google/trueteacher
收藏TrueTeacher 数据集概述
数据集简介
TrueTeacher 是一个大规模合成数据集,用于训练事实一致性评估模型,由 Gekhman 等人在 2023 年的 TrueTeacher 论文中引入。
数据集详情
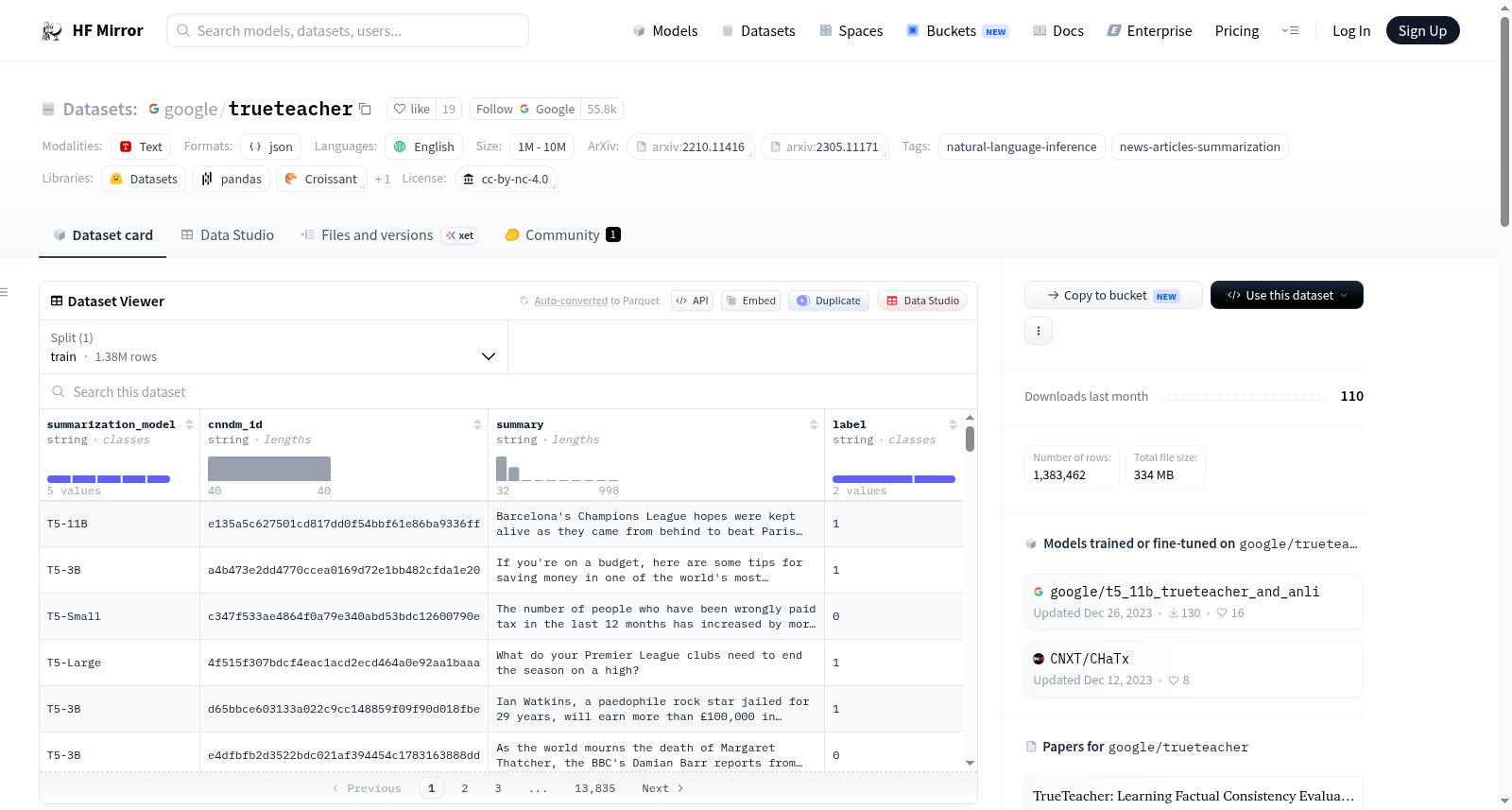
该数据集包含从 CNN/DailyMail 数据集的训练部分生成的模型摘要,这些摘要使用 FLAN-PaLM 540B 进行事实一致性标注。摘要由不同容量的摘要模型生成,这些模型是通过在 XSum 数据集上微调 T5 模型创建的。使用的模型容量包括:T5-11B、T5-3B、T5-large、T5-base 和 T5-small。
数据格式
数据以 JSON 行格式存储,包含以下键:
"summarization_model":用于生成摘要的摘要模型。"cnndm_id":CNN/DailyMail 数据集的原始 ID,用于检索相应的文章。"summary":模型生成的摘要。"label":二进制标签(1 - 事实一致,0 - 事实不一致)。
示例数据项: json { "summarization_model": "T5-11B", "cnndm_id": "f72048a23154de8699c307e2f41157abbfcae261", "summary": "Childrens brains are being damaged by prolonged internet access, a former childrens television presenter has warned.", "label": "1" }
数据集加载
使用数据集时,需要从 CNN/DailyMail 数据集中获取相关文档。以下代码可用于此目的: python from datasets import load_dataset from tqdm import tqdm
trueteacher_data = load_dataset("google/trueteacher", split=train) cnn_dailymail_data = load_dataset("cnn_dailymail", version="3.0.0", split=train) cnn_dailymail_articles_by_id = {example[id]: example[article] for example in cnn_dailymail_data} trueteacher_data_with_documents = [] for example in tqdm(trueteacher_data): example[document] = cnn_dailymail_articles_by_id[example[cnndm_id]] trueteacher_data_with_documents.append(example)
预期用途
该数据集适用于英语研究用途(非商业),推荐用于训练摘要的事实一致性评估模型。
超出范围的用途
任何违反 cc-by-nc-4.0 许可证的用途,以及非英语的使用情况。
引用
如果在研究出版物中使用此数据集,请引用 TrueTeacher 论文以及提到的 CNN/DailyMail、XSum、T5 和 FLAN 论文。
@misc{gekhman2023trueteacher, title={TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models}, author={Zorik Gekhman and Jonathan Herzig and Roee Aharoni and Chen Elkind and Idan Szpektor}, year={2023}, eprint={2305.11171}, archivePrefix={arXiv}, primaryClass={cs.CL} }