jp-disease-finding-dataset
收藏官方服务:
资源简介:
该数据集从大约7千篇日本医学期刊文章中提取了信息(来源:《日本内科学会杂志》,2003年至2023年)。每篇文章包括疾病名称(日语)、相关症状/检查/并发症列表以及用词的引文描述。数据集还包括文章的元数据,如文章ID、作者、期刊信息、URL等。数据以JSON-Lines格式存储,每个疾病一个条目。
创建时间:
2025-04-28
原始信息汇总
数据集概述
基本信息
- 数据集名称: Disease–Finding Pairs from Japanese Internal‐Medicine Journals
- 语言: 日语 (ja)
- 许可证:
- CC BY 4.0
- 其他 (journal copyright policy)
- 数据集大小: 39,414,035 字节
- 下载大小: 11,611,040 字节
- 样本数量: 10,578 (训练集)
数据集结构
特征
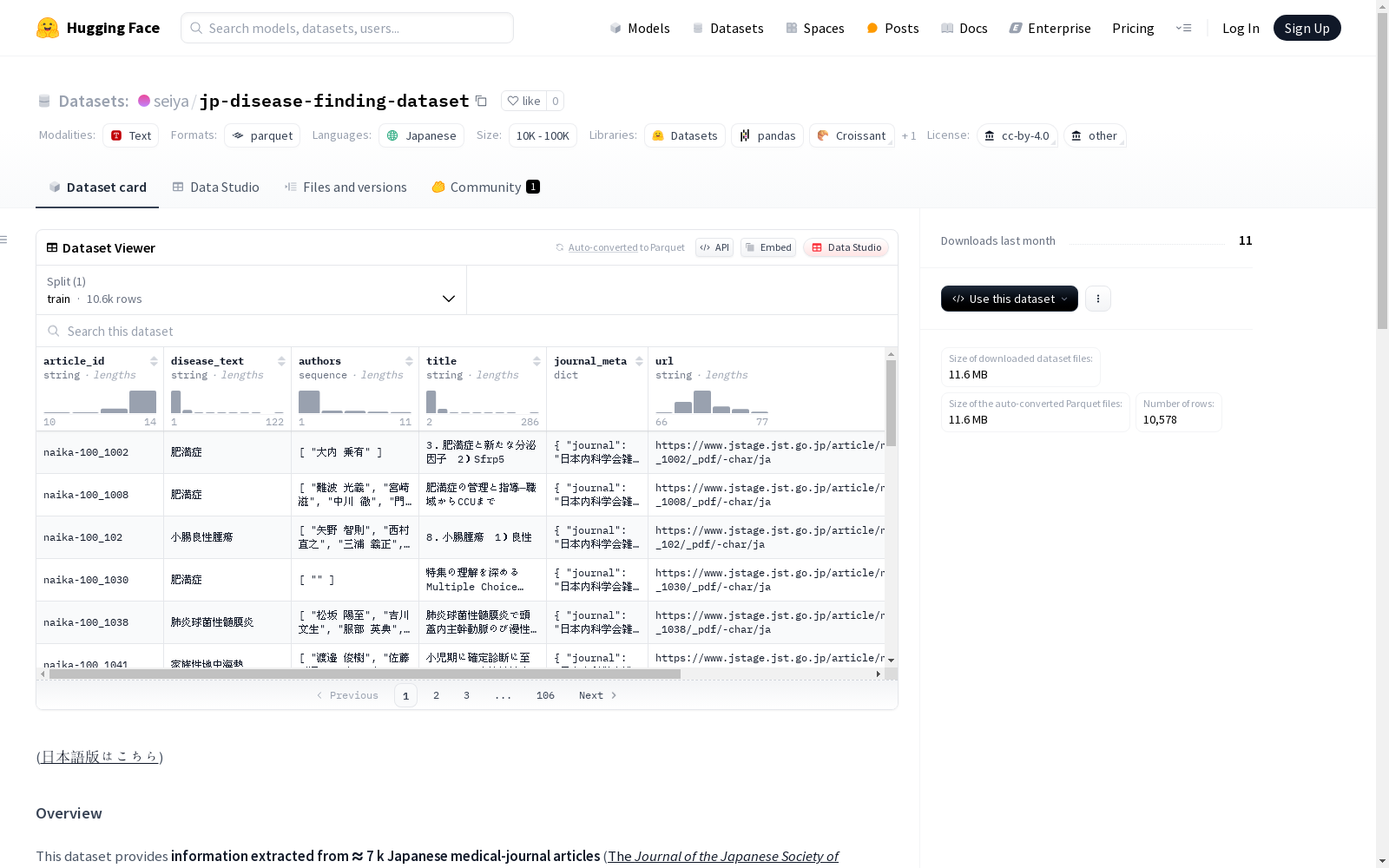
article_id: 字符串disease_text: 字符串 (疾病名称,日语)authors: 字符串序列title: 字符串journal_meta: 结构体journal: 字符串year: int64volume: int64issue: int64pages: 字符串
url: 字符串findings: 列表finding_text: 字符串finding_type: 字符串finding_description: 字符串
数据文件
- 格式: JSON-Lines (
disease_level.jsonl) - 内容: 每行代表一个疾病及其相关信息
数据来源
- 来源期刊: The Journal of the Japanese Society of Internal Medicine (2003 – 2023)
- 提取工具: GPT-4.1-mini
许可与使用
结构化事实
- 文件/列:
disease_level.jsonl(除finding_description外的所有内容) - 许可证: CC BY 4.0
- 允许用途: 商业和非商业用途,包括再分发、改编和机器学习,需署名。
引用的日语片段
- 列:
finding_description - 许可证: 期刊版权政策
- 允许用途: 建议非商业用途;不得更改措辞;需保留文章元数据。
期刊版权政策
- 日语期刊: 未明确显示 Creative Commons 许可证
- 英文期刊: CC BY-NC-ND 4.0
OpenAI 输出通知
- 限制: 不得使用这些输出来开发与 OpenAI 竞争的模型。
致谢
- 支持机构: JSPS KAKENHI Grant Number JP22K12263
引用
- 引用信息: 目前正在准备中...
搜集汇总
数据集介绍
构建方式
该数据集通过GPT-4.1-mini模型从约7000篇日本内科学会期刊(2003-2023年)中提取信息构建而成,涵盖了疾病名称、相关症状、检查结果及并发症等结构化数据。每行数据代表一个疾病实体,包含疾病文本、发现列表(症状、检查等)、引用描述及文章元数据,确保了数据的学术性和完整性。数据的提取和处理严格遵循学术引用规范,特别注重对原始日文片段的准确引用。
使用方法
使用该数据集时,建议首先了解其许可限制,结构化数据可用于商业和非商业用途,但需注明出处;引用片段则推荐非商业使用且不得修改原文。数据集以JSON-Lines格式提供,便于逐行处理和分析。用户可通过article_id、疾病名称或发现类型等字段进行检索和筛选,结合原始期刊元数据可进一步验证或扩展研究。注意遵守OpenAI条款,禁止使用相关输出开发竞争模型。
背景与挑战
背景概述
jp-disease-finding-dataset数据集由日本内科学会期刊的医学文献构建而成,涵盖了2003至2023年间约7千篇日文医学论文的疾病与症状关联信息。该数据集由日本学术振兴会(JSPS)资助,旨在为医学自然语言处理领域提供高质量的疾病-症状关联标注数据。通过GPT-4.1-mini模型自动化提取的疾病名称、临床表现及相关引文,为临床决策支持系统和医学知识图谱构建提供了重要资源。其跨二十年期刊文献的覆盖范围,显著提升了日语医学实体识别和关系抽取研究的基准水平。
当前挑战
该数据集面临的核心挑战在于医学实体标注的准确性与一致性。日文医学文献中疾病名称和症状描述存在大量专业术语和变体表达,自动化提取过程中易出现实体边界识别错误。同时,数据集构建受限于期刊版权政策,引文内容仅限非商业用途,制约了数据的广泛应用。此外,GPT-4生成内容受OpenAI使用条款限制,禁止用于开发竞争模型,这对医学大模型的研究形成法律壁垒。如何平衡学术引用规范与数据效用最大化,成为该数据集推广应用的关键难题。
常用场景
经典使用场景
在医学信息抽取领域,jp-disease-finding-dataset为研究者提供了丰富的日文内科疾病与相关症状、检查结果的配对数据。该数据集通过结构化呈现疾病名称、临床表现及原始文献引用,成为构建医学知识图谱的理想素材。其经典应用场景包括训练自然语言处理模型识别疾病-症状关联,以及辅助开发临床决策支持系统的核心算法模块。
解决学术问题
该数据集有效解决了医学文本挖掘中的关键挑战,包括跨语言医学实体识别、临床术语标准化以及非英语医学文献的知识抽取问题。通过提供精确标注的疾病-发现对,研究人员能够深入探究日文医学文本的语义特征,填补了亚洲语言医学NLP研究的数据空白,对推动循证医学的知识发现具有重要意义。
实际应用
在实际医疗场景中,该数据集支持开发智能分诊系统,通过匹配患者主诉与标准医学术语库提升初诊效率。医疗机构可利用其构建本地化临床知识库,辅助医师快速检索相关病例文献。医药企业则借助这些结构化数据优化药物不良反应监测系统,特别是在日语语境下的药物安全信号检测。
数据集最近研究
最新研究方向
近年来,随着自然语言处理技术在医疗领域的深入应用,jp-disease-finding-dataset作为日本内科医学期刊疾病-发现配对数据集,正逐渐成为研究热点。该数据集通过GPT-4.1-mini模型从约7000篇日本医学期刊文章中提取疾病名称及相关症状、检查结果和并发症等信息,为医疗文本挖掘和知识图谱构建提供了宝贵资源。在医学信息抽取领域,研究者们正利用该数据集探索疾病与临床表现之间的复杂关联,推动临床决策支持系统的发展。同时,结合大语言模型的技术优势,该数据集在自动化病历分析、疾病预测模型构建等方面展现出巨大潜力。值得注意的是,数据集中的日文医学文本为跨语言医学NLP研究提供了独特视角,促进了不同语言背景下医疗知识的融合与共享。
以上内容由遇见数据集搜集并总结生成


