ScaleCUA
收藏Hugging Face2026-04-30 更新2026-05-01 收录
下载链接:
https://huggingface.co/datasets/cua-lite/ScaleCUA
下载链接
链接失效反馈官方服务:
资源简介:
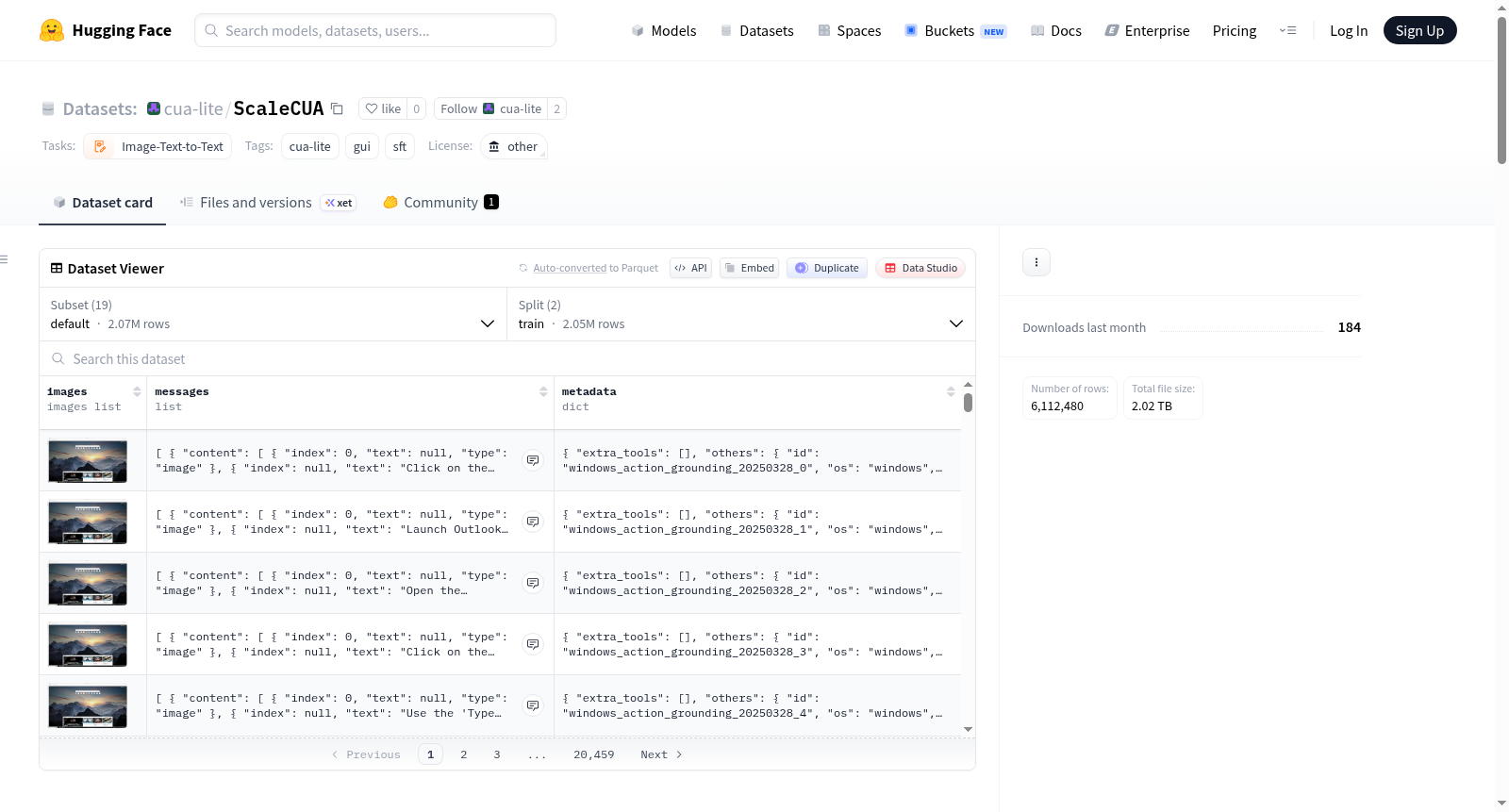
ScaleCUA数据集是一个经过预处理的大规模多平台(桌面、移动、网页)GUI数据集,涵盖理解、grounding(动作、边界框、点)和导航等多种任务类型。数据集来源于OpenGVLab/ScaleCUA-Data和zyliu/ScaleCUA-Data-Understanding,包含丰富的图像和结构化消息,每条记录都带有元数据信息。数据按平台和任务类型组织,分为训练集和验证集,具体统计信息包括各平台和任务类型的样本数量。数据集以Parquet文件格式存储,支持通过Hugging Face的datasets库加载。此外,数据集还支持本地镜像和SFT导出,便于本地工作流使用。
The ScaleCUA dataset is a preprocessed large-scale multi-platform (desktop, mobile, web) GUI dataset covering various task types such as understanding, grounding (actions, bounding boxes, points), and navigation. The dataset originates from OpenGVLab/ScaleCUA-Data and zyliu/ScaleCUA-Data-Understanding, containing rich images and structured messages, with each record accompanied by metadata. The data is organized by platform and task type, divided into training and validation sets, with detailed statistics including sample counts for each platform and task type. The dataset is stored in Parquet file format and supports loading via Hugging Faces datasets library. Additionally, the dataset supports local mirroring and SFT export for convenient local workflow usage.
创建时间:
2026-04-29
原始信息汇总
数据集概述:cua-lite/ScaleCUA
基本信息
- 数据集名称: cua-lite/ScaleCUA
- 许可证: 其他(参见原始数据集许可)
- 任务类型: 图像文本到文本 (image-text-to-text)
- 标签: cua-lite, gui, sft
- 来源: 由 OpenGVLab/ScaleCUA-Data 和 zyliu/ScaleCUA-Data-Understanding 预处理而成
数据集结构
数据格式
- 数据文件格式: Parquet
- 数据拆分: 训练集 (train) 和 验证集 (validation)
- 每条记录包含:
images: 嵌入的 PNG/JPEG 字节图像列表messages: OpenAI 风格的多轮对话结构,包含角色和结构化内容metadata: 元数据结构体,包含平台、任务类型、额外工具、有效动作等信息
坐标处理
- 消息中的坐标值已归一化为
[0, 1000]的整数范围
平台与任务类型
平台 (Platform)
- desktop (桌面端)
- mobile (移动端)
- web (网页端)
任务类型 (Task Type)
- understanding (理解)
- caption (描述)
- screen_transition (屏幕转换)
- user_intention (用户意图)
- grounding.action (动作定位)
- grounding.bbox (边界框定位)
- grounding.point (点定位)
- navigation (导航)
- navigation (导航)
- planning (规划)
配置 (Config)
数据集可通过 Hugging Face datasets 库按以下方式加载:
- 全部数据: 直接加载整个数据集
- 按平台筛选: 如
desktop、mobile、web - 按平台+任务类型组合: 如
desktop@grounding.action、mobile@understanding - 加载后过滤: 可通过
metadata.platform、metadata.task_type等字段过滤
数据集统计
桌面端 (Desktop)
| 任务类型 | 变体 | 训练集 | 验证集 |
|---|---|---|---|
| grounding.action | grounding.action | 482,836 | 2,000 |
| grounding.bbox | grounding.bbox | 335,739 | 2,000 |
| grounding.point | grounding.point | 104,697 | 2,000 |
| navigation | navigation | 31,066 | 584 |
| navigation | planning | 45,408 | 915 |
| understanding | caption | 5,529 | 119 |
| understanding | screen_transition | 5,657 | 110 |
| understanding | user_intention | 5,648 | 113 |
移动端 (Mobile)
| 任务类型 | 变体 | 训练集 | 验证集 |
|---|---|---|---|
| grounding.action | grounding.action | 110,455 | 2,000 |
| grounding.bbox | grounding.bbox | 106,508 | 2,000 |
| grounding.point | grounding.point | 3,732 | 77 |
| navigation | navigation | 12,263 | 238 |
| navigation | planning | 9,157 | 162 |
| understanding | caption | 22,924 | 499 |
| understanding | screen_transition | 14,994 | 318 |
| understanding | user_intention | 15,002 | 310 |
网页端 (Web)
| 任务类型 | 变体 | 训练集 | 验证集 |
|---|---|---|---|
| grounding.action | grounding.action | 292,770 | 2,000 |
| grounding.bbox | grounding.bbox | 227,013 | 2,000 |
| grounding.point | grounding.point | 72,343 | 1,533 |
| navigation | navigation | 70,469 | 1,515 |
| navigation | planning | 8,974 | 212 |
| understanding | caption | 30,874 | 631 |
| understanding | screen_transition | 15,846 | 379 |
| understanding | user_intention | 15,915 | 310 |
其他统计信息
- 总唯一图像数: 642,662
- 图像存储大小: 366.13 GB
数据拆分说明
- 验证集 (validation): 域内保留样本,不用于训练
- 测试集 (test): 保留用于域外基准数据集评估
本地镜像与 SFT 导出
- 支持通过
lite.data.hub_download将数据集镜像到本地规范布局 - 本地 Parquet 文件中
images字段为字符串列表,图像字节提取到内容寻址图像存储中
搜集汇总
数据集介绍
构建方式
ScaleCUA数据集由OpenGVLab与zyliu联合构建,整合了来自ScaleCUA-Data与ScaleCUA-Data-Understanding两大源数据,经过预处理形成统一的cua-lite版本。数据以Parquet格式存储,按平台类型(桌面端、移动端、网页端)与任务类别(理解、接地动作、接地边界框、接地点、导航)进行层级化组织,每个平台-任务组合对应一个独立的HuggingFace配置项,便于精准检索与加载。数据划分包含训练集与验证集,其中验证集为分布内留出样本。
特点
该数据集的核心特色在于其多平台、多任务协同的GUI智能体训练框架,覆盖桌面、移动、网页三大主流交互环境,并整合了界面理解、元素定位、动作预测、导航规划等五种关键能力。每条样本携带丰富的元数据结构,包括平台、任务类型、额外工具与有效动作等信息,支持基于元数据的灵活筛选。图像与多轮对话消息紧密耦合,坐标值归一化为0至1000的整数,具备极佳的跨模型兼容性。
使用方法
用户可通过HuggingFace datasets库便捷加载,支持按整体数据集、单一平台或特定平台-任务组合进行调用,例如load_dataset('cua-lite/ScaleCUA', 'desktop@grounding.action')。加载后可通过metadata.platform与metadata.task_type字段进行二次过滤。对于本地微调与SFT导出工作流,数据集提供了镜像脚本,可将Parquet中的图像字节提取至内容寻址存储,并生成引用相对路径的本地副本,显著提升大规模训练的效率。
背景与挑战
背景概述
在图形用户界面(GUI)智能体研究领域,多平台、多任务类型的大规模数据集是推动模型从感知到执行能力跃升的关键。ScaleCUA数据集由OpenGVLab与zyliu等机构于2024年协同创建,旨在弥合GUI理解与自动化操作之间的鸿沟。该数据集覆盖桌面、移动端与网页三大平台,围绕理解、接地定位(动作/边界框/点)及导航五大任务类型,系统性地构建了超过百万级的图文交互样本,为训练具备跨平台感知与执行能力的多模态大模型提供了标准化基准。其影响力在于突破了以往GUI数据集规模小、任务单一的局限,首次实现了多平台多任务数据的统一封装与高效调用,显著推动了GUI智能体从学术研究向工业应用的转化。
当前挑战
ScaleCUA面临的首要挑战在于跨平台GUI环境的高度异质性,不同设备的分辨率、控件布局与交互逻辑要求模型具备泛化至未见界面的鲁棒能力,而数据集中各平台样本分布不均(如桌面样本远超移动端)可能引入系统性偏差。构建过程中,如何从海量动态GUI界面中精准标注多样化的任务类型(如区分用户意图、屏幕过渡与动作接地)成为技术瓶颈,需依赖自动化流水线与人工校验的协同。此外,超36万张独立图片与复杂嵌套的元数据结构对数据存储与加载效率提出了严峻考验,驱动了去重算法与内容寻址镜像策略的研发,以确保规模化模型训练时的数据吞吐稳定性。
常用场景
经典使用场景
在图形用户界面(GUI)自动化与智能体研究的广阔领域中,ScaleCUA数据集以其跨桌面、移动端和网页三大平台的宏大规模与多任务类型覆盖,成为训练与评估视觉语言模型(VLM)在GUI理解与操作任务上表现的核心基准。该数据集最经典的使用场景在于构建能够感知界面元素、理解用户意图并执行精确交互的通用GUI智能体。具体而言,研究者利用其包含的grounding.action、grounding.bbox、grounding.point等子任务数据,训练模型从自然语言指令中定位并操作特定界面组件;同时借助understanding和navigation类别,培养模型对屏幕状态变迁的深层语义理解与多步规划能力。这种多平台、多任务的统一框架,使得ScaleCUA成为从单一操作预测迈向全场景自主交互研究的关键数据基石。
解决学术问题
ScaleCUA数据集的构建直面了GUI自动化研究中的核心困境:缺乏大规模、跨平台且标注一致的指令操控训练语料。在此之前,学术界的相关数据集往往局限于单一平台(如仅网页或仅移动端),或只涵盖点击、输入等少数基础操作类型,难以支撑对视觉模型泛化能力的系统性评估。该数据集通过提供覆盖桌面、移动、网页三大生态系统的完整数据,并统一规划了界面理解、元素定位(通过边界框、点坐标、动作类型三种方式)、屏幕导航和意图分类五大任务规范,有效解决了跨平台环境下的任务定义碎片化问题。其深远意义在于为构建真正的通用GUI智能体奠定了数据基础,推动了从特定应用脚本到自主学习人机交互范式转变的学术进程。
衍生相关工作
ScaleCUA数据集的发布催生了一系列具有代表性的后续研究工作,显著推动了GUI智能体领域的边界扩展。在预训练范式层面,研究者基于其多任务标注信息,探索了在统一视觉-语言模型上同时优化界面理解与操作定位能力的新型联合训练策略,产生了如CUA-Lite等轻量化高效模型系列。在评估基准构建方面,该数据集常被用作抽取样本或提供训练数据,以构造用于考察模型泛化能力的跨平台测试集,例如在未见的应用程序界面或操作变体上评估模型鲁棒性。此外,针对导航任务中蕴含的多步决策属性,部分工作借鉴了其planning子集的数据结构,将强化学习与SFT(监督微调)结合,提出能够从错误中自我修正的交互式智能体框架,进一步释放了GUI自动化系统的实用潜能。
以上内容由遇见数据集搜集并总结生成


