IndianBailJudgments-1200
收藏Hugging Face2025-06-22 更新2025-06-23 收录
下载链接:
https://huggingface.co/datasets/SnehaDeshmukh/IndianBailJudgments-1200
下载链接
链接失效反馈官方服务:
资源简介:
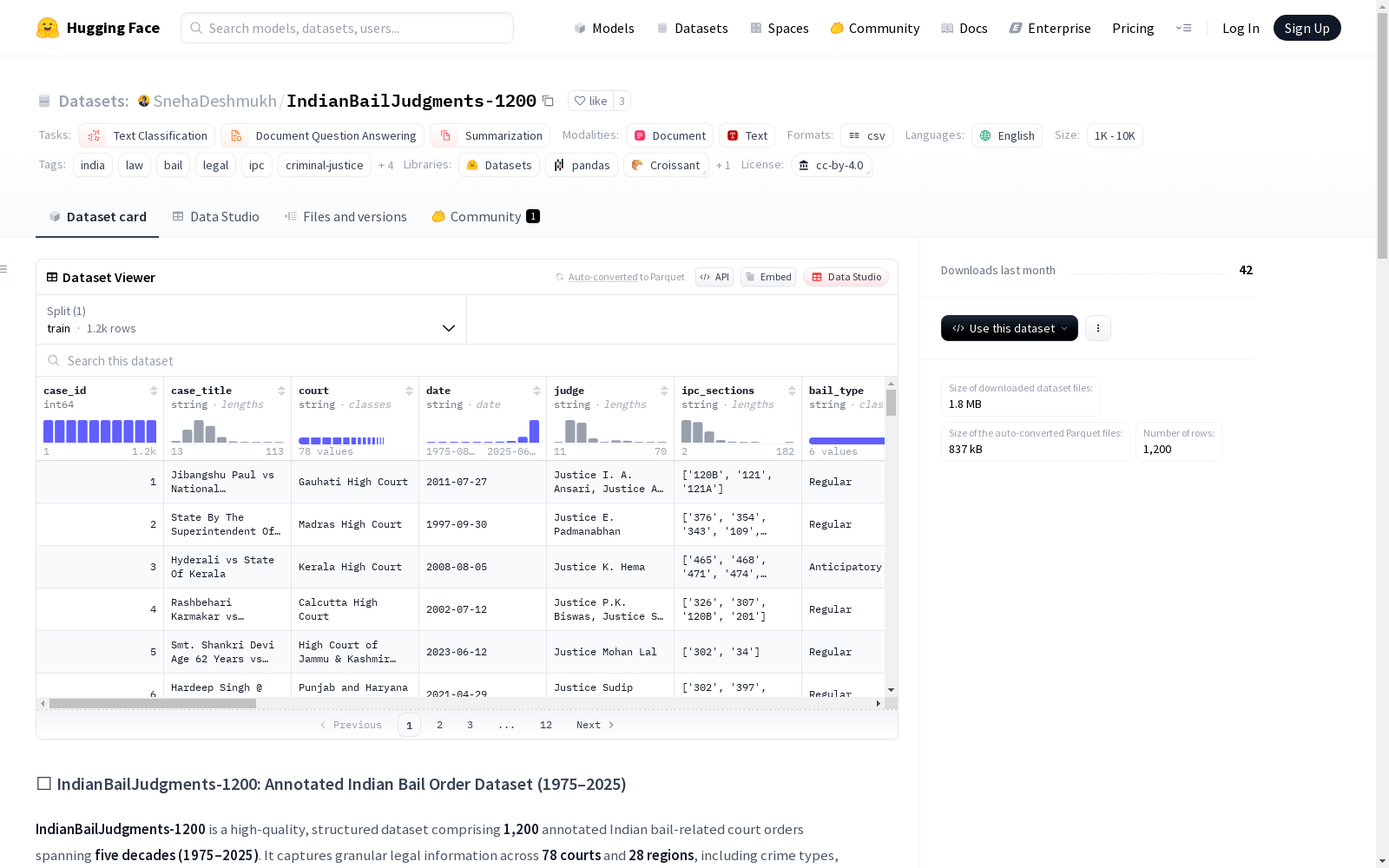
IndianBailJudgments-1200是一个包含1200个注释的印度保释相关法院命令的高质量结构化数据集,跨越1975年至2025年的五个十年。它涵盖了78个法院和28个地区的详细法律信息,包括犯罪类型、IPC条款、法官姓名、法律问题、保释结果和偏见指标。
创建时间:
2025-06-21
原始信息汇总
⚖️ IndianBailJudgments-1200 数据集概述
📌 基本信息
- 数据集名称: IndianBailJudgments-1200
- 类型: 法律文本数据集
- 语言: 英语 (en)
- 许可协议: CC BY 4.0
- 发布日期: 2025年
- 作者: Sneha Deshmukh, Prathmesh Kamble
- 标签: 印度、法律、保释、法律文本、刑事司法、公平性、判决、自然语言处理、结构化数据集
📂 数据集内容
- 总案例数: 1200
- 时间跨度: 1975–2025
- 覆盖法院: 78个
- 覆盖地区: 28个
- 犯罪类型: 12种 (如谋杀、欺诈、网络犯罪等)
- 保释结果: 736例批准,464例拒绝
- 标志性案例: 147例
- 标记偏见案例: 13例
📄 文件结构
indian_bail_judgments.json— 主JSON数据集 (1200个对象)indian_bail_judgments.csv和indian_bail_judgments.xlsx— 表格版本IndianBailJudgments-1200_PDFS/— 包含1200个对应法院PDF文件的文件夹summarized_stats.txt— 数据集的统计摘要
📊 字段说明
每个JSON对象包含以下字段:
- 案件信息:
case_id,case_title,court,date,judge - 法律信息:
ipc_sections,bail_type,bail_outcome,bail_cancellation_case,landmark_case - 被告信息:
accused_name,accused_gender,prior_cases,crime_type - 案件详情:
facts,legal_issues,judgment_reason,summary - 其他信息:
bias_flag,parity_argument_used,region,source_filename
🎯 应用场景
- 法律自然语言处理任务 (摘要、提取、公平性分析)
- 司法透明度和刑事司法研究
- 法学院课程和注释培训
📜 引用信息
bibtex @misc{indianbail2025, title = {IndianBailJudgments-1200: Annotated Dataset of 1200 Indian Bail Judgments}, author = {Sneha Deshmukh and Prathmesh Kamble}, year = {2025}, url = {https://huggingface.co/datasets/SnehaDeshmukh/IndianBailJudgments-1200}, note = {Dataset publicly released under CC BY 4.0 License} }
搜集汇总
数据集介绍
构建方式
IndianBailJudgments-1200数据集通过系统收集1975年至2025年间印度78个法院的1200份保释相关法庭命令构建而成。采用结构化标注方法,每份判决书均提取了案件编号、法庭信息、法官姓名、IPC条款、保释结果等78个字段,并配套保存原始PDF文件以确保数据可追溯性。构建过程特别注重地域覆盖均衡性,涵盖印度28个司法辖区的典型案件,同时包含147个标志性案例和13个标注潜在偏见的特殊案例。
特点
该数据集最显著的特点是同时提供结构化表格与原始法律文书,形成多模态法律数据资源。时间跨度达五十年,完整呈现印度保释法律实践的演变轨迹。精细标注体系包含法律事实、争议焦点、判决理由等专业字段,特别增设偏见标志和程序公平性论证字段,为司法公平性研究提供独特视角。数据分布上,保释批准与拒绝案例比例约为3:2,涵盖谋杀、欺诈、网络犯罪等12种犯罪类型,具有较好的类别平衡性。
使用方法
研究者可通过CSV/JSON格式直接加载结构化数据,配合PDF原文进行深度法律分析。适用于三类典型场景:基于facts和legal_issues字段开发法律文本分类模型;利用judgment_reason字段训练判决摘要生成系统;通过bail_outcome与bias_flag的关联分析开展司法公平性研究。数据已预处理为可直接输入NLP模型的格式,同时保留原始法律文书供专业校验,建议使用时分字段提取关键信息以提高分析效率。
背景与挑战
背景概述
印度保释判决数据集IndianBailJudgments-1200由研究人员Sneha Deshmukh和Prathmesh Kamble于2025年构建,涵盖1975至2025年间印度78个法院的1200份保释相关判决书。该数据集聚焦于印度刑事司法系统中的保释决策机制,旨在通过结构化标注的法院判例,揭示法律推理模式、程序公平性及系统性偏见等核心问题。作为法律自然语言处理领域的重要资源,其跨五十年时间跨度的设计为研究印度保释制度的演变提供了实证基础,尤其在公平性分析和司法透明度评估方面具有显著学术价值。
当前挑战
该数据集面临双重挑战:在领域问题层面,需解决印度保释决策中复杂法律条款(如IPC章节)的语义解析、法官主观裁量导致的判决差异识别,以及性别、地域等潜在偏见因素的量化评估;在构建过程中,需克服历史判决书非结构化文本的信息抽取困难、跨区域法律术语的标准化处理,以及敏感个人信息(如被告身份)的合规化脱敏等技术难题。多模态数据(PDF与结构化数据)的协同标注进一步增加了数据集的质量控制复杂度。
常用场景
经典使用场景
在司法智能化的浪潮中,IndianBailJudgments-1200数据集为法律自然语言处理提供了丰富的素材。研究者可利用该数据集进行保释判决文本分类,通过机器学习模型识别判决书中的关键法律要素,如犯罪类型、印度刑法条款引用等。其跨五十年时间跨度的特性,使得纵向分析印度保释司法实践演变成为可能,为法律文本挖掘设立了新的基准。
解决学术问题
该数据集有效解决了司法公平性量化研究的难题。通过标注法官姓名、地域、性别等敏感变量,研究者可系统检测保释决策中潜在的系统性偏见。其包含的736例批准与464例驳回案例,为构建保释结果预测模型提供了平衡样本,同时78个法院的覆盖度确保了研究结论具有司法代表性,填补了发展中国家司法算法审计的数据空白。
衍生相关工作
该数据集已催生多项创新研究,包括基于图神经网络的司法偏见检测框架、保释判决摘要生成系统等。其中部分成果发表在计算法学顶级会议如ICAIL上,推动了法律可解释AI的发展。相关研究还衍生出印度特定法律本体构建工作,为后续研究者提供了结构化法律知识图谱的基础。
以上内容由遇见数据集搜集并总结生成


