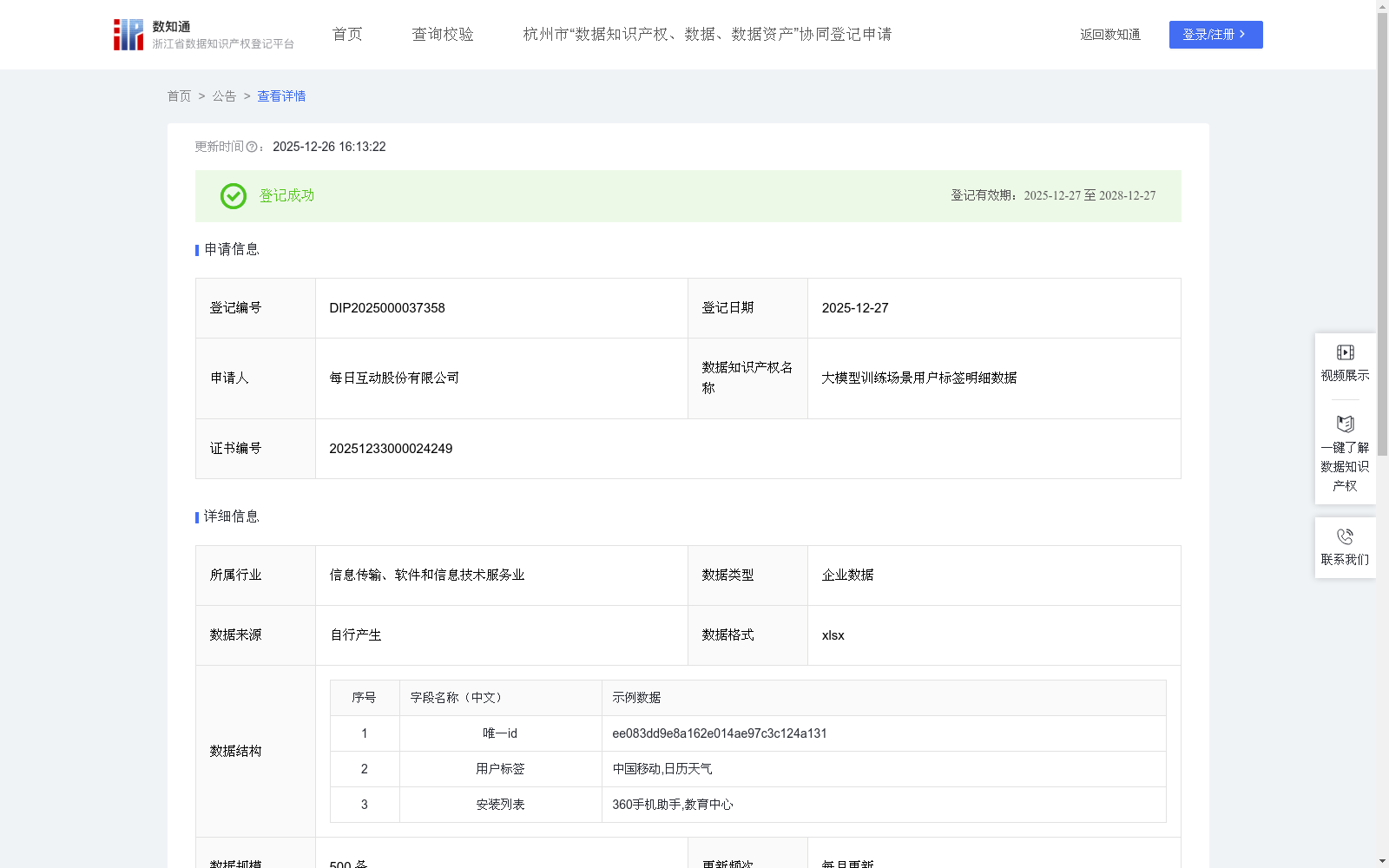
大模型训练场景用户标签明细数据
收藏浙江省数据知识产权登记平台2025-12-26 更新2025-12-27 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8419632
下载链接
链接失效反馈官方服务:
资源简介:
用户标签明细数据通过去标识化技术,将app应用偏好转化为结构化的标签序列。这些现实世界行为关联数据,为大语言模型提供了学习“群体画像-数字习惯”之间复杂关联的优质语料,能直接扩充模型对人类社会经济行为的认知维度,提升其生成与推理的现实合理性。
作为预训练的“社会行为知识库”:数据中“用户标签”与“APP列表”的组合(如“理财人群”常使用“金融理财”APP),能直接教会大模型理解不同人群的生活习惯,显著增强模型在商业分析、产品设计等任务中的基础常识与推理合理性。
用于优化个性化生成任务:在微调营销文案生成、个性化推荐等垂直模型时,该数据是构建高质量指令样本的关键。例如,输入“用户标签:[示例标签]”,可训练模型输出针对该画像的定制化广告语或产品建议。
充当推荐系统与评估的基准:可用于评估大模型在用户偏好推理上的准确性。通过检查模型对标签关联性的预测,可量化并校准模型的“现实感”,减少常识性幻觉。
该数据能有效增强模型的认知能力、生成准确性和商业实用性,具有很强的复用价值。1、数据收集:
通过集成个推软件开发工具包(SDK),实现对海量、离散用户设备使用行为数据的实时与离线采集,采集范围涵盖设备APP安装列表、APP使用时长、功能操作记录、内容浏览轨迹等多维度行为信息。采集后的数据将经过初步格式规整,加工产出以群体设备画像为核心的数据资产,为后续标签生成提供坚实的数据支撑。
2、数据处理:
数据预处理:依托高效数据管道与分布式处理引擎,对采集的原始日志数据进行清洗,剔除重复、异常、无效数据,确保数据质量;同时进行初步聚合,形成以设备为维度的行为数据集。
深度脱敏处理:所有涉及用户标识的核心数据(如设备唯一标识、账号关联信息等),均会经过SHA-256等高强度密码学哈希函数进行单向、不可逆的混淆计算,生成无意义的哈希值替代原始标识。该过程彻底实现数据的匿名化与去标识化,从源头切断信息回溯至特定个人的可能性,为后续标签计算提供安全合规的数据原料。
3、算法加工:
核心遵循“基于SDK采集日志数据,分析后为设备打标签”的规则。采用注意力机制序列模型,挖掘设备行为模式,为那些展现出显著习惯特征(如高频使用理财类APP)的设备打上“理财人群”等群体身份标签。其次,结合逻辑回归等预测模型,依据行为特征推断潜在的人口属性,生成如“退休、买房”等社会特征标签,并附上置信度评估。同时,我们依据自建的语义分类体系,将设备中功能或服务商相近的具体APP进行归类概括,例如,将安装有“中国移动APP”等系列应用归类为“中国移动”这一标准化服务偏好标签,从而将具体行为提升为可被认知的数字偏好描述。
提供机构:
每日互动股份有限公司
创建时间:
2025-12-07
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含500条去标识化的用户标签明细数据,每月更新,适用于大模型训练场景。它通过将APP安装列表转化为结构化标签序列,帮助模型学习群体画像与数字习惯之间的关联,增强在商业分析和个性化生成任务中的现实合理性。数据经过深度脱敏处理,确保安全合规,可作为预训练知识库和评估基准,提升模型的认知能力和商业实用性。
以上内容由遇见数据集搜集并总结生成


