fineweb-2_zsm
收藏Hugging Face2026-01-31 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/daniazie/fineweb-2_zsm
下载链接
链接失效反馈官方服务:
资源简介:
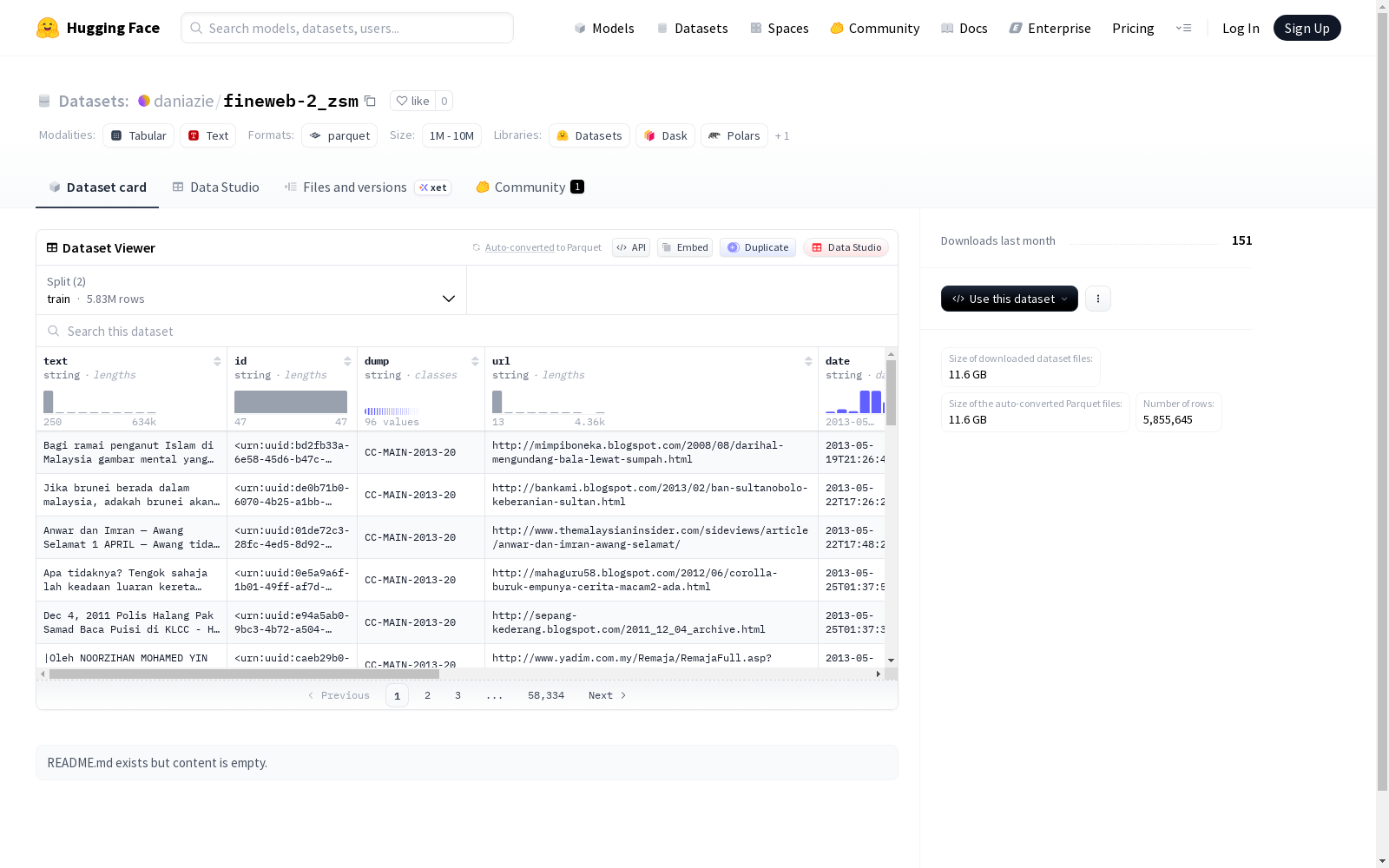
该数据集包含多个特征字段,包括文本内容(text)、唯一标识符(id)、数据来源信息(dump、url、date、file_path)、语言相关属性(language、language_score、language_script、top_langs)以及聚类信息(minhash_cluster_size)。数据集分为训练集和测试集,训练集包含5,833,369个样本,测试集包含22,276个样本。总下载大小为11,565,247,801字节,数据集总大小为20,670,325,131字节。数据文件按默认配置组织,训练集和测试集分别存储在指定的路径下。
创建时间:
2026-01-29
搜集汇总
数据集介绍
构建方式
在当今大规模语言模型蓬勃发展的背景下,FineWeb-2_zsm数据集应运而生,旨在为模型训练提供高质量、多样化的文本语料。其构建过程依托于对Common Crawl网络存档数据的系统性处理,通过一系列严谨的清洗与过滤流程,包括基于语言识别模型进行文本语言分类与评分、利用MinHash算法进行大规模去重以消除冗余内容,并整合了来源URL、时间戳及文件路径等丰富的元数据,最终形成了结构清晰、规模庞大的双语或多语言文本集合。
特点
该数据集的核心特点在于其卓越的数据质量与精细的结构化设计。它不仅提供了海量的训练样本,还通过`language_score`字段量化了文本的语言置信度,为研究者筛选特定语言数据提供了可靠依据。`minhash_cluster_size`字段则揭示了文本在全局语料中的重复程度,助力于数据多样性分析。数据集明确划分了训练集与测试集,并涵盖了文本内容、唯一标识符、来源信息及多语言标签等多个维度的特征,构成了一个信息完备、便于深度挖掘的语料库。
使用方法
对于致力于语言模型预训练或跨语言研究的学者而言,FineWeb-2_zsm数据集提供了直接且高效的使用路径。用户可通过Hugging Face数据集库加载,并利用其预定义的`train`与`test`分割进行模型训练与评估。在实际应用中,可依据`language`和`language_score`字段筛选出高置信度的目标语言文本,或利用`minhash_cluster_size`控制训练数据的重复性。丰富的元数据字段也支持对数据来源、时间分布等进行深入的统计分析,为模型训练策略的优化提供数据层面的洞察。
背景与挑战
背景概述
FineWeb-2_zsm作为大规模多语言文本数据集,其构建源于自然语言处理领域对高质量、多样化训练语料的迫切需求。该数据集由HuggingFace社区的研究团队主导开发,旨在为语言模型预训练提供广泛覆盖的文本资源。其核心研究问题聚焦于如何从海量网络数据中筛选出语言纯净、内容丰富的文本片段,以支持跨语言理解和生成任务的发展。该数据集的推出,显著丰富了开源语料库的多样性,为多语言模型的性能提升奠定了坚实基础。
当前挑战
FineWeb-2_zsm所针对的领域挑战在于解决多语言文本数据中普遍存在的噪声过滤、语言识别准确性以及内容重复性问题。在构建过程中,研究团队面临如何高效处理TB级原始网络数据、精确识别低资源语言的文本内容,以及平衡不同语言样本分布的技术难题。此外,确保数据去重算法的可靠性,同时维护文本的语义完整性,也是数据集构建中的关键挑战。
常用场景
经典使用场景
在自然语言处理领域,大规模文本数据集的构建是推动模型性能提升的关键。FineWeb-2_zsm作为一个多语言、高质量的网页文本数据集,其经典使用场景主要集中于训练和评估大型语言模型。研究者利用该数据集中的多样化文本内容,涵盖新闻、百科、论坛等多种来源,以增强模型的语言理解、生成和跨语言迁移能力。通过精细的预处理和语言标注,该数据集为模型提供了丰富的上下文信息,使其在文本补全、问答和摘要等任务中展现出卓越的泛化性能。
衍生相关工作
基于FineWeb-2_zsm数据集,衍生出多项经典研究工作,主要集中在数据清洗、模型预训练和评估框架的改进上。例如,研究者开发了更高效的文本去重算法,以减少训练数据中的冗余信息;同时,该数据集被用于训练如GPT系列和BERT变体等先进模型,推动了多语言和零样本学习的发展。这些工作不仅扩展了数据集的用途,还为后续研究提供了可复现的实验基础,促进了自然语言处理领域的持续创新。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模多语言文本数据集如fineweb-2_zsm正成为模型训练与评估的核心资源。该数据集以其丰富的语言多样性和精细的元数据标注,为跨语言理解与生成任务提供了坚实基础。前沿研究聚焦于利用其语言评分与聚类信息,探索低资源语言的表示学习,以缓解数据稀缺性问题。同时,结合时间戳与来源特征,学者们致力于分析网络文本的动态演化规律,推动时序语言模型的创新。这些探索不仅深化了对多语言数据分布的理解,也为构建更具包容性与适应性的智能系统指明了方向。
以上内容由遇见数据集搜集并总结生成


