tner/wnut2017
收藏Hugging Face2022-08-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/tner/wnut2017
下载链接
链接失效反馈官方服务:
资源简介:
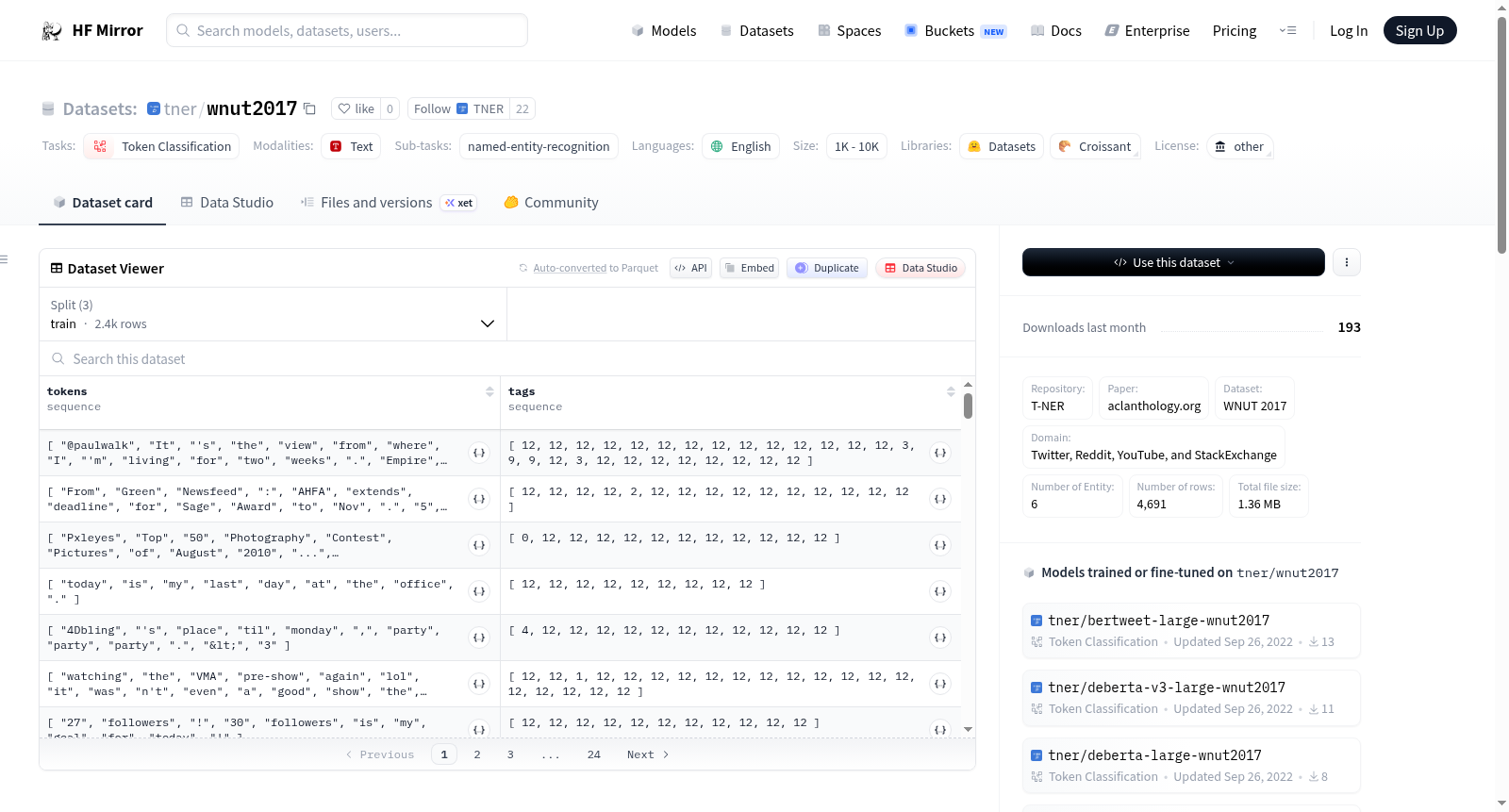
WNUT 2017数据集是一个用于命名实体识别(NER)任务的数据集,主要来源于社交媒体平台如Twitter、Reddit、YouTube和StackExchange。数据集中包含6种实体类型:creative-work、corporation、group、location、person和product。数据集的结构包括训练集、验证集和测试集,分别包含2395、1009和1287个样本。数据集的标签包括B-和I-前缀,分别表示实体的开始和内部。
The WNUT 2017 dataset is a benchmark dataset for named entity recognition (NER) tasks, primarily sourced from social media platforms including Twitter, Reddit, YouTube, and StackExchange. It covers six entity types: creative-work, corporation, group, location, person, and product. The dataset is split into training, validation, and test sets, which contain 2395, 1009, and 1287 samples respectively. It adopts the BIO labeling schema, where the B- and I- prefixes denote the beginning and internal parts of an entity respectively.
提供机构:
tner
原始信息汇总
数据集概述
数据集描述
- 名称: WNUT 2017
- 领域: Twitter, Reddit, YouTube, StackExchange
- 实体数量: 6
- 实体类型:
creative-work,corporation,group,location,person,product
数据集结构
数据实例
- 示例: json { tokens: [@paulwalk, It, "s", the, view, from, where, I, "m", living, for, two, weeks, ., Empire, State, Building, =, ESB, ., Pretty, bad, storm, here, last, evening, .], tags: [12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 3, 9, 9, 12, 3, 12, 12, 12, 12, 12, 12, 12, 12] }
标签ID
- 标签映射: python { "B-corporation": 0, "B-creative-work": 1, "B-group": 2, "B-location": 3, "B-person": 4, "B-product": 5, "I-corporation": 6, "I-creative-work": 7, "I-group": 8, "I-location": 9, "I-person": 10, "I-product": 11, "O": 12 }
数据分割
| 名称 | 训练 | 验证 | 测试 |
|---|---|---|---|
| wnut2017 | 2395 | 1009 | 1287 |
搜集汇总
数据集介绍
构建方式
在社交媒体文本挖掘领域,WNUT 2017数据集的构建源于对新兴实体识别的迫切需求。该数据集通过精心筛选来自Twitter、Reddit、YouTube和StackExchange等平台的用户生成内容,由专业标注者依据六种实体类型——创意作品、公司、团体、地点、人物和产品——进行细粒度标注。标注过程严格遵循BIO标注方案,确保了实体边界的精确性,最终形成了包含训练集、验证集和测试集的完整语料库,为新兴实体识别任务提供了坚实的实验基础。
特点
WNUT 2017数据集的核心特点在于其专注于新兴和罕见实体的识别挑战。数据源自多样化的社交媒体平台,文本风格自然且噪声显著,涵盖了创意作品、公司等六类实体,充分反映了真实场景中实体表达的复杂性和动态性。该数据集规模适中,标注质量高,实体分布均衡,为模型在嘈杂文本中的泛化能力提供了严格的测试环境,推动了命名实体识别技术在前沿应用中的发展。
使用方法
使用WNUT 2017数据集时,研究者可通过Hugging Face平台便捷加载,并利用其预划分的训练、验证和测试集进行模型训练与评估。数据以token序列和对应标签ID的形式呈现,支持直接应用于基于深度学习的命名实体识别模型。用户可参考提供的标签映射字典,结合T-NER等开源工具,实现端到端的实验流程,有效探索模型在识别新兴实体方面的性能与局限。
背景与挑战
背景概述
在自然语言处理领域,社交媒体文本的命名实体识别(NER)因其非正式语言和新兴实体而成为研究热点。WNUT 2017数据集于2017年由Leon Derczynski等学者在第三届噪声用户生成文本研讨会上发布,旨在解决新兴和罕见实体的检测与分类问题。该数据集覆盖Twitter、Reddit、YouTube和StackExchange等多平台文本,标注了创意作品、公司、团体、地点、人物和产品六类实体,为社交媒体文本的实体识别研究提供了重要基准,推动了噪声文本处理技术的发展。
当前挑战
WNUT 2017数据集面临的挑战主要体现在两个方面:在领域问题层面,社交媒体文本中的新兴实体常以非标准拼写、缩写或网络俚语形式出现,导致传统NER模型难以准确识别和分类,例如“kktny”这类罕见表面形式;在构建过程中,数据收集来自多源平台,文本噪声高、标注一致性差,且新兴实体定义模糊,增加了人工标注的难度和成本,影响了数据集的规模和泛化能力。
常用场景
经典使用场景
在社交媒体文本挖掘领域,WNUT 2017数据集作为新兴实体识别任务的基准,其经典使用场景聚焦于处理来自Twitter、Reddit等平台的嘈杂用户生成内容。研究者借助该数据集训练模型,以精准识别非正式文本中涌现的罕见实体,如新兴产品名称或网络流行语,从而推动自然语言处理技术在动态语境下的适应性发展。
衍生相关工作
围绕WNUT 2017数据集,学术界衍生出一系列经典研究工作。例如,T-NER项目将其整合为标准化评估框架,促进了跨领域实体识别模型的比较与优化。后续研究则基于该数据集探索了迁移学习、少样本学习等前沿方法,以应对新兴实体的稀疏性问题,这些工作共同推动了嘈杂文本处理技术的演进,并为后续共享任务设立了重要参照标准。
数据集最近研究
最新研究方向
在社交媒体与新兴文本处理领域,WNUT 2017数据集作为新兴实体识别任务的基准,持续推动着自然语言处理的前沿探索。当前研究聚焦于利用预训练语言模型与迁移学习技术,提升模型对社交媒体文本中罕见及新兴实体的泛化能力,尤其在跨平台数据如Twitter、Reddit的噪声环境下,如何有效识别“创造性作品”或“新兴产品”等动态实体类别成为热点。随着社交媒体事件实时爆发与网络新词涌现,该数据集的研究深化了实体链接、领域自适应及低资源学习方法的创新,为舆情分析、信息抽取等应用提供了关键支撑,体现了其在应对非规范文本挑战中的持久影响力。
以上内容由遇见数据集搜集并总结生成


