m-ArenaHard
收藏Hugging Face2024-10-24 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/CohereForAI/m-ArenaHard
下载链接
链接失效反馈官方服务:
资源简介:
m-ArenaHard数据集是一个多语言的大型语言模型(LLM)评估集。该数据集通过使用Google Translate API v3将原本仅限英语的LMarena(前身为LMSYS)arena-hard-auto-v0.1测试数据集的提示翻译成22种语言而创建。原始的英语提示由Li等人(2024年)创建,包含从Chatbot Arena收集的500个具有挑战性的用户查询。该数据集总共包含23种语言,每种语言有500个示例。数据集的字段包括'question_id'、'cluster'、'category'和'prompt'。该数据集由Cohere For AI发布,并根据Apache 2.0许可证进行许可。
The m-ArenaHard dataset is a multilingual large language model (LLM) evaluation benchmark. This dataset is constructed by translating the prompts of the originally English-only LMarena (formerly LMSYS) arena-hard-auto-v0.1 test dataset into 22 languages via the Google Translate API v3. The original English prompts were created by Li et al. (2024), which contain 500 challenging user queries collected from Chatbot Arena. In total, this dataset spans 23 languages, with 500 examples per language. The dataset fields include 'question_id', 'cluster', 'category', and 'prompt'. This dataset is released by Cohere For AI and licensed under the Apache 2.0 license.
提供机构:
Cohere For AI
创建时间:
2024-10-23
原始信息汇总
m-ArenaHard 数据集概述
数据集详情
概述
m-ArenaHard 数据集是一个多语言的大型语言模型(LLM)评估数据集。该数据集通过使用 Google Translate API v3 将原始的英语 LMarena(原 LMSYS)arena-hard-auto-v0.1 测试数据集的提示翻译成 22 种语言而创建。原始的英语提示由 Li et al. (2024) 创建,包含 500 个来自 Chatbot Arena 的挑战性用户查询。这些查询可用于执行自动 LLM 评判评估,这些评估与 Chatbot Arena 排名具有高度相关性。
语言支持
该数据集包含以下 23 种语言:
- 阿拉伯语 (ar)
- 中文 (zh)
- 捷克语 (cs)
- 荷兰语 (nl)
- 英语 (en)
- 法语 (fr)
- 德语 (de)
- 希腊语 (el)
- 希伯来语 (he)
- 印地语 (hi)
- 印度尼西亚语 (id)
- 意大利语 (it)
- 日语 (ja)
- 韩语 (ko)
- 波斯语 (fa)
- 波兰语 (pl)
- 葡萄牙语 (pt)
- 罗马尼亚语 (ro)
- 俄语 (ru)
- 西班牙语 (es)
- 土耳其语 (tr)
- 乌克兰语 (uk)
- 越南语 (vi)
数据结构
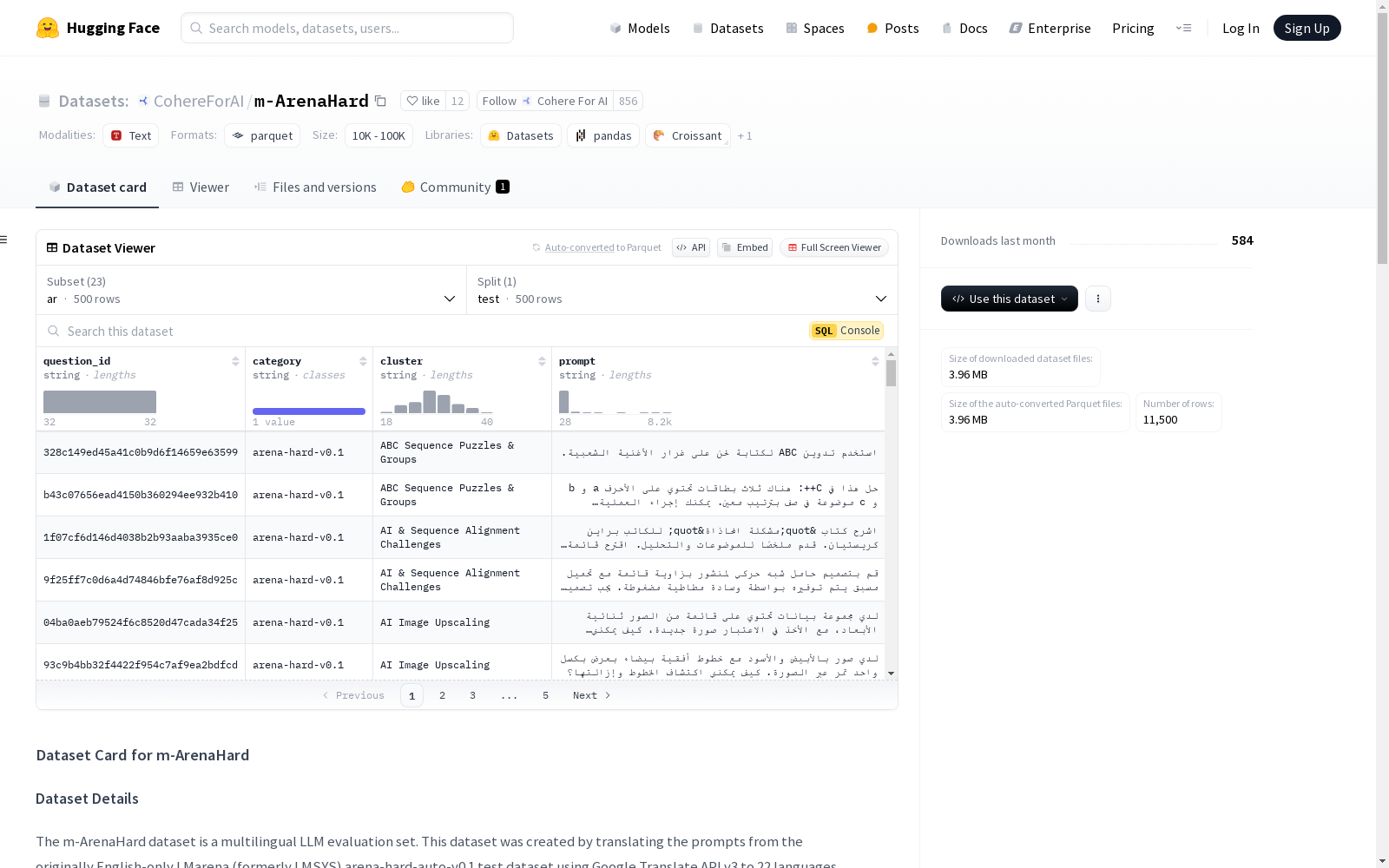
每个语言子集的数据结构如下:
question_id: 示例的唯一 IDcluster: 示例的主题category: 示例所属的原始数据集prompt: 提示文本(问题或指令)
数据集大小
每个语言子集的测试集包含 500 个示例,具体大小如下:
- 阿拉伯语 (ar): 328741 字节
- 捷克语 (cs): 258801 字节
- 德语 (de): 276977 字节
- 希腊语 (el): 411090 字节
- 英语 (en): 249691 字节
- 西班牙语 (es): 274711 字节
- 波斯语 (fa): 342307 字节
- 法语 (fr): 287086 字节
- 希伯来语 (he): 298857 字节
- 印地语 (hi): 486279 字节
- 印度尼西亚语 (id): 263904 字节
- 意大利语 (it): 269604 字节
- 日语 (ja): 300804 字节
- 韩语 (ko): 278795 字节
- 荷兰语 (nl): 265040 字节
- 波兰语 (pl): 266885 字节
- 葡萄牙语 (pt): 266432 字节
- 罗马尼亚语 (ro): 271404 字节
- 俄语 (ru): 388651 字节
- 土耳其语 (tr): 269018 字节
- 乌克兰语 (uk): 374668 字节
- 越南语 (vi): 304066 字节
- 中文 (zh): 229345 字节
数据加载
使用 datasets 库加载数据集的示例如下:
python
from datasets import load_dataset
dataset = load_dataset("CohereForAI/m_ArenaHard", "en")
版权信息
该数据集根据 Apache 2.0 许可证发布,可用于任何学术或商业目的。
搜集汇总
数据集介绍
构建方式
m-ArenaHard数据集是一个多语言大语言模型评估集,其构建基于原始的英文LMarena(前身为LMSYS)arena-hard-auto-v0.1测试数据集。通过Google Translate API v3,将原始的500个具有挑战性的用户查询翻译成22种语言,涵盖了阿拉伯语、中文、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语。这一过程确保了数据集的多语言覆盖性和广泛适用性。
使用方法
使用m-ArenaHard数据集时,首先需要安装Datasets库,并通过指定语言代码加载相应的子集。例如,加载英语子集可以使用代码`load_dataset("CohereForAI/m_ArenaHard", "en")`。用户可以根据需要加载特定语言的子集,或者加载整个数据集以进行全面的多语言评估。数据集的结构清晰,每个实例包含question_id、cluster、category和prompt字段,便于用户直接应用于模型评估和性能分析。
背景与挑战
背景概述
m-ArenaHard数据集是一个多语言大语言模型(LLM)评估集,由Cohere For AI团队创建。该数据集基于Li等人(2024)开发的英文LMarena(原LMSYS)arena-hard-auto-v0.1测试集,通过Google Translate API v3将其翻译为22种语言。原始英文提示包含500个来自Chatbot Arena的具有挑战性的用户查询,旨在用于自动LLM评估,其评估结果与Chatbot Arena排名具有高度相关性。该数据集的发布标志着多语言LLM评估领域的重要进展,为跨语言模型性能的比较提供了标准化工具。
当前挑战
m-ArenaHard数据集在构建和应用过程中面临多重挑战。首先,翻译过程中可能引入的语言偏差和文化差异会影响提示的准确性和一致性,进而影响模型评估的公平性。其次,不同语言的语法结构和表达习惯差异显著,如何确保翻译后的提示在语义和语境上与原文保持一致,是一个复杂的技术难题。此外,数据集的规模相对较小,可能无法全面覆盖所有语言和领域的复杂场景,限制了其在广泛场景下的适用性。最后,自动评估与人工评估之间的相关性仍需进一步验证,以确保评估结果的可靠性和有效性。
常用场景
经典使用场景
m-ArenaHard数据集在多语言大语言模型(LLM)评估领域具有重要应用。该数据集通过将原本仅限英文的LMarena测试集翻译为22种语言,为跨语言模型性能评估提供了丰富的测试场景。研究人员通常利用该数据集进行自动化的LLM评判,评估模型在不同语言环境下的表现,尤其是在处理复杂用户查询时的能力。
解决学术问题
m-ArenaHard数据集解决了多语言大语言模型评估中的关键问题,即缺乏高质量、多样化的跨语言测试数据。通过提供23种语言的500个复杂用户查询,该数据集为研究者提供了标准化的评估工具,能够有效衡量模型在不同语言和文化背景下的表现。其高相关性验证了自动评判与Chatbot Arena排名的一致性,为多语言模型的研究和优化提供了重要支持。
实际应用
在实际应用中,m-ArenaHard数据集被广泛用于多语言聊天机器人和智能助手的性能测试。企业可以利用该数据集评估其产品在不同语言市场中的表现,优化模型以提升用户体验。此外,该数据集还为多语言教育工具、翻译系统和跨文化交流平台提供了可靠的基准测试工具,帮助开发者识别和解决模型在特定语言中的性能瓶颈。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言大语言模型(LLM)的评估正逐渐成为研究热点。m-ArenaHard数据集作为多语言LLM评估的重要资源,涵盖了23种语言的500个具有挑战性的用户查询,为跨语言模型性能的全面评估提供了坚实基础。当前研究聚焦于如何利用该数据集进行自动化的LLM评判,特别是在不同语言间的表现一致性及其与Chatbot Arena排名的相关性。随着全球化进程的加速,多语言模型的优化与评估需求日益增长,m-ArenaHard数据集的应用不仅推动了多语言模型的技术进步,也为跨文化交流和全球化服务提供了有力支持。
以上内容由遇见数据集搜集并总结生成


