Puding
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/yaopaul/Puding
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个面向问答(question-answering)和文本生成(text-generation)任务的英文文本数据集,采用CC BY-SA 4.0许可协议。数据集包含两种配置:category1_forget(仅含训练集)和category1_retain(包含训练集、验证集和测试集)。用户可通过Hugging Face的datasets库加载不同配置的数据分割,适用于机器学习模型在问答和文本生成领域的研究与开发。
This dataset is an English text dataset for question-answering and text-generation tasks, licensed under CC BY-SA 4.0. It includes two configurations: category1_forget (training set only) and category1_retain (training, validation, and test sets). Users can load different data splits via the Hugging Face datasets library, suitable for research and development of machine learning models in the fields of question answering and text generation.
创建时间:
2026-05-06
原始信息汇总
数据集概述
数据集名称:Puding
数据集地址:https://huggingface.co/datasets/yaopaul/Puding
许可证:CC-BY-SA-4.0
任务类别:
- 问答(question-answering)
- 文本生成(text-generation)
语言:英语(en)
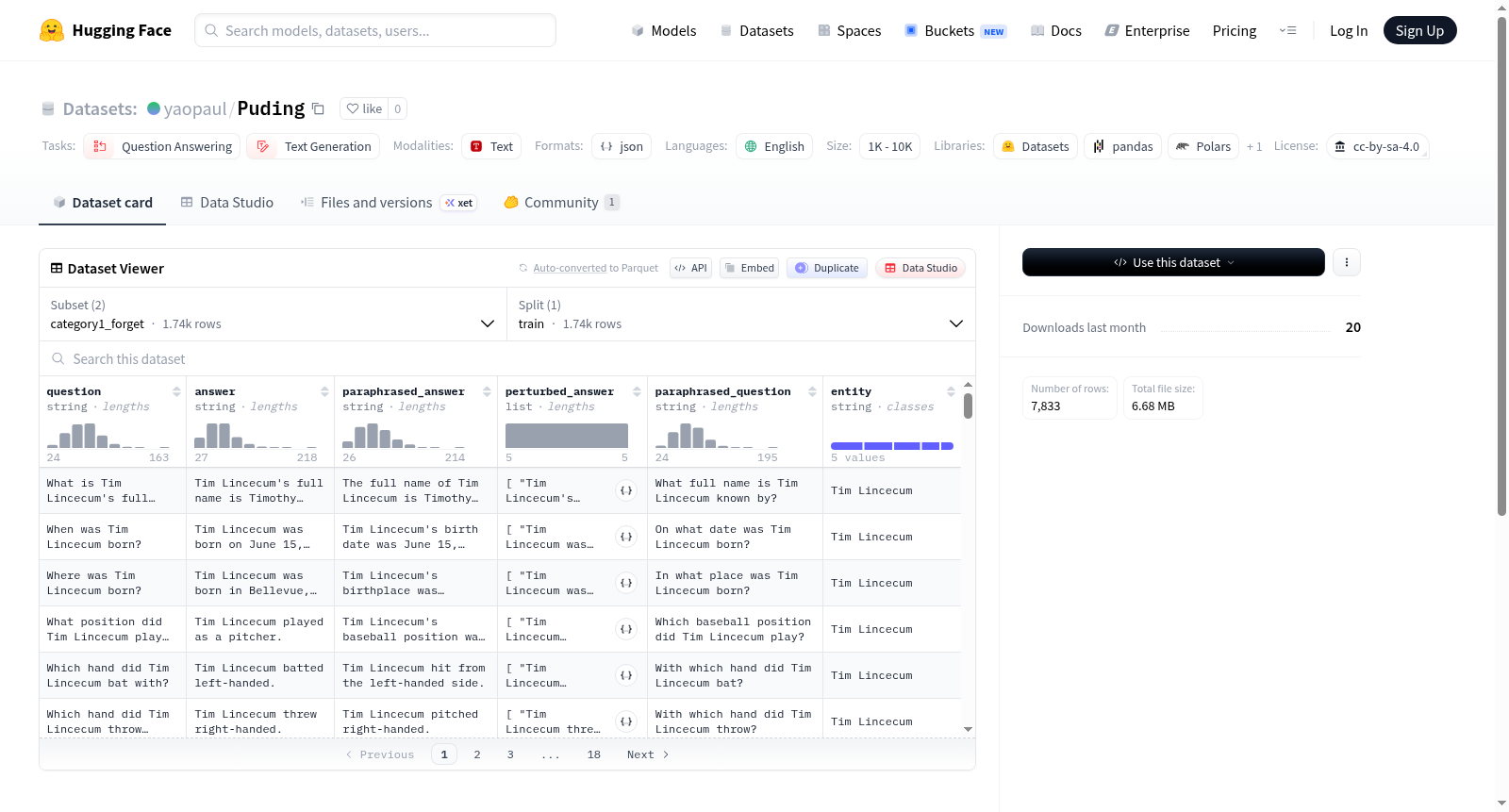
数据集配置与文件结构
该数据集包含两个配置(config),分别用于“遗忘”(forget)和“保留”(retain)场景:
| 配置名称 | 数据文件 | 切分 |
|---|---|---|
| category1_forget | category1_forget-train.json | train |
| category1_retain | category1_retain-train.json | train |
| category1_retain | category1_retain-validation.json | validation |
| category1_retain | category1_retain-test.json | test |
使用示例(Python)
使用 datasets 库加载数据:
python from datasets import load_dataset
加载遗忘数据(训练集)
train_data = load_dataset("yaopaul/Puding", name="category1_forget", split="train")
加载保留数据
retain_train_data = load_dataset("yaopaul/Puding", name="category1_retain", split="train") retain_valid_data = load_dataset("yaopaul/Puding", name="category1_retain", split="validation") retain_test_data = load_dataset("yaopaul/Puding", name="category1_retain", split="test")
搜集汇总
数据集介绍
构建方式
Puding数据集专为机器遗忘(Machine Unlearning)研究而设计,其构建聚焦于特定知识范畴的精确分离。该数据集精心划分了“遗忘(category1_forget)”与“保留(category1_retain)”两大核心配置,其中遗忘集仅包含训练分割,旨在充当待移除知识的语料;保留集则依据标准的数据划分策略,进一步细分为训练、验证与测试三个子集,为模型在剔除目标知识后仍能维持原有能力提供评估基准。通过这种结构化的数据组织,Puding为验证遗忘算法的有效性提供了严谨的测试平台。
特点
Puding数据集最显著的特征在于其二元对立的结构设计,精准服务于机器遗忘这一前沿课题。它并非简单的问答或文本生成数据集,而是通过人为设定“遗忘”与“保留”类别,模拟了模型需要选择性删除特定知识而保持其余能力不变的真实场景。这种设计使得研究者能够量化评估遗忘操作的彻底性以及对模型完整性的影响,从而推动了从“模型训练”到“模型修正”的研究范式转变,为构建更负责任、更具隐私保护能力的人工智能系统提供了宝贵资源。
使用方法
研究者可通过HuggingFace的datasets库便捷地加载Puding数据集。使用时需明确指定配置名称:加载category1_forget配置并仅使用train分割,以获取待遗忘样本;加载category1_retain配置,并分别调用其train、validation与test分割,以获取保留样本用于对比评估。推荐的工作流为:先在保留集上训练或微调模型,随后利用遗忘集执行遗忘算法,最后在保留集的测试分割上评估模型性能,从而全面验证遗忘操作的效果与模型的鲁棒性。
背景与挑战
背景概述
Puding数据集由yaopaul团队构建,专注于机器遗忘(machine unlearning)领域,旨在评估和促进大型语言模型在特定知识移除任务中的表现。该数据集创建于大语言模型广泛应用与隐私合规需求日益增长的背景下,核心研究问题是如何在不破坏模型整体性能的前提下,高效且精准地移除模型对特定(如类别1)知识的学习痕迹。通过提供遗忘集(category1_forget)与保留集(category1_retain)的明确划分,Puding为机器遗忘方法提供了标准化的训练与评测基准,在推动模型隐私保护与伦理治理方面具有重要影响力。
当前挑战
Puding数据集所面临的挑战首先在于领域问题的复杂性:机器遗忘需要在大语言模型中精确识并移除特定知识,同时避免对模型在保留知识上的表现造成负面影响,这一平衡极难把握。其次,构建过程中的挑战在于遗忘集与保留集的严格划分——如何确保类别1的样本真正代表“应遗忘”的知识,且不与其他类别产生语义重叠或隐含关联,是保障数据有效性的关键。此外,数据集的跨句子关系与上下文依赖性增加了遗忘评估的难度,导致遗忘效果的可量化与可验证性成为持续挑战。
常用场景
经典使用场景
Puding数据集专为机器遗忘(Machine Unlearning)任务设计,尤其聚焦于大语言模型在问答与文本生成场景中的选择性遗忘能力。通过构建'category1_forget'和'category1_retain'两组数据,研究者可以指令模型忘却特定类别的知识,同时保持对保留数据的完整推理能力。该数据集常被用于评估遗忘算法在知识类别级别上的有效性,是衡量模型能否精准移除敏感或过时信息的基准。
解决学术问题
Puding数据集直面大语言模型中数据隐私与知识更新的核心矛盾。在学术研究中,它解决了如何在不重训整个模型的前提下,让模型遗忘特定类别知识这一棘手问题。该数据集为机器遗忘算法提供了标准化的评估框架,推动了遗忘精度、模型保留性能与泛化能力之间的权衡研究,其意义在于为构建可信、可追溯的智能系统奠定了实验基础。
衍生相关工作
基于Puding数据集,学术界涌现了诸多模型遗忘领域的经典工作。研究者以此为基础提出基于梯度上升、模型重映射及知识蒸馏的遗忘方法,并衍生出评估遗忘效果的多维指标(如遗忘完成度与模型效用保持率)。部分工作进一步将该数据集扩展至多语言与多领域场景,推动了大语言模型在医疗、法律等高风险领域中的可信遗忘研究。
以上内容由遇见数据集搜集并总结生成


