ted-translation-decisions-en-zh
收藏Hugging Face2025-12-30 更新2025-12-31 收录
下载链接:
https://huggingface.co/datasets/yipyany/ted-translation-decisions-en-zh
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含从TED Talks中提取的精选英汉翻译决策点。与提供完整转录或逐句字幕不同,该数据集专注于需要进行非平凡翻译判断的特定单词或短语。每个条目明确分离了决策发生的上下文和需要解释的目标单词或短语。数据集的目标是使人类翻译判断变得明确和可检查。数据集适用于研究人类翻译决策、翻译教学和示例、跨语言细微差别的定性分析、解释导向或基于批判的翻译任务以及翻译选择的偏好学习。
创建时间:
2025-12-22
原始信息汇总
TED Translation Decision Dataset (EN–ZH 英-简中) 数据集概述
数据集基本信息
- 数据集名称:TED Translation Decision Dataset (EN–ZH 英-简中)
- 许可协议:cc-by-nc-4.0
- 任务类别:翻译
- 标签:翻译、中文、英文、语言学、标注
- 数据规模:1K<n<10K
- 更新频率:每日更新
数据集来源与作者
- 翻译来源:所有翻译均选自官方TED英译简中字幕翻译,由Yip Yan YEUNG提供。
- 内容性质:所有条目均为纯粹的人工创作翻译和翻译决策,未经AI生成或后编辑。
- 译者信息:译者官方TED个人资料可访问:https://www.ted.com/profiles/33356256/translator
- 反馈联系:欢迎通过LinkedIn提供反馈:https://www.linkedin.com/in/yipyanyeung/
数据集摘要
本数据集包含从TED演讲中提取的精选英中翻译决策点。数据集不提供完整转录或逐句字幕,而是聚焦于需要进行非平凡翻译判断的特定单词或短语。每个条目明确将决策发生的上下文与需要解释的目标词或短语分开。数据集的目标是使人工翻译判断变得明确且可检查。
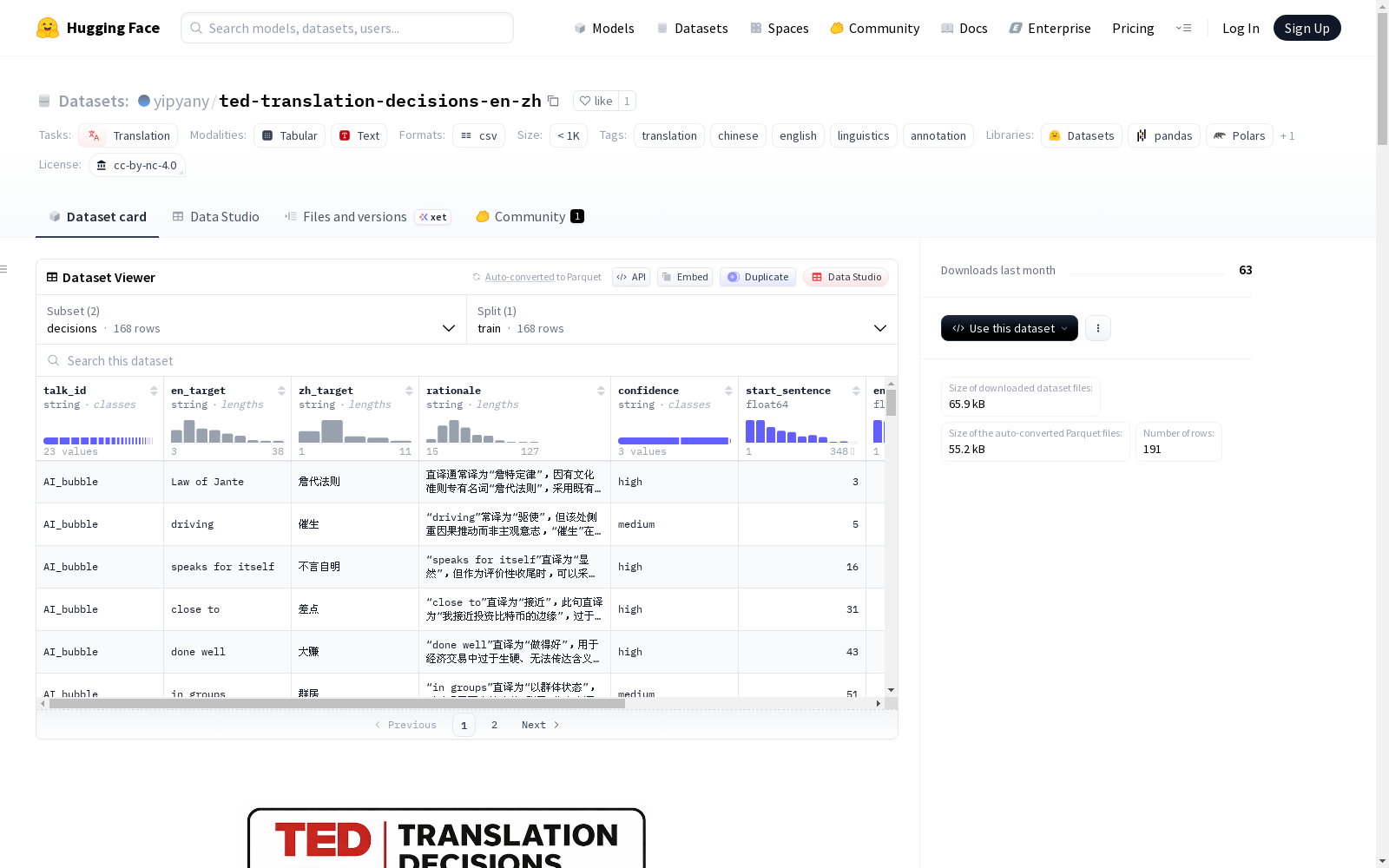
数据集结构
数据集包含两个配置:
- 配置名称:decisions
- 数据文件:decision.csv
- 数据分割:train
- 配置名称:talk_meta
- 数据文件:meta.csv
- 数据分割:train
数据字段说明
| 字段名 | 描述 |
|---|---|
talk_id |
TED演讲标识符 |
en_target |
做出翻译决策的单词或短语 |
zh_target |
目标词选定的中文翻译 |
rationale |
翻译决策的人工书面解释 |
confidence |
译者自评置信度(high / medium / low) |
start_sentence |
原始字幕中的起始句子索引 |
end_sentence |
原始字幕中的结束句子索引 |
en_context |
提供上下文的英文字幕句子 |
zh_context |
对应的中文字幕翻译 |
置信度标签说明
- high:稳定、规范或广泛接受的翻译选择。
- medium:依赖于上下文或具有合理替代方案的风格选择。
- low:根据译者知识进行了研究,可能被特定领域的专业人士替换或更新。
- 注意:置信度不是对翻译质量的评估,而是决策确定性的指标。
设计原则与特点
- 稀疏但高密度:仅包含有意义的决策片段。
- 上下文-目标分离:上下文=决策发生的位置;目标=决策内容。
- 以人为中心的标注:注释解释了每个选择背后的理由。
- 反映翻译判断:数据集捕捉译者如何思考,而不仅仅是他们产出了什么。
数据示例
演讲示例:Is the AI bubble about to burst? (Henrik Zeberg)
- 目标:Law of Jante → 詹代法则 决策类型:文化概念/既定术语 理由:虽然可以使用“詹特定律”等字面翻译,但该概念在中文中有一个作为文化规范的广泛接受的名称。因此使用既定翻译“詹代法则”。
- 目标:driving → 催生 决策类型:语义细微差别(因果关系与能动性) 理由:此处动词“driving”强调因果影响而非有意的能动性。“催生”比“驱使”等字面动词更能自然地传达这种细微差别。
预期用途
适用场景
- 研究人工翻译决策过程
- 翻译教学与示例
- 跨语言细微差别的定性分析
- 面向解释或基于批判的翻译任务
- 翻译选择的偏好学习
不适用场景
- 训练大规模机器翻译模型
- 翻译准确性基准测试
数据来源与许可
- 来源:官方TED演讲字幕
- 翻译:由Yip Yan YEUNG创作的人工中文字幕
- 原始内容:© TED Conferences, LLC
- 使用说明:本数据集为研究和教育目的而共享。用户需负责遵守TED的字幕使用指南。
局限性说明
- 设计上规模较小,优先考虑可解释性而非规模。
- 主观判断是固有且有意为之的。
- 标注反映单一译者的视角。
- 基于字幕的翻译可能与书面文本翻译规范不同。
- 这些局限性被视为数据集预期目的的特性。
引用方式
如果使用本数据集,请引用为:
TED Curated Translation Decision Dataset (EN–ZH).
Curated human translation decisions with explicit context and rationale.
搜集汇总
数据集介绍
构建方式
在跨语言翻译研究领域,构建能够揭示人类译者决策过程的数据集具有重要价值。本数据集从TED官方英译简中字幕中精心提取翻译决策点,聚焦于那些需要非平凡判断的词汇或短语。其构建过程并非简单对齐完整句子,而是通过分离上下文与目标单元,将每个决策锚定在原字幕的句子索引与语境文本中。数据条目由译者本人标注,包含决策目标、所选译法及背后理据,同时标注了译者的自信程度,从而形成稀疏但高信息密度的结构化记录。
特点
该数据集的核心特点在于其专注于翻译决策的显性化与可解释性。与传统的平行语料不同,它并非提供完整的句对翻译,而是呈现翻译过程中针对特定语言点的判断,例如术语选择、习语处理、语义细微差别及风格自然度等。每个条目明确区分了决策发生的语境与需要解读的目标片段,并附有人工撰写的决策理由。这种设计使得翻译行为背后的认知过程得以被观察与分析,为研究人类翻译的决策机制提供了独特的微观视角。
使用方法
本数据集适用于翻译学、计算语言学及相关领域的定性研究与教学实践。研究者可借助其分析跨语言转换中的理据模式,探索翻译决策的影响因素,或用于翻译教学中的案例研讨。在技术应用层面,它可为解释性翻译任务、翻译偏好学习或翻译批评分析提供支持。使用时,需注意其数据规模较小且基于字幕翻译的特性,因此不适用于训练大规模机器翻译模型或作为通用翻译准确性的基准测试数据,而应着重于其揭示人类翻译判断的深层价值。
背景与挑战
背景概述
在机器翻译研究日益关注数据质量与可解释性的背景下,TED翻译决策数据集(EN–ZH)应运而生,由译者Yip Yan YEUNG基于TED官方英译简中字幕精心构建。该数据集聚焦于翻译实践中非平凡的决策点,旨在显式捕捉人类译者的思维过程,而非简单的句子级映射。其核心研究问题在于揭示翻译决策中的术语选择、语义细微差别及风格自然性等关键环节,为翻译学、计算语言学及人工智能领域提供了宝贵的细粒度分析资源,推动了从黑箱输出到透明决策的范式转变。
当前挑战
该数据集致力于解决翻译领域中对决策过程可解释性的深层挑战,传统平行语料往往掩盖了译者面对文化概念、习惯表达时的具体权衡。在构建过程中,挑战主要体现在如何从连续字幕流中精准提取高密度决策片段,并保持语境与目标的清晰分离。此外,字幕翻译受限于口语表达与时间同步,其句法边界和风格选择与书面文本存在差异,这要求标注必须忠实反映口语化转换的特殊性。数据集的主观性与小规模设计虽为特色,却也带来了视角单一与规模有限的挑战。
常用场景
经典使用场景
在翻译研究与语言学领域,该数据集为探究人类译者的决策过程提供了珍贵资源。其核心应用聚焦于分析翻译中的非平凡判断点,如术语选择、习语处理及语义细微差别,而非提供完整的平行句对。通过将上下文与目标短语分离,并辅以译者自述的决策依据,该数据集使翻译思维过程变得可观察与可分析,特别适用于翻译教学中的案例研讨与跨语言对比研究。
实际应用
在实际应用中,该数据集服务于翻译教育与专业培训,为学员提供真实场景下的决策范例,帮助其理解语境如何影响翻译策略。同时,它可用于开发翻译辅助工具,例如基于实例的翻译记忆系统或偏好学习模型,这些工具能借鉴人类译者的决策模式,为机器翻译输出提供可解释的改进建议。此外,在本地化与跨文化传播领域,该数据集中的文化概念翻译案例为处理特定领域术语提供了参考。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在翻译过程建模与可解释人工智能领域。例如,研究者利用其构建翻译决策分类框架,将选择依据归纳为术语规范、语义调整及文体适应等类别。另有工作基于其结构化注释,训练模型预测翻译偏好或生成决策理由,从而增强机器翻译系统的透明性。这些研究不仅深化了对翻译认知机制的理解,也推动了人机协同翻译向更精细化、可解释的方向发展。
以上内容由遇见数据集搜集并总结生成


