BankChurners
收藏Hugging Face2025-12-06 更新2025-12-07 收录
下载链接:
https://huggingface.co/datasets/stivenmosheyoff/BankChurners
下载链接
链接失效反馈官方服务:
资源简介:
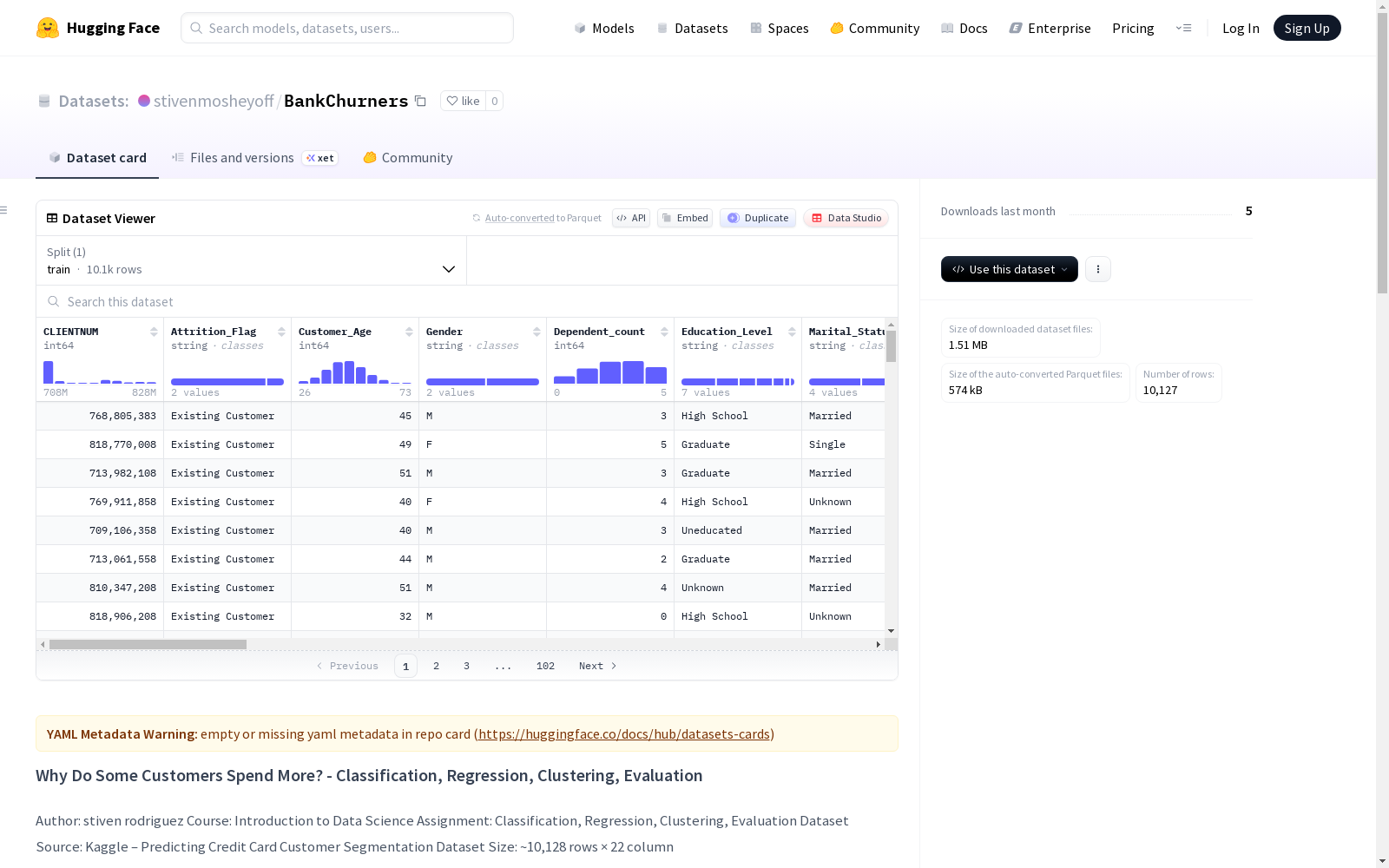
BankChurners数据集是一个用于预测信用卡客户流失和理解客户细分的分类、回归、聚类和评估数据集。数据集包含约10,128行和22列,经过清洗后保留了14列。数据集中包含客户的各种属性,如性别、教育水平、婚姻状况、收入类别、信用卡类型、信用额度等,以及客户行为数据,如不活跃月数、联系次数、交易金额等。数据集经过系统清洗、验证和过滤处理,确保数据质量。
The BankChurners dataset is a classification, regression, clustering and evaluation dataset intended for predicting credit card customer churn and understanding customer segmentation. It contains approximately 10,128 rows and 22 columns, with 14 columns retained after systematic data cleaning. The dataset includes diverse customer attributes such as gender, education level, marital status, income category, credit card type and credit limit, alongside customer behavioral data including months inactive, number of contacts, transaction amounts and other relevant metrics. The dataset has been processed through systematic cleaning, validation and filtering steps to guarantee high data quality.
创建时间:
2025-12-04
原始信息汇总
BankChurners 数据集概述
数据集基本信息
- 数据集名称: BankChurners
- 作者: stiven rodriguez
- 课程: Introduction to Data Science
- 任务: Classification, Regression, Clustering, Evaluation
- 数据来源: Kaggle – Predicting Credit Card Customer Segmentation
- 数据规模: 约 10,128 行 × 22 列
项目目标
预测客户流失并理解信用卡使用中的客户细分。
数据概览
最终数据集是经过系统性清洗、验证和筛选程序的结果。数据集中包含以下关键变量及其编码说明:
- Attrition_Flag: 客户是否留存(Existing Customer = 1, Attrited Customer = 0)
- Customer_Age: 客户年龄
- gender: 性别(male=1, female=2)
- Marital_Status: 婚姻状况(Married = 1, Single = 0)
- Education_Level: 教育水平(Uneducated = 1, High School = 2, College = 3, Graduate = 4, Post-Graduate = 5, Doctorate = 6)
- Income_Category: 收入水平(Less than $40K = 1, $40K - $60K = 2, $60K - $80K = 3, $80K - $120K = 4, $120K + = 5)
- Card_Category: 信用卡类型(Blue = 1, Silver = 2, Gold = 3, Platinum = 4)
- Months_on_book: 成为客户的月数
- Total_Relationship_Count: 客户在银行拥有的产品数量
- Months_Inactive_12_mon: 过去一年的非活跃月数
- Contacts_Count_12_mon: 客户联系银行的次数
- Credit_Limit: 信用额度((0-2.5k) = 0, (2.5k-5k) = 1, (5k-7.5k) = 2, (7.5k-10k) = 3, (10k-12.5k) = 4, (12.5k-17.5k) = 5, (17.5k-30k) = 6, (30k+) =7)
- Total_Revolving_Bal: 客户尚欠的金额
- Total_Trans_Amt: 总消费金额
- Total_Trans_Ct: 总交易次数
- Avg_Utilization_Ratio: 信用额度使用率
数据清洗总结
- 从原始22列中选择了14个相关列进行分析。
- 处理非信息性及重复数据。
- 处理缺失值,移除缺失列。
- 筛选掉收入为NaN的客户档案。
- 筛选掉不完整的客户档案(任期少于12个月)。
- 用“Unknown”填充缺失的“Stance”值。
- 在进行异常值分析前,将相关变量转换为数值格式。
- 异常值检测与处理。
搜集汇总
数据集介绍
构建方式
在金融科技与客户关系管理领域,BankChurners数据集源自Kaggle平台,旨在预测信用卡客户流失并理解客户细分。该数据集通过对原始22个字段进行系统化清洗与筛选,最终保留了14个关键特征列,涵盖了约10,128条客户记录。构建过程包括去除非信息性及重复数据、处理缺失值、过滤任职不足12个月的客户档案,并将相关变量转换为数值格式以进行异常值检测与处理,确保了数据质量与分析的可靠性。
特点
BankChurners数据集聚焦于信用卡客户行为分析,其特点在于包含了多维度的客户属性与交易指标。特征涵盖人口统计学信息如年龄、性别、教育水平与婚姻状况,以及金融行为数据如信用额度、总交易金额、交易次数和平均利用率比率。此外,数据集通过数值编码统一了分类变量,并提供了客户流失标志,使得该数据集适用于分类、回归与聚类等多种机器学习任务,为深入探究客户细分与流失驱动因素提供了丰富的基础。
使用方法
该数据集适用于金融数据分析与机器学习建模,用户可首先进行探索性数据分析以理解数据分布与关联性。在建模阶段,可将Attrition_Flag作为目标变量,用于训练客户流失预测模型;其他数值与分类特征则作为输入变量,支持逻辑回归、决策树或聚类算法等应用。数据已预先清洗,建议用户根据研究需求进一步验证特征工程,并利用提供的客户行为指标评估模型性能,从而为银行客户保留策略提供数据驱动的见解。
背景与挑战
背景概述
在金融科技与客户关系管理领域,客户流失预测是银行和金融机构面临的核心挑战之一。BankChurners数据集由Kaggle平台提供,作为数据科学课程项目的一部分,旨在通过机器学习方法分析信用卡客户的流失行为与细分特征。该数据集包含约10,128条记录和22个特征,涵盖了客户人口统计信息、交易行为、信用状况等多维度数据,为研究客户留存策略提供了实证基础。其创建源于对客户生命周期价值的深入探索,通过预测客户流失并识别关键驱动因素,帮助金融机构优化客户服务、降低运营成本并提升盈利能力,对金融风险管理与精准营销具有重要参考价值。
当前挑战
BankChurners数据集所针对的客户流失预测问题,面临多重挑战:在领域层面,客户行为具有高度动态性和非线性特征,且流失事件往往呈现类别不平衡,使得模型易偏向多数类;特征间的复杂交互关系(如信用额度与交易频率)增加了可解释性难度。在构建过程中,数据清洗面临缺失值处理、异常值检测以及类别变量编码的复杂性,例如收入类别与教育水平的离散化可能引入信息损失;同时,原始数据中的噪声与非信息性特征需通过严格筛选,以确保模型训练的稳健性与泛化能力,这对特征工程与算法选择提出了较高要求。
常用场景
经典使用场景
在金融科技与客户关系管理领域,BankChurners数据集为预测银行客户流失提供了经典的应用场景。该数据集通过整合客户人口统计信息、信用使用行为及交易历史等多维度特征,使研究者能够构建机器学习模型,精准识别可能终止信用卡服务的客户群体。这一场景不仅有助于银行实施早期干预策略,还推动了客户生命周期价值的优化研究。
实际应用
在实际业务中,BankChurners数据集被广泛应用于银行与金融机构的客户留存计划。基于该数据集训练的预测模型能够辅助制定个性化营销策略、优化客户服务资源配置,并动态调整信用政策。这些应用不仅提升了客户满意度与忠诚度,还显著降低了运营成本,体现了数据驱动决策在现代化金融服务中的核心价值。
衍生相关工作
围绕BankChurners数据集,学术界衍生了一系列经典研究工作,包括基于集成学习的客户流失预测框架、结合图神经网络的客户关系网络分析,以及利用可解释人工智能技术揭示流失关键驱动因素。这些成果不仅丰富了机器学习在金融领域的应用范式,还为后续的跨行业客户行为研究提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


