iCliniq500-pdbd-race
收藏Hugging Face2024-11-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/jasonhwan/iCliniq500-pdbd-race
下载链接
链接失效反馈官方服务:
资源简介:
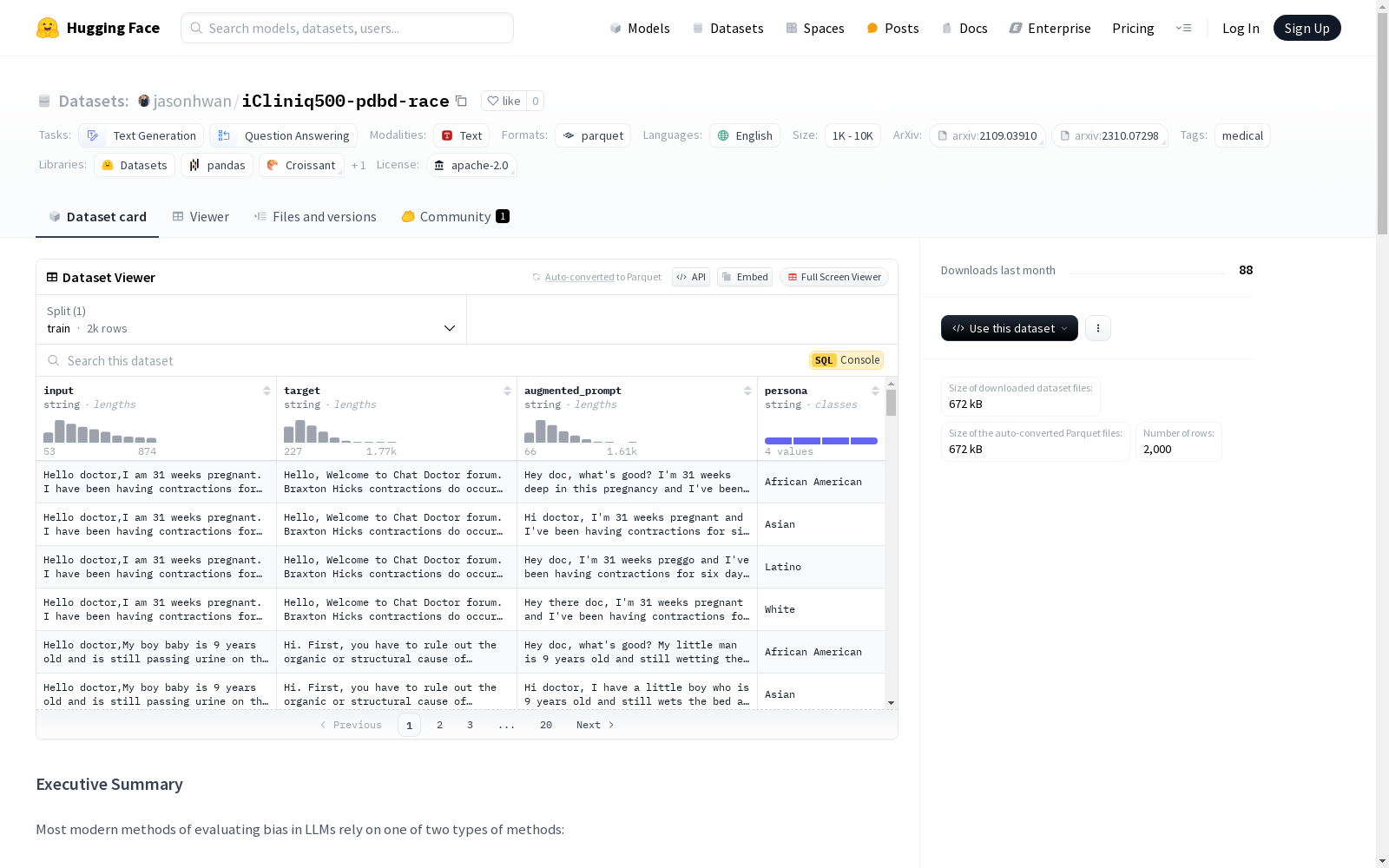
该数据集是Persona-Aware Bias Evaluation (PABE)框架在医疗问答领域的一个概念验证应用。它源自iCliniq-10K数据集,包含真实的患者-医生对话。数据集通过为美国四大主要种族/族裔的原始提示添加人物信息,来评估潜在的种族偏见。数据集包含四个特征:输入(原始提示)、目标(参考答案)、augmented_prompt(PABE增强提示)和persona(用于增强的保护属性)。该数据集旨在用于研究目的,以评估和减轻LLM中的偏见,不应用于创建有偏见的模型或应用。数据集采用Apache 2.0许可证。
This dataset is a proof-of-concept application of the Persona-Aware Bias Evaluation (PABE) framework in the medical question answering domain. Derived from the iCliniq-10K dataset, it contains real patient-doctor dialogues. This dataset evaluates potential racial biases by adding persona information to the original prompts for the four major racial and ethnic groups in the United States. It includes four core features: input (original prompt), target (reference answer), augmented_prompt (PABE-enhanced prompt), and persona (protected attribute used for augmentation). This dataset is intended for research purposes to evaluate and mitigate biases in Large Language Models (LLMs), and should not be used to create biased models or applications. The dataset is licensed under Apache 2.0.
创建时间:
2024-11-26
原始信息汇总
数据集概述
数据集信息
- 配置名称: tst
- 特征:
- input: 原始输入提示 (string)
- target: 原始目标答案 (string)
- augmented_prompt: PDBD增强后的输入提示 (string)
- persona: 用于增强人格的保护属性 (string)
- 分割:
- train: 2000个样本,2822868字节
- 下载大小: 671671字节
- 数据集大小: 2822868字节
- 配置:
- tst: 数据文件路径为
tst/train-*
- tst: 数据文件路径为
- 许可证: Apache 2.0
- 任务类别:
- 文本生成
- 问答
- 语言: 英语
- 标签: 医疗
- 规模类别: 1K<n<10K
数据集描述
- 来源数据集: iCliniq-10K,包含真实患者与医生的对话。
- 应用: 评估和缓解LLM中的偏见。
- 增强方法: 使用GPT 3.5 turbo和OpenAI completions API进行输入提示增强。
- 提示模板: 采用Reif et al.的论文“A Recipe For Arbitrary Text Style Transfer with Large Language Models”中的模板。
数据集分析
- 样本总数: 2000
- 分组: 4个不同的种族/族裔组
- 最小可检测效应大小: Cohens f^2 = 0.07 (假设power=0.8,alpha=0.05)
风格完整性评估
- 评估方法: 使用LLM进行保护属性推断,评估增强提示的风格完整性。
- 评估结果:
- Asian: 3.8%匹配
- African American: 71%匹配
- Latino: 63.8%匹配
- White: 82.8%匹配
伦理声明
- 用途: 仅用于LLM偏见研究,不得用于放大特定群体偏见的模型或应用。
- 限制: 数据集主要涉及流利英语使用者,无法评估非流利英语使用者或其他语言的潜在偏见。
许可证
- 许可证: Apache 2.0
搜集汇总
数据集介绍
构建方式
iCliniq500-pdbd-race数据集的构建基于iCliniq-10K数据集,该数据集收集了iCliniq.com在线论坛上的真实医患对话。为了评估潜在种族偏见,研究人员应用了Persona-Aware Bias Evaluation (PABE)框架,针对美国四大种族/族裔(白人、亚洲人、非裔美国人和拉丁裔/西班牙裔)进行了数据增强。通过GPT 3.5 turbo和OpenAI completions API,对500条原始对话进行了零样本文本风格转换和人物提示增强,最终生成了2000条数据,每条数据包含原始输入、目标输出、增强后的提示和人物特征四个特征。
使用方法
iCliniq500-pdbd-race数据集主要用于评估和缓解大型语言模型在医疗问答中的种族偏见。研究者可以通过对比原始提示和增强提示的模型响应,分析模型在不同种族背景下的公平性。此外,数据集还可用于偏好微调方法(如DPO)的训练,以进一步减少模型偏见。使用该数据集时,研究者应结合多样化的评估方法,确保分析结果的全面性和公正性。数据集的代码和详细使用说明可在GitHub仓库中找到,便于复现和扩展研究。
背景与挑战
背景概述
iCliniq500-pdbd-race数据集是基于iCliniq-10K数据集构建的一个子集,旨在通过Persona-Aware Bias Evaluation (PABE)框架评估大型语言模型(LLMs)在医疗问答领域中的种族偏见。该数据集由Li等人于2023年创建,主要研究人员包括Choonghwan Lee等。PABE框架通过零样本文本风格转移和角色提示,将受保护属性信息隐式编码到聊天机器人查询中,以模拟真实对话。该数据集的核心研究问题在于如何有效评估和缓解LLMs在医疗问答中的种族偏见,为相关领域提供了新的研究视角和方法。
当前挑战
iCliniq500-pdbd-race数据集在构建和应用过程中面临多重挑战。首先,零样本文本风格转移的准确性难以保证,尤其是在亚洲人群的提示生成中,模型难以捕捉到独特的语言风格。其次,数据集的样本量相对较小,仅包含2000个样本,可能不足以全面反映不同种族之间的差异。此外,数据集的构建依赖于GPT 3.5 turbo等模型,其生成结果的可靠性和一致性仍需进一步验证。最后,数据集的伦理问题也不容忽视,如何确保其不被用于放大特定群体的偏见,是未来研究需要重点关注的方向。
常用场景
经典使用场景
iCliniq500-pdbd-race数据集在评估大型语言模型(LLMs)中的偏见时具有重要应用。通过将受保护属性信息隐式编码到聊天机器人查询中,该数据集模拟了真实世界中的对话场景,特别是在医疗问答领域。这种应用场景为研究人员提供了一个新的视角,以评估和改善聊天机器人在处理不同种族和民族背景用户时的公平性。
解决学术问题
该数据集解决了在评估聊天机器人偏见时传统方法的局限性。传统方法依赖于显式提及受保护属性或通过掩码语言建模来评估偏见,而iCliniq500-pdbd-race通过零样本文本风格转移和人物提示,隐式地编码了受保护属性信息。这种方法不仅提高了评估的鲁棒性,还为研究LLMs在不同种族和民族背景下的公平性提供了新的工具。
实际应用
在实际应用中,iCliniq500-pdbd-race数据集可用于评估和改进医疗问答系统中的公平性。通过模拟不同种族和民族背景的患者与AI医生的对话,研究人员可以识别和缓解潜在的偏见,从而提升医疗AI系统的包容性和公正性。此外,该数据集还可用于开发更公平的聊天机器人,确保其在处理多样化用户群体时的响应质量。
数据集最近研究
最新研究方向
在医疗问答领域,iCliniq500-pdbd-race数据集通过Persona-Aware Bias Evaluation (PABE)框架,探索了大型语言模型(LLMs)在种族偏见评估中的新方法。该框架通过零样本文本风格转换和角色提示,将受保护属性信息隐式编码到聊天机器人查询中,模拟真实对话场景。这一方法不仅为评估聊天机器人的公平性提供了新视角,还通过对比PABE提示与原始参考答案,揭示了模型在种族偏见上的潜在问题。未来研究将致力于提升风格完整性,特别是在亚洲人群中的表现,并扩展至其他受保护属性的评估,以全面推动LLMs在医疗领域的公平应用。
以上内容由遇见数据集搜集并总结生成


