textual-inference-with-confidence
收藏数据集概述
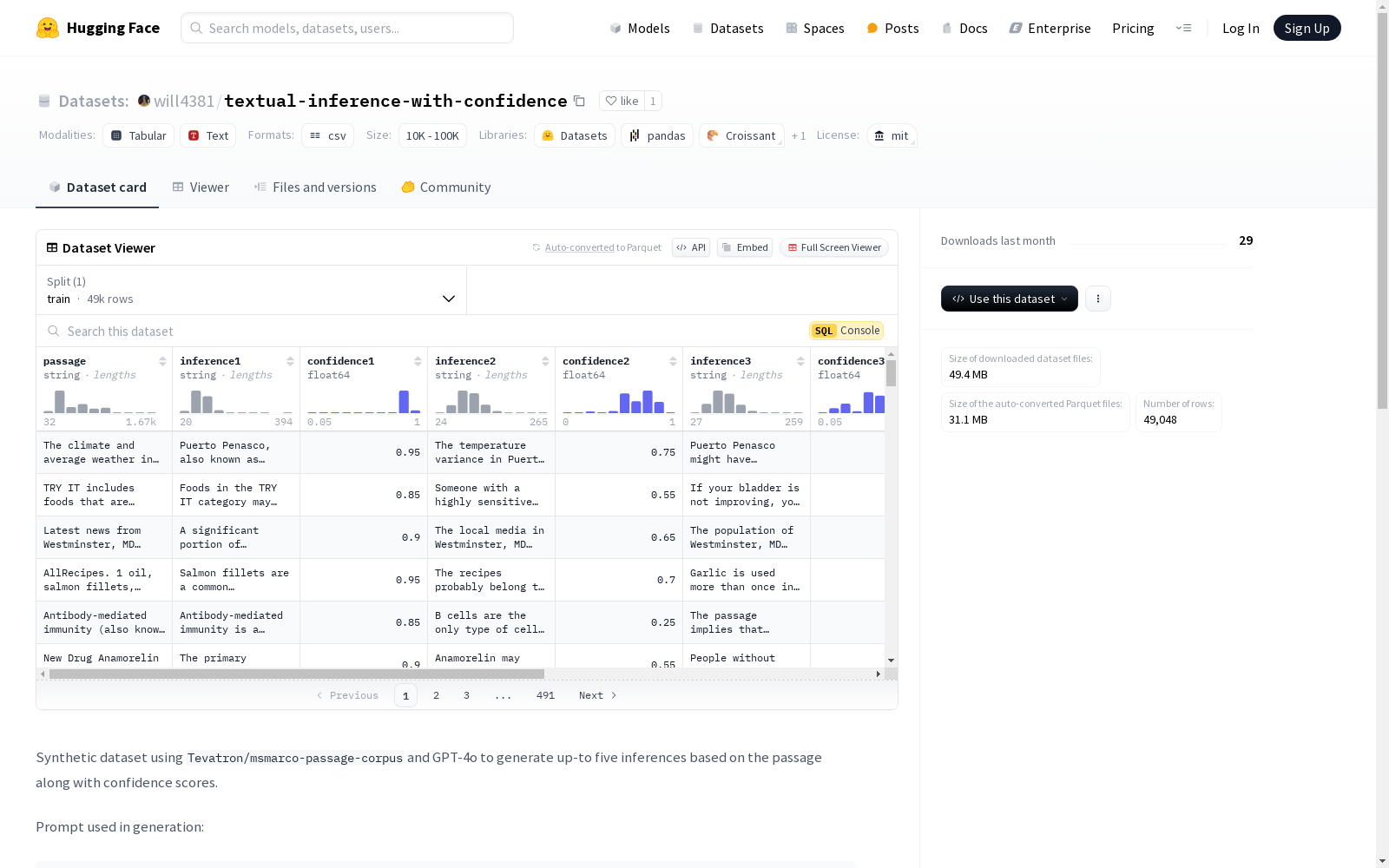
数据集描述
该数据集是通过使用 Tevatron/msmarco-passage-corpus 和 GPT-4o 生成的合成数据集,旨在基于给定的段落生成最多五个推断,并附带置信度分数。
生成提示
生成过程中使用的提示如下:
Given the following passage, generate a series of 5 inferences that can be drawn from the text. Include a mix of well-reasoned, insightful inferences as well as some that may be less supported or even incorrect. Assign each inference a confidence score between 0 and 1, where 1 indicates high confidence in the inferences correctness and relevance, and 0 indicates low confidence.
Passage: "{passage}"
Format your response as a JSON object with the following structure: { "inferences": [ { "text": "First inference", "confidence": 0.XX }, { "text": "Second inference", "confidence": 0.XX }, { "text": "Third inference", "confidence": 0.XX }, { "text": "Fourth inference", "confidence": 0.XX }, { "text": "Fifth inference", "confidence": 0.XX } ] }
Ensure each inference is distinct and varies in its level of correctness and relevance to the passage. Include:
- At least one highly plausible and well-supported inference (confidence > 0.80)
- At least one inference thats somewhat plausible but not strongly supported (confidence 0.40 - 0.60)
- At least one inference thats questionable or a stretch based on the given information (confidence < 0.30)
The other inferences can fall anywhere on this spectrum. Avoid repeating information directly stated in the passage.