mstz/blood
收藏Hugging Face2023-04-15 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mstz/blood
下载链接
链接失效反馈官方服务:
资源简介:
该数据集来自UCI ML仓库,涉及个人特征和收入阈值。数据集的主要任务是二元分类,即判断一个人是否在过去一个月内献血。
该数据集来自UCI ML仓库,涉及个人特征和收入阈值。数据集的主要任务是二元分类,即判断一个人是否在过去一个月内献血。
提供机构:
mstz
原始信息汇总
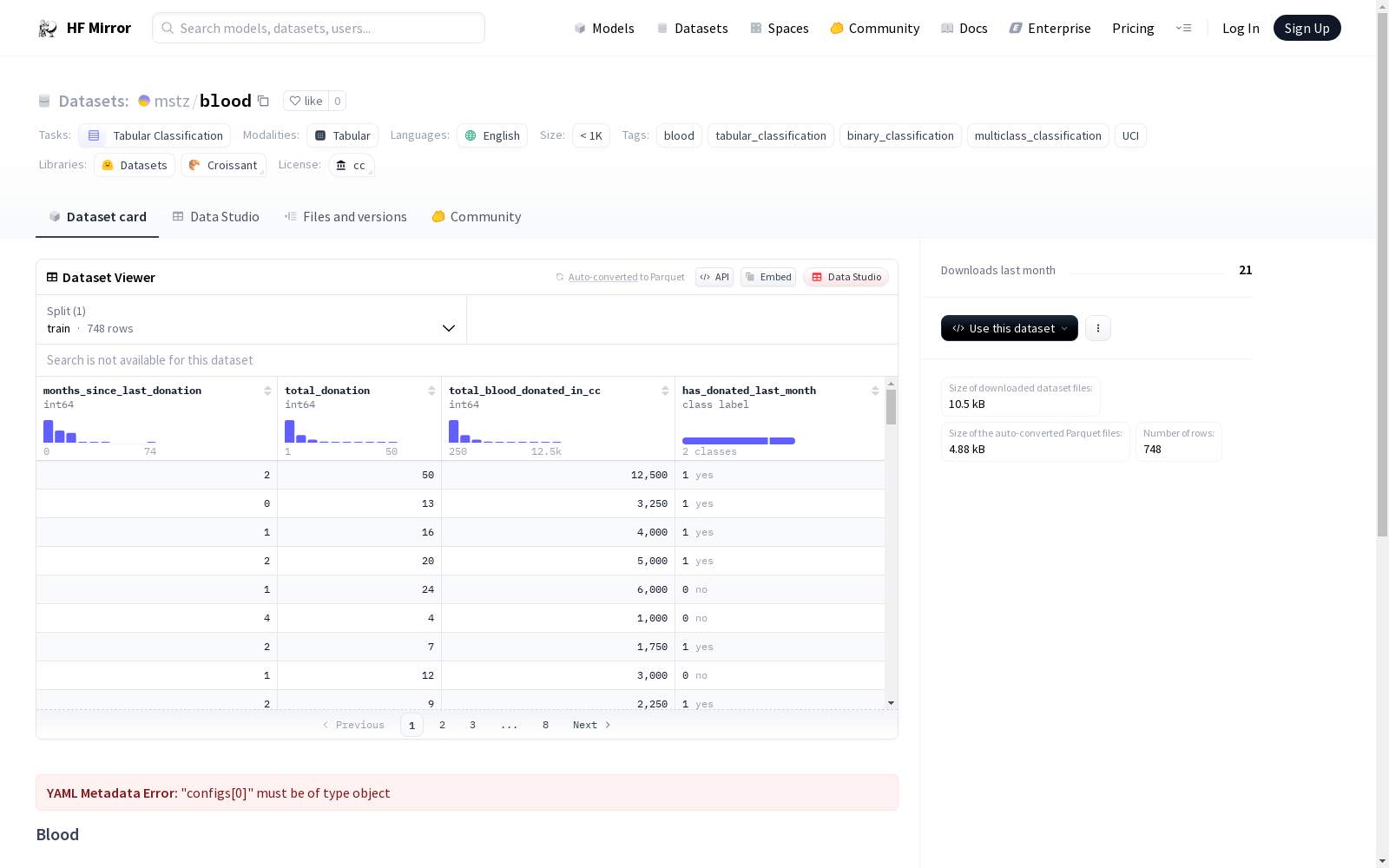
数据集概述
基本信息
- 名称: Blood Transfusion
- 语言: 英语
- 标签:
- 血液
- 表格分类
- 二元分类
- 多类分类
- UCI
- 美观名称: Blood Transfusion
- 大小类别: n<1K
- 任务类别: 表格分类
- 配置: 血液
- 许可证: cc
数据来源
- 来源: UCI ML 仓库
- 详细链接: Blood Transfusion 数据集
配置与任务
| 配置 | 任务 | 描述 |
|---|---|---|
| 血液 | 二元分类 | 个人在过去一个月内是否捐献过血液? |
搜集汇总
数据集介绍
构建方式
本数据集 Blood Transfusion 采集自 UCI 机器学习数据库,其构建基于人口普查数据,涵盖了个人的基本特征信息以及是否在近期捐献过血液的记录。构建过程中,数据集整理了包括年龄、性别、职业等在内的多个维度特征,并以此为基础,对个体的捐血行为进行分类。
特点
Blood Transfusion 数据集的特点在于其简洁明了的结构化表格形式,易于进行数据预处理和特征工程。其包含的数据规模较小,适合快速迭代和模型验证。此外,数据集标注清晰,划分为二元分类任务,即判断个体在过去一个月内是否捐献过血液,为研究血液捐献行为提供了直接的数据支持。
使用方法
使用该数据集时,可通过 HuggingFace 的 datasets 库方便地加载。加载后,数据集被划分为训练集和测试集,用户可以直接对数据进行探索和预处理。针对具体任务,研究者可以采用二元分类模型进行训练,并通过数据集中的标签来评估模型的性能。
背景与挑战
背景概述
在医学研究及公共健康领域,血液捐献是一项至关重要的工作。'mstz/blood'数据集,源自UCI机器学习仓库,由MSTZ团队整理发布,旨在通过对个人特征的深入分析,预测个体在过去一个月内是否有献血行为。该数据集包含了个人的社会经济特征及献血记录,自发布以来,为相关研究提供了宝贵的资源,对于提升血液捐献预测模型的准确性具有显著影响。
当前挑战
数据集在构建和应用过程中所面临的挑战主要包括:如何准确识别并处理数据中的噪声和不完整记录,以及如何在保护个人隐私的前提下,充分利用数据集进行有效的特征提取和模型训练。此外,由于数据集规模较小,面临的挑战还包括如何避免过拟合,以及如何提升模型的泛化能力,以适应更广泛人群的血液捐献预测需求。
常用场景
经典使用场景
在医学研究的领域中,mstz/blood数据集常被用于构建预测模型,以判断个体在过去一个月内是否有献血行为。该数据集包含了人口统计信息和收入门槛,为研究提供了丰富的特征变量。
实际应用
在现实世界中,mstz/blood数据集的实际应用场景广泛,如血液中心的献血者招募策略优化、献血行为的预测分析以及健康管理的个性化建议等。
衍生相关工作
基于mstz/blood数据集,研究者们衍生出了一系列相关工作,包括但不限于改进分类算法、探索献血行为的决定因素,以及结合其他数据源进行多模态数据分析,进一步拓展了该数据集的应用边界。
以上内容由遇见数据集搜集并总结生成


