ComplexMultistepImageEditing
收藏Hugging Face2025-05-02 更新2025-05-03 收录
下载链接:
https://huggingface.co/datasets/NilanE/ComplexMultistepImageEditing
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含复杂的图像编辑推理链,旨在让统一的 multimodal LLMs(如 Show-o 和 Janus)能够平等地使用文本和图像标记进行推理。数据集的结构包括源图像、编辑提示、中间生成的图像、评分模型与图像生成模型之间的对话日志以及自我评价的多模态推理链。该数据集的目标是解决公开交错的文本-图像数据集的数据不匹配问题,进入交错的 多模态推理数据集的新领域,并促进统一多模态模型的研究领域。
创建时间:
2025-04-29
原始信息汇总
数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 图像到图像
- 标签: reasoning-datasets-competition
数据集结构
json { source: 从imgenet-1k随机采样的图像, prompt: 应用于源图像的编辑提示, edit_0..7: 中间生成的图像, chat_log: 评论模型与图像生成模型之间的对话日志, reasoning: 将对话日志重写为自我评论的多模态推理链 }
动机与用途
- 解决开放统一多模态数据集中缺乏交错文本-图像数据集的问题。
- 进入交错多模态推理数据集的新领域。
- 为统一多模态模型的研究领域做出贡献。
创建过程
- 使用Gemini 2.0 Flash生成复杂图像转换/编辑请求。
- 将源图像和编辑请求发送至2.0 Flash图像生成模型,生成满足请求的图像。
- 将生成的图像与所有先前输入和响应发送回2.0 Flash,以评论生成图像是否符合请求。
- 根据评论和上下文,再次尝试满足编辑请求。
- 重复步骤3和4,直到对话过长或生成满足要求。
- 使用2.5 Flash将成功对话转换为推理轨迹。
自定义数据集
设置
bash git clone https://huggingface.co/datasets/NilanE/ComplexMultistepImageEditing pip install -U jsonlines datasets google-genai
操作
bash python3 create_dataset.py
注意事项
- 源图像来自imagenet-1k,需遵守其许可证。
- 数据集创建代码未经过全面测试,遇到问题可发起讨论。
局限性
- 数据集规模较小,适用范围有限。
- 仅涵盖图像编辑。
- 仅使用单一交错图像生成模型(2.0 Flash图像生成)。
- 生成的图像编辑不一定是渐进式的。
- 推理链可能无法完全代表逻辑推理。
- 编辑请求的主题和原创性有限。
搜集汇总
数据集介绍
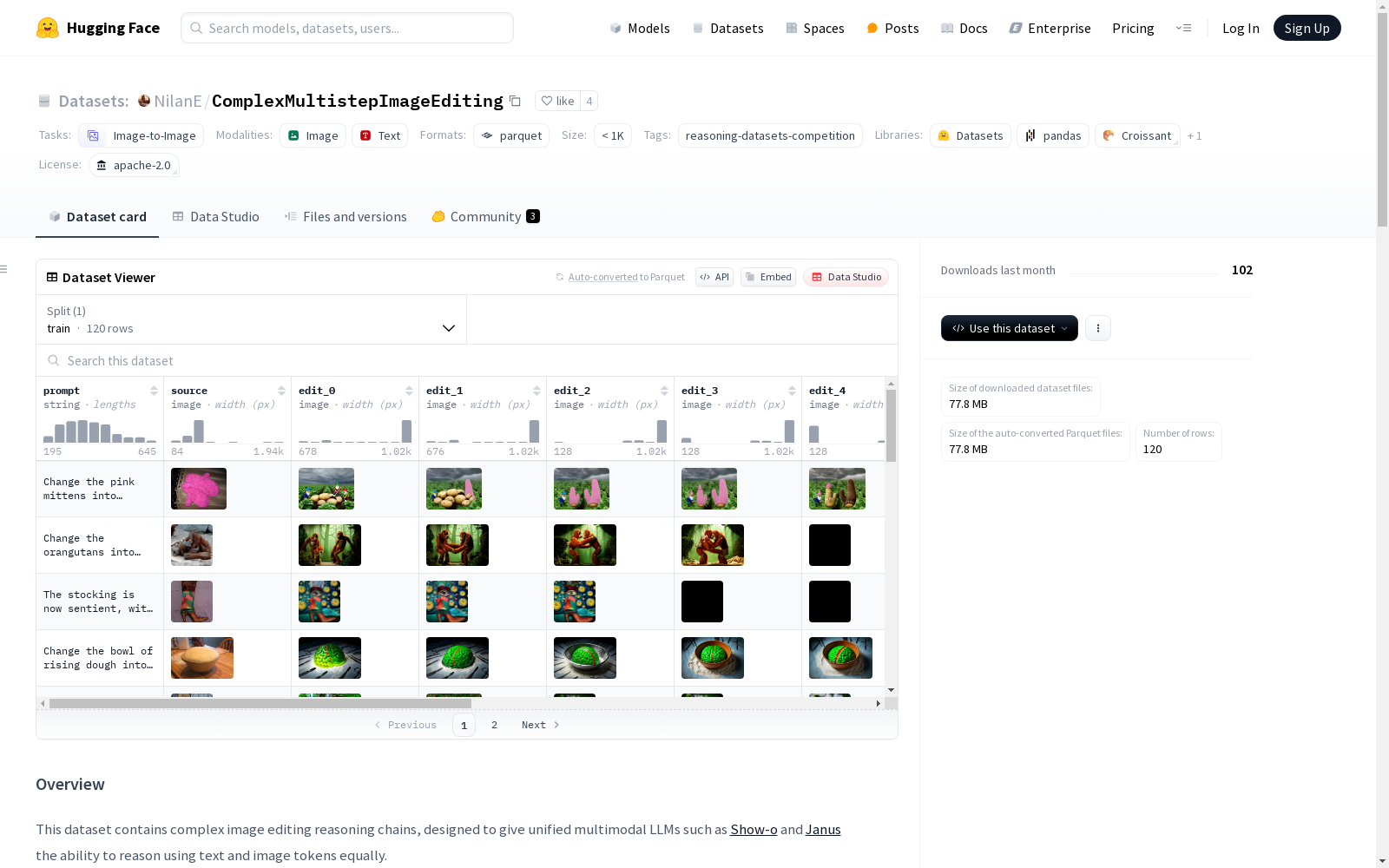
构建方式
在跨模态推理研究领域,ComplexMultistepImageEditing数据集的构建采用了创新的多阶段交互式生成策略。该流程以ImageNet-1k的随机采样图像为起点,通过Gemini 2.0 Flash模型生成复杂的图像编辑指令,随后由图像生成模型执行多轮迭代式编辑。每轮编辑后,批评模型会对生成结果进行评估并反馈改进建议,形成动态对话日志。最终由Gemini 2.5 Flash将这些交互记录转化为结构化的多模态推理链,完整记录了从原始图像到目标图像的渐进式转化过程。
特点
作为首个专注于跨模态渐进式推理的数据集,其核心价值在于突破了传统文本-图像数据集的单向生成范式。数据集包含原始图像、编辑提示、8个中间编辑版本、对话日志及推理链五维数据结构,完整呈现了多模态模型的决策轨迹。特别值得注意的是,编辑过程中产生的批判性对话模拟了人类创作时的反思过程,为研究模型的自修正能力提供了珍贵样本。数据覆盖了物体属性修改、场景重组等多样化编辑类型,虽然主题分布存在一定局限性,但为统一多模态模型的联合推理能力评估设立了新基准。
使用方法
该数据集主要服务于统一多模态大模型的训练与评估,研究者可通过HuggingFace平台直接加载标准化格式的数据。使用前需配置Gemini API密钥并安装指定依赖库,运行create_dataset.py脚本可扩展数据集规模。对于特定研究需求,可利用内置的to_hf.py工具将生成的JSONL文件转换为HF数据集格式。在实际应用中,建议重点关注推理链与图像序列的对应关系,这为分析模型的多模态逻辑推理能力提供了关键视角。需要注意的是,由于生成依赖特定API,本地复现时可能需调整参数以适应不同的计算环境。
背景与挑战
背景概述
ComplexMultistepImageEditing数据集由NilanE等研究者于2024年构建,旨在解决多模态大语言模型在图像与文本联合推理方面的关键问题。该数据集通过构建复杂的图像编辑推理链,为开源统一多模态模型如Show-o和Janus提供了跨模态推理能力的研究基础。其核心创新点在于突破了传统多模态模型将图像理解与生成视为独立任务的局限,探索了图像与文本在推理过程中的协同机制。作为开放多模态研究社区的重要资源,该数据集不仅填补了交错式图文数据集的空白,更推动了统一多模态推理这一新兴领域的发展,相关技术已延伸至视频标记化等前沿方向。
当前挑战
该数据集面临双重挑战:在领域问题层面,需突破现有模型对图像与文本割裂处理的范式,建立跨模态的渐进式推理能力,而当前生成结果存在逻辑连贯性不足的问题;在构建过程层面,受限于开源生态,仅能依赖单一图像生成模型导致数据多样性不足,且通过对话日志转化推理链的方法可能引入逻辑失真。数据集规模较小与编辑主题单一等局限,进一步制约了其在复杂多模态推理任务中的应用广度。
常用场景
经典使用场景
在跨模态推理研究领域,ComplexMultistepImageEditing数据集为统一多模态大语言模型(如Show-o和Janus)提供了独特的实验平台。该数据集通过精心设计的图像编辑推理链,使模型能够平等地处理文本和图像标记,从而模拟人类在复杂视觉任务中的渐进式推理过程。研究人员可利用其包含的中间生成图像、对话日志和重构后的推理链,深入探究多模态模型在连续图像编辑任务中的表现。
解决学术问题
该数据集有效解决了开放多模态研究中的三个关键问题:首先填补了交错式图文数据集的空白,为开放社区提供了稀缺的跨模态交互数据;其次开创了交错多模态推理数据集的新领域,推动了对视觉-语言联合推理机制的探索;最后为统一多模态模型的研究提供了基准测试平台,特别是针对图像理解与生成任务的协同处理能力评估,这对突破现有专用模型的性能瓶颈具有重要意义。
衍生相关工作
该数据集已催生多个重要研究方向,包括极简视频标记器TiTok-Video的开发,以及基于批判性对话的渐进式图像生成框架。相关研究进一步拓展到多模态思维链的量化评估领域,如CMREval基准的建立。在模型架构方面,启发了Janus-Edit等支持双向图文推理的混合专家系统,这些工作共同推进了开放多模态模型向商用系统的性能靠拢。
以上内容由遇见数据集搜集并总结生成


