Z873bliwf988hj/MusicBench
收藏Hugging Face2024-01-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Z873bliwf988hj/MusicBench
下载链接
链接失效反馈官方服务:
资源简介:
MusicBench数据集是一个音乐音频-文本对数据集,旨在用于文本到音乐的生成任务。它基于MusicCaps数据集,通过增加音乐特征(如和弦、节拍、速度和调性)并使用文本模板描述这些特征,扩展了原始文本提示。此外,数据集通过音调移位、速度变化和音量变化等音乐上有意义的增强手段,将样本数量从5,521个扩展到52,768个训练样本和400个测试样本。数据集包含三个JSON文件和附带的音频文件,训练集包含增强的音频样本和增强的标题,测试集分为TestA和TestB,TestB包含所有可能的控制句子。FMACaps评估数据集包含从Free Music Archive提取的1000个样本,并通过ChatGPT生成伪标签,用于评估Mustango模型的可控性和音频质量。
MusicBench数据集是一个音乐音频-文本对数据集,旨在用于文本到音乐的生成任务。它基于MusicCaps数据集,通过增加音乐特征(如和弦、节拍、速度和调性)并使用文本模板描述这些特征,扩展了原始文本提示。此外,数据集通过音调移位、速度变化和音量变化等音乐上有意义的增强手段,将样本数量从5,521个扩展到52,768个训练样本和400个测试样本。数据集包含三个JSON文件和附带的音频文件,训练集包含增强的音频样本和增强的标题,测试集分为TestA和TestB,TestB包含所有可能的控制句子。FMACaps评估数据集包含从Free Music Archive提取的1000个样本,并通过ChatGPT生成伪标签,用于评估Mustango模型的可控性和音频质量。
提供机构:
Z873bliwf988hj
原始信息汇总
MusicBench 数据集
MusicBench 数据集是一个音乐音频-文本对数据集,专为文本到音乐生成目的设计,并与 Mustango 文本到音乐模型一同发布。MusicBench 基于 MusicCaps 数据集,将其从 5,521 个样本扩展到 52,768 个训练样本和 400 个测试样本。
数据集详情
MusicBench 通过以下方式扩展 MusicCaps:
- 包括从音频中提取的和弦、节拍、速度和调式等音乐特征。
- 使用文本模板描述这些音乐特征,从而增强原始文本提示。
- 通过执行音乐上有意义的增强(半音音高偏移、速度变化和音量变化)来扩展音频样本数量。
训练集大小 = 52,768 个样本 测试集大小 = 400 个样本
数据集描述
MusicBench 包含三个 json 文件和以 tar.gz 形式附加的音频文件。
训练集包含增强的音频样本和增强的描述。此外,它还提供了所有音频样本的 ChatGPT 重述描述。 TestA 和 TestB 集包含相同的音频内容,但 TestB 在所有样本的描述中包含所有四种可能的控制句子(与四种音乐特征相关),而 TestA 在描述中没有控制句子。
每个 .json 文件的每一行包含:
- location(解压缩
tar.gz文件后的文件位置) - main_caption – 增强结果的文本提示(TestB 包含控制句子,训练集包含 ChatGPT 重述描述)
- alt_caption – 在 TestB 中,这些是没有添加任何控制句子的描述。
- prompt_aug – 与音量变化增强相关的控制句子。
- prompt_ch – 描述和弦序列的控制句子。
- prompt_bt – 描述节拍数(拍号)的控制句子。
- prompt_bpm – 描述速度的控制句子,以每分钟节拍数(bpm)或音乐术语表示,例如 Adagio、Moderato、Presto。
- prompt_key – 与提取的音乐调式相关的控制句子。
- beats – 节拍和重拍时间戳。这是训练 Mustango 的输入。
- bpm – 以数字形式保存的速度特征。
- chords – 音轨中包含的和弦序列。这是训练 Mustango 的输入。
- chords_time – 检测到的和弦的时间戳。这是训练 Mustango 的输入。
- key – 检测到的调式的根音和类型。
- keyprob – 检测算法提供的此检测调式的置信度得分。
FMACaps 评估数据集
此外,我们还向您展示 FMACaps 评估数据集,该数据集包含从 Free Music Archive (FMA) 提取的 1000 个样本,并通过从音频中提取标签并利用 ChatGPT 上下文学习生成伪描述。更多信息请参阅我们的论文!
大多数样本时长为 10 秒,例外情况为 5 到 10 秒之间。
数据大小:1,000 个样本 采样率:16 kHz
包含的文件:
- 1,000 个音频文件在 "audiodata" 文件夹中
- FMACaps_A – 此文件包含没有控制句子的描述。
- FMACaps_B – 此文件包含所有控制句子的描述。我们使用此文件进行 Mustango 的可控性评估。
- FMACaps_C – 此文件包含一些控制句子的描述。对于每个样本,我们以 25/30/20/15/10% 的概率选择 0/1/2/3/4 个控制句子,如我们的论文所述。此文件用于客观评估 Mustango 的音频质量。
每个 .json 文件的结构与 MusicBench 相同,如前一节所述,除了 "alt_caption" 列是空的。所有描述 都在 "main_caption" 列 中!
许可证: cc-by-sa-3.0
搜集汇总
数据集介绍
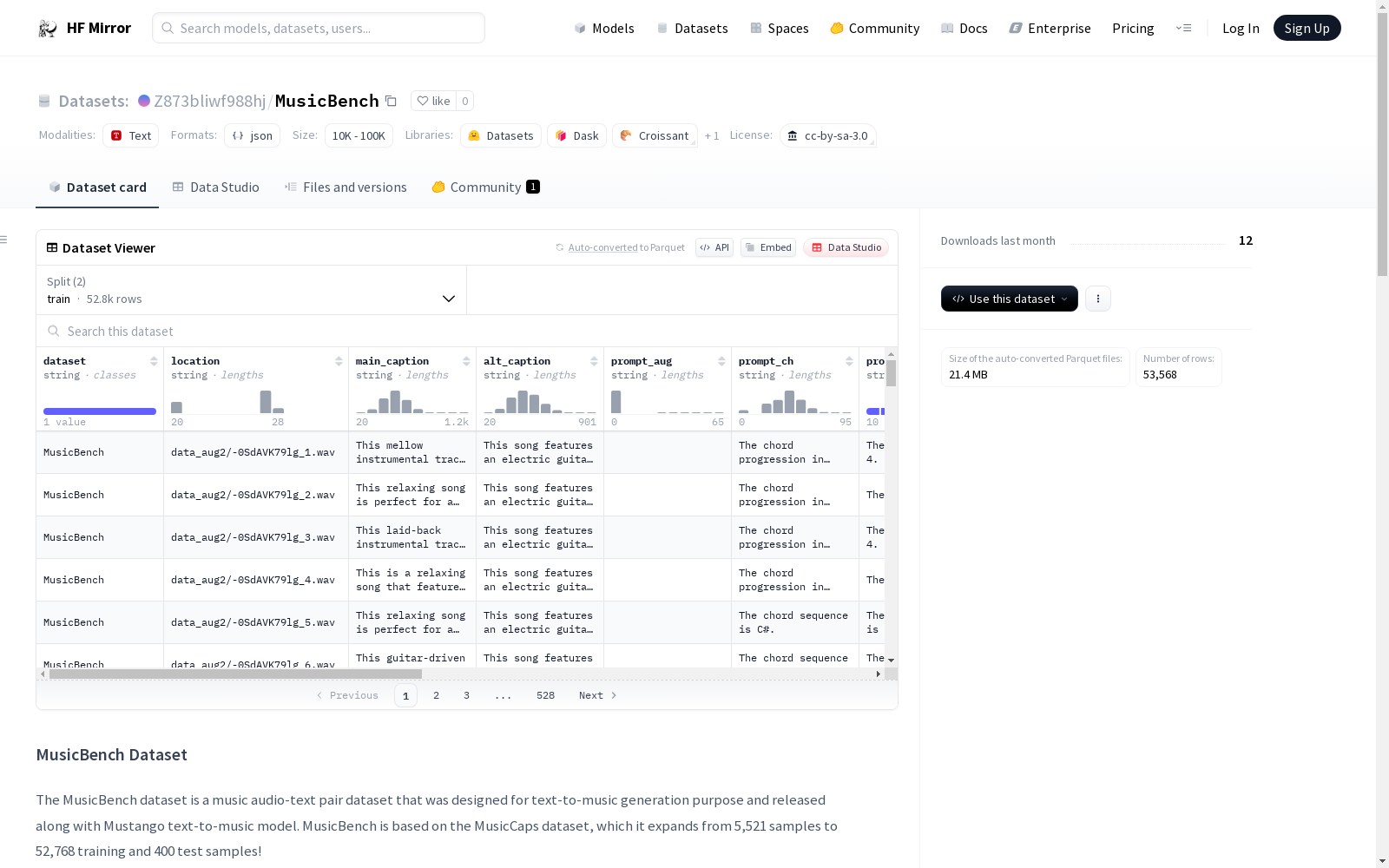
构建方式
MusicBench数据集是在MusicCaps数据集的基础上进行扩展构建的,通过引入音频中的和声、节拍、节奏和调性等音乐特征,并采用文本模板描述这些音乐特征,从而增强原有的文本提示。数据集包含52,768个训练样本和400个测试样本,是通过半音调移调、节奏变化和音量变化等音乐意义增强的音频样本构建而成。
使用方法
使用MusicBench数据集时,用户可以依据.json文件中的信息定位音频文件和对应的文本描述。每个.json文件中的记录包括文件位置、主要描述、替代描述以及与音量变化、和声序列、节拍计数、节奏和调性相关的控制句子。这些信息可用于训练音乐生成模型,如Mustango,以实现文本到音乐的生成。
背景与挑战
背景概述
MusicBench数据集,专为文本至音乐生成任务设计,伴随着Mustango文本至音乐模型的发布而推出。该数据集在MusicCaps的基础上进行了扩展,不仅样本数量从5,521个增加至52,768个训练样本和400个测试样本,还引入了和弦、节拍、节奏和调性等音乐特征,并利用文本模板描述这些特征以增强原始文本提示。MusicBench的创建,为音乐生成领域的研究提供了重要资源,其影响力在学术界和工业界均得到了广泛认可。
当前挑战
在研究领域,MusicBench数据集面临的挑战主要包括如何更准确地提取和描述音乐特征,以及如何利用这些特征生成高质量的音乐。构建过程中,数据集的创建者需要克服了音乐样本的多样性和复杂性,通过半音高移位、节奏变化和音量变化等音乐意义增强的样本扩展技术,以及确保文本描述与音乐特征之间的一致性。此外,数据集在控制句的设计和分布上也提出了特有的挑战,以确保模型的可控性和音乐质量评估的客观性。
常用场景
经典使用场景
在音乐信息检索与生成领域,MusicBench数据集的经典使用场景在于支撑文本到音乐的生成任务,为模型训练提供了丰富的音频-文本对。该数据集通过音频提取的和弦、节拍、速度与调性等音乐特征,结合文本模板,为音乐生成模型如Mustango提供了详尽的描述性输入,从而促进模型理解和生成音乐的能力。
解决学术问题
MusicBench数据集解决了音乐生成中如何更精细地控制音乐特征的问题。其提供了带有控制句的文本描述,使得研究人员能够研究模型在不同音乐特征控制下的生成性能,为音乐生成领域的学术研究提供了标准化和可控的实验条件,推动了音乐信息处理技术的进步。
实际应用
在实际应用中,MusicBench数据集的应用场景广泛,从音乐创作到音乐教育,再到音乐辅助制作等,都可以利用该数据集训练出的模型来实现更高质量的音乐内容生成。此外,该数据集还能辅助音乐分析,为音乐理解与风格模仿提供技术支持。
数据集最近研究
最新研究方向
在音乐生成领域,MusicBench数据集以其丰富的音频样本及对应的文本描述,为文本到音乐生成任务提供了重要的资源。该数据集在原有MusicCaps的基础上,不仅数量上实现了大幅扩充,更通过引入音频特征如和弦、节拍、速度和调性等信息,以及文本模板的描述增强,为音乐生成模型的训练提供了更为精细化的控制。近期研究聚焦于如何利用MusicBench数据集提升音乐生成系统的表现力和控制性,特别是在音乐风格、节奏和情感表达方面的研究取得了显著进展,这对于音乐创作与生产领域具有重要的实践意义和推动作用。
以上内容由遇见数据集搜集并总结生成


