主要集中在单一类型的深度伪造检测上,而本文提出的CDDB基准测试则涵盖了已知和未知生成模型的混合数据,更具现实挑战性。
常用场景
经典使用场景
CDDB数据集的经典使用场景在于模拟真实世界中不断出现的深度伪造(deepfake)图像和视频的检测。通过提供一个包含已知和未知生成模型的深度伪造数据流,CDDB旨在评估检测器在面对异质性深度伪造任务时的增量学习能力,特别是在防止灾难性遗忘方面的表现。
解决学术问题
CDDB数据集解决了学术界在深度伪造检测领域的一个重要问题,即如何应对现实世界中不断出现的新的深度伪造技术。传统的深度伪造检测方法通常假设数据是静态的,而CDDB通过模拟动态数据流,推动了对持续学习(continual learning)技术的研究,特别是在多任务增量学习(multi-task incremental learning)和知识蒸馏(knowledge distillation)方面的应用。
衍生相关工作
CDDB数据集的提出激发了一系列相关的研究工作,特别是在持续学习和深度伪造检测的交叉领域。例如,研究者们基于CDDB开发了多种增量学习方法,如iCaRL、LUCIR和DyTox,这些方法在处理多类别增量学习任务时表现出色。此外,CDDB还促进了关于如何有效管理内存预算(memory budget)和处理类别不平衡问题的研究,这些研究成果对于提升深度伪造检测系统的鲁棒性和效率具有重要意义。
以上内容由遇见数据集搜集并总结生成


