Evaluation_Dataset
收藏Hugging Face2025-01-18 更新2025-01-19 收录
下载链接:
https://huggingface.co/datasets/MMDocIR/Evaluation_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
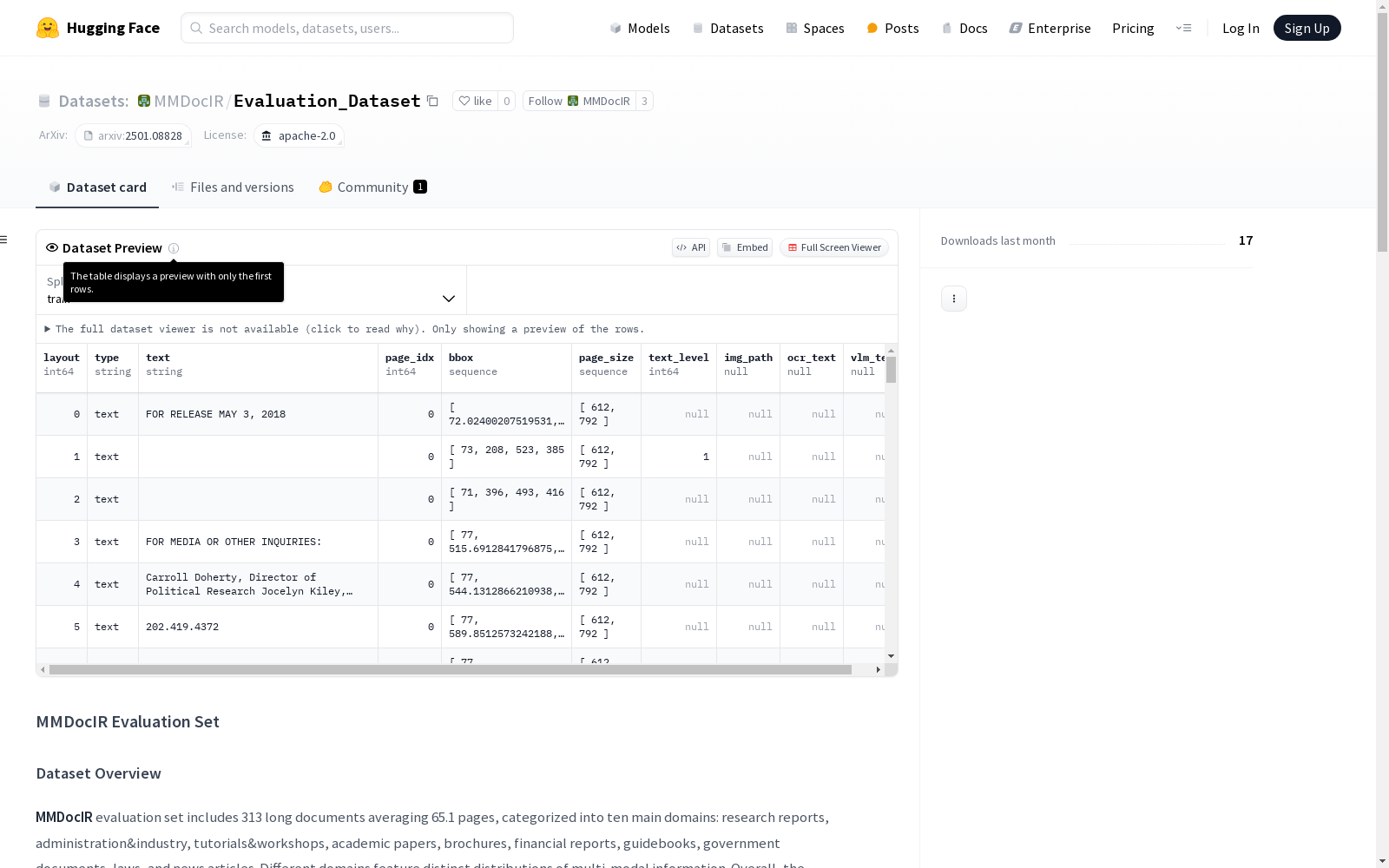
MMDocIR评估数据集包含313个长文档,平均每份文档有65.1页,涵盖十个主要领域:研究报告、行政与工业、教程与研讨会、学术论文、宣传册、财务报告、指南、政府文件、法律和新闻文章。文档中的多模态信息分布为:文本(60.4%)、图像(18.8%)、表格(16.7%)和其他模态(4.1%)。数据集包含1,658个问题,2,107个页面标签和2,638个布局标签。问题的回答需要跨模态理解、多页证据和多布局推理。数据集将用于2025年Web Conference的多模态信息检索挑战(MIRC)。数据集结构包括问题文件、页面截图、布局图像、页面内容和布局内容等。
The MMDocIR evaluation dataset consists of 313 long documents, with an average of 65.1 pages per document, covering ten major domains: research reports, administrative and industrial documents, tutorials and symposia, academic papers, brochures, financial reports, guidelines, government documents, legal documents, and news articles. The multimodal information distribution within the documents is as follows: text (60.4%), images (18.8%), tables (16.7%), and other modalities (4.1%). The dataset contains 1,658 questions, 2,107 page-level labels, and 2,638 layout-level labels. Answering these questions demands cross-modal comprehension, multi-page evidence-based reasoning, and multi-layout reasoning. This dataset will be used for the Multimodal Information Retrieval Challenge (MIRC) at the 2025 Web Conference. The dataset structure includes question files, page screenshots, layout images, page content, layout content, and other related components.
创建时间:
2025-01-14
搜集汇总
数据集介绍
构建方式
MMDocIR评估数据集构建于313份长文档之上,平均每份文档包含65.1页,涵盖研究报告、行政管理与工业、教程与研讨会、学术论文、宣传册、财务报告、指南、政府文件、法律和新闻文章等十大领域。数据集的构建过程中,文档被细致地标注了多模态信息的分布,包括文本、图像、表格及其他模态。此外,数据集还包含了1658个问题、2107个页面标签和2638个布局标签,这些问题和标签的分布进一步体现了多模态信息检索的复杂性。
使用方法
MMDocIR评估数据集的使用方法主要围绕多模态信息检索任务展开。用户可以通过`MMDocIR_questions.jsonl`文件获取所有问题及其相关信息,利用`page_images.rar`和`layout_images.rar`中的图像数据进行视觉信息检索,同时结合`page_content`和`layout_content`中的文本和布局信息进行综合分析。该数据集特别适用于评估多模态信息检索系统在处理长文档时的性能,尤其是在跨模态理解、多页证据整合和多布局推理等方面的能力。
背景与挑战
背景概述
MMDocIR评估数据集由Kuicai Dong等研究人员于2025年创建,旨在为多模态信息检索领域提供基准测试工具。该数据集包含313份长文档,涵盖研究报告、行政与工业文件、教程与研讨会材料、学术论文、宣传册、财务报告、指南、政府文件、法律文件及新闻文章等十大领域。文档平均长度为65.1页,多模态信息分布为文本(60.4%)、图像(18.8%)、表格(16.7%)及其他模态(4.1%)。数据集包含1,658个问题、2,107个页面标签和2,638个布局标签,问题回答所需模态分布为文本(44.7%)、图像(21.7%)、表格(37.4%)及布局/元数据(11.5%)。该数据集为2025年Web Conference的多模态信息检索挑战赛(MIRC)提供评估支持,推动了多模态推理与上下文理解的研究进展。
当前挑战
MMDocIR数据集在解决多模态信息检索问题时面临多重挑战。首先,254个问题需要跨模态理解,要求模型能够整合文本、图像和表格等多种信息源。其次,313个问题涉及跨页证据检索,模型需具备长文档上下文处理能力。此外,637个问题要求基于多个布局进行推理,增加了模型对复杂文档结构的理解难度。在数据集构建过程中,研究人员需处理长文档的多模态信息标注,确保标注的准确性与一致性,同时还需平衡不同领域文档的多样性,以提升数据集的泛化能力。这些挑战共同推动了多模态信息检索技术的创新与发展。
常用场景
经典使用场景
MMDocIR数据集在多模态信息检索领域具有广泛的应用场景,尤其是在处理长文档的复杂信息检索任务中。该数据集通过包含多种模态(如文本、图像、表格等)的文档,为研究者提供了一个理想的测试平台,用于评估和开发能够处理多模态信息的检索系统。特别是在需要跨模态理解和多页证据推理的场景中,该数据集展现了其独特的价值。
解决学术问题
MMDocIR数据集解决了多模态信息检索中的多个关键学术问题。首先,它通过提供丰富的多模态数据,帮助研究者开发能够同时处理文本、图像和表格的检索模型。其次,数据集中的复杂问题设计(如跨模态理解、多页证据推理等)挑战了现有模型的局限性,推动了多模态推理和上下文理解技术的发展。此外,该数据集还为长文档的信息检索提供了基准,填补了该领域的空白。
实际应用
在实际应用中,MMDocIR数据集可用于开发智能文档管理系统,特别是在需要处理大量多模态信息的场景中,如法律文档分析、金融报告解读、学术论文检索等。通过利用该数据集训练的模型,企业可以更高效地检索和分析长文档中的关键信息,提升工作效率。此外,该数据集还可用于教育领域,帮助学生和研究人员快速定位和理解复杂文档中的相关内容。
数据集最近研究
最新研究方向
在信息检索领域,多模态数据的融合与理解正成为研究热点。MMDocIR数据集以其丰富的多模态信息(文本、图像、表格及布局)和复杂的跨模态推理需求,为多模态信息检索技术提供了极具挑战性的评估基准。该数据集不仅涵盖了十个主要领域的文档,还包含大量需要跨页、跨布局推理的问题,推动了多模态检索模型在长文档处理中的发展。作为2025年Web Conference多模态信息检索挑战赛(MIRC)的官方评估集,MMDocIR将进一步促进学术界和工业界在跨模态理解、上下文推理及多模态融合技术上的创新。其发布将为多模态检索领域的研究提供重要的数据支持,并推动相关技术在金融、法律、新闻等实际场景中的应用。
以上内容由遇见数据集搜集并总结生成


