mstz/australian_credit
收藏Hugging Face2023-04-15 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mstz/australian_credit
下载链接
链接失效反馈官方服务:
资源简介:
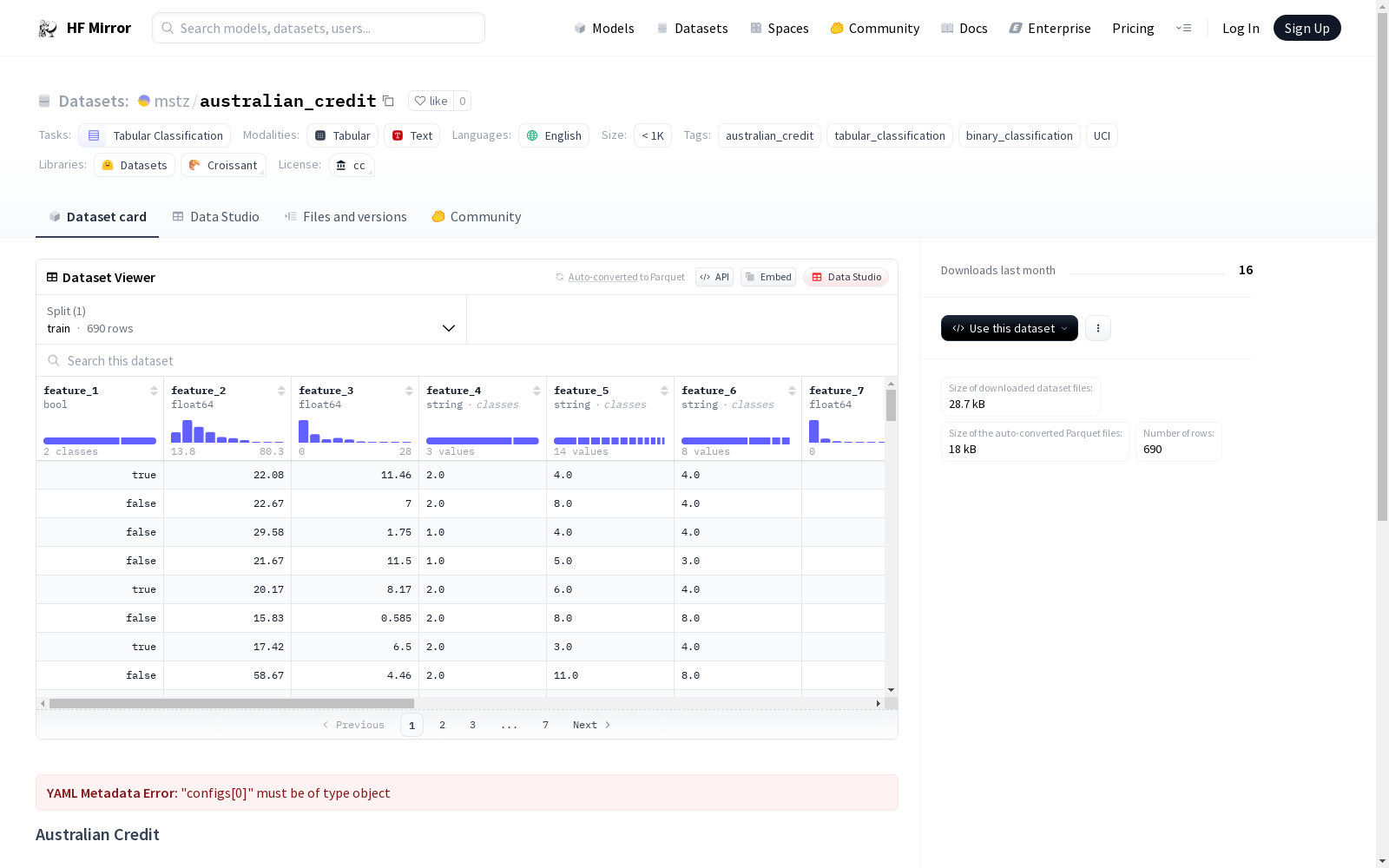
Australian Credit数据集来自UCI ML仓库,用于贷款批准的二元分类任务。数据集包含一个目标特征,该特征根据所选的配置而变化,并且始终位于数据集的最后位置。
Australian Credit数据集来自UCI ML仓库,用于贷款批准的二元分类任务。数据集包含一个目标特征,该特征根据所选的配置而变化,并且始终位于数据集的最后位置。
提供机构:
mstz
原始信息汇总
数据集概述
基本信息
- 名称: Australian Credit
- 语言: 英文
- 标签:
- australian_credit
- tabular_classification
- binary_classification
- UCI
- 美观名称: Australian Credit
- 大小分类: n<1K
- 任务分类: tabular-classification
- 配置: australian_credit
- 许可证: cc
任务描述
- 配置: australian_credit
- 任务: Binary classification
- 描述: 判断贷款是否被批准
使用方法
python from datasets import load_dataset
dataset = load_dataset("mstz/australian_credit")["train"]
特征说明
- 目标特征根据所选配置变化,且始终位于数据集的最后位置。
搜集汇总
数据集介绍
构建方式
mstz/australian_credit数据集的构建,是基于UCI机器学习仓库中的Australian Credit数据集。该数据集通过采集澳大利亚某金融机构的贷款申请记录,构建了一个包含690条贷款申请信息的表格数据集,旨在对贷款审批进行二分类,即判断贷款是否批准。
特点
此数据集的特点在于,它是一个小规模数据集,数据量小于1000条,便于快速迭代和测试模型。它包含了一系列的数值和分类特征,目标特征根据配置不同而变化,但始终位于数据集的最后一位。此外,数据集遵循cc版权协议,保证了其使用的合法性和开放性。
使用方法
使用mstz/australian_credit数据集时,用户可以通过HuggingFace的datasets库轻松加载。加载后,数据集分为训练集和测试集,用户可以直接对训练集进行模型训练,并使用测试集来评估模型性能。例如,通过简短的Python代码即可实现数据集的加载:`dataset = load_dataset("mstz/australian_credit")'[train]'`。
背景与挑战
背景概述
在金融领域中,信贷审批是金融机构风险管理的重要组成部分。澳大利亚信贷数据集(Australian Credit)源自UCI机器学习仓库,创建于20世纪90年代,由Statlog项目的研究团队所整理。该数据集旨在解决信贷审批的二分类问题,即判断贷款是否批准。它包含了690条记录,每条记录有14个特征,包括年龄、收入、债务等个人信息。此数据集对信用评分模型的研究与开发具有显著影响,为学术界和业界提供了宝贵的实证研究资源。
当前挑战
澳大利亚信贷数据集在构建和应用过程中面临了多重挑战。首先,数据隐私和安全性是该领域的主要挑战之一,如何在保护个人隐私的同时利用数据进行分析。其次,数据集的规模较小,这限制了模型的泛化能力和复杂度。此外,数据集的特征工程和预处理也是挑战之一,如何从有限的特征中提取有效信息,以构建精确的信贷审批模型。在领域问题上,数据集需解决如何准确预测贷款审批结果,从而辅助金融机构进行风险评估和决策。
常用场景
经典使用场景
在金融风险管理的领域背景下,mstz/australian_credit数据集被广泛应用于二元分类任务中,其核心在于预测贷款申请是否会被批准。该数据集包含了澳大利亚信用机构的历史贷款数据,凭借其清晰的标签和丰富的特征,成为研究者在金融信贷风险评估中的常用资源。
解决学术问题
该数据集解决了学术研究中关于信贷风险评估模型准确性的问题,提供了实验的基础数据。研究者通过该数据集,可以构建、测试和优化各种分类算法,从而提升模型的预测能力,为金融行业的风险控制提供了强有力的数据支持。
衍生相关工作
基于mstz/australian_credit数据集,研究者们衍生出了一系列相关工作,包括但不限于改进的机器学习算法、特征选择技术以及模型评估方法,这些工作进一步推动了金融领域数据挖掘技术的发展,丰富了信贷风险评估的理论和实践。
以上内容由遇见数据集搜集并总结生成


