profile-data
收藏github2025-03-21 更新2025-02-28 收录
下载链接:
https://github.com/deepseek-ai/profile-data
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了从训练和推理框架中捕获的剖析数据,旨在帮助社区更好地理解通信-计算重叠策略和低层实现细节。数据使用PyTorch Profiler捕获,并可以通过Chrome或Edge浏览器的tracing工具进行可视化。数据集展示了在DualPipe中的前向和后向块的重叠策略,以及在不同配置下的预填充和解码阶段的剖析数据。
This dataset contains profiling data captured from training and inference frameworks, aiming to help the research community better understand communication-computation overlap strategies and low-level implementation details. The data is captured using PyTorch Profiler, and can be visualized via the tracing tools of Chrome or Edge browsers. The dataset showcases the overlap strategies of forward and backward blocks in DualPipe, as well as profiling data of the prefill and decoding stages under different configurations.
创建时间:
2025-02-26
原始信息汇总
DeepSeek Infra 性能分析数据集概述
数据集来源
- 由DeepSeek Infra公开分享的训练和推理框架性能分析数据
数据采集方式
- 使用PyTorch Profiler采集
- 采用绝对平衡的MoE路由策略进行模拟
训练数据
- 数据文件: train.json
- 配置参数:
- 并行配置: EP64, TP1
- 序列长度: 4K
- 特点:
- 展示DualPipe中单个前向和后向块的通信-计算重叠策略
- 每个块包含4个MoE层
- 未包含PP通信
推理数据
预填充阶段
- 数据文件: prefill.json
- 配置参数:
- 并行配置: EP32, TP1
- 提示长度: 4K
- 每GPU批处理大小: 16K tokens
- 特点:
- 使用2个微批次重叠计算和all-to-all通信
- 注意力计算负载在微批次间平衡
解码阶段
- 数据文件: decode.json
- 配置参数:
- 并行配置: EP128, TP1
- 提示长度: 4K
- 每GPU批处理大小: 128 requests
- 特点:
- 使用2个微批次重叠计算和all-to-all通信
- all-to-all通信不占用GPU SMs
- 采用RDMA消息实现
搜集汇总
数据集介绍
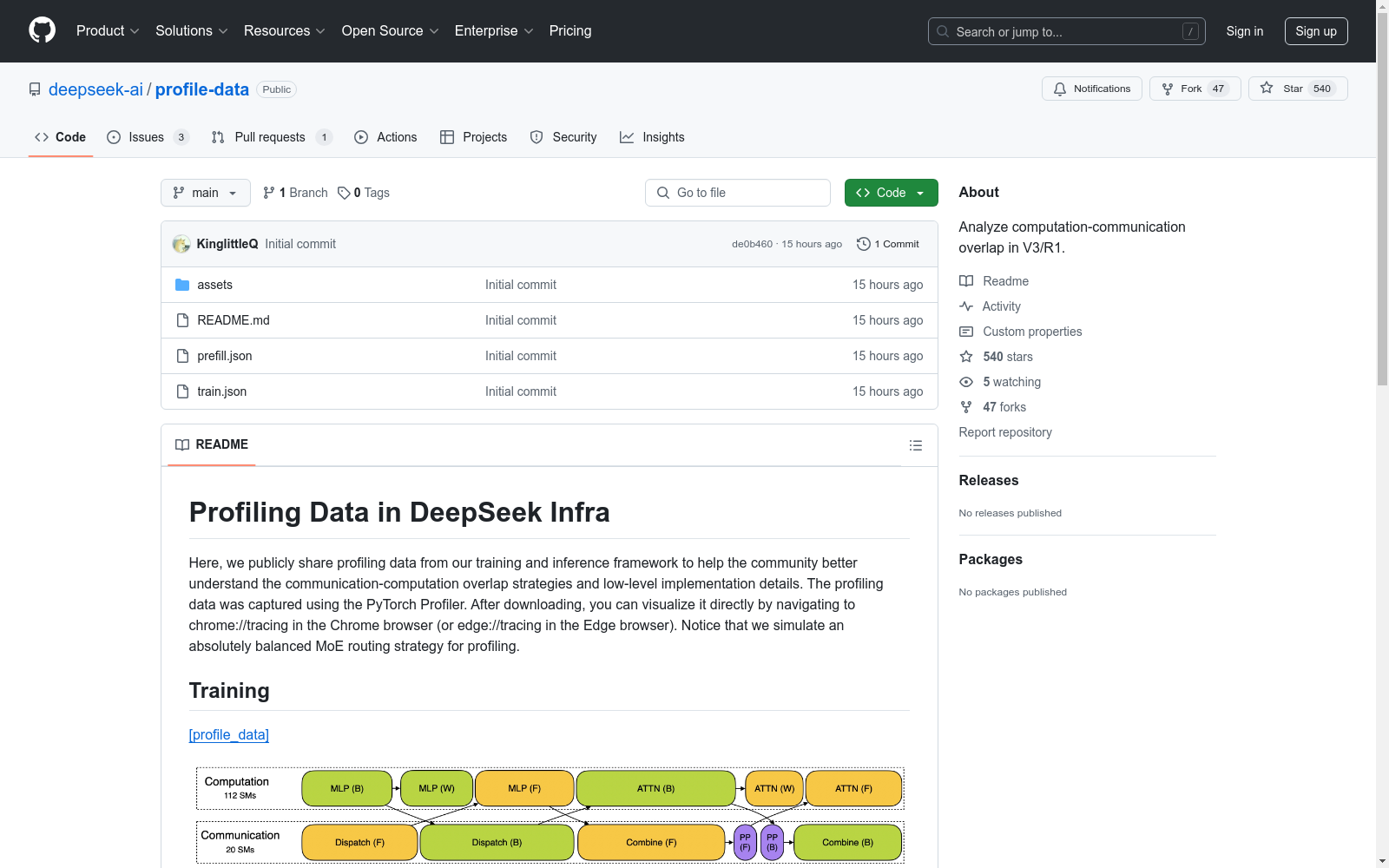
构建方式
Profiling Data in DeepSeek Infra数据集的构建,是基于DeepSeek Infra训练和推理框架的剖析数据。这些数据通过PyTorch Profiler捕获,旨在帮助研究者深入理解通信计算融合策略以及底层实现细节。数据集的构建过程中,模拟了一种绝对平衡的MoE路由策略进行剖析。
使用方法
使用该数据集时,用户可以直接下载并利用Chrome或Edge浏览器内置的跟踪功能进行数据可视化。用户需要关注的是,数据集中的剖析结果并不包括PP通信,这是出于简化考虑。此外,数据集的解读需要结合DualPipe和DeepEP等相关项目文档,以更全面地理解剖析数据背后的机制。
背景与挑战
背景概述
Profiling Data in DeepSeek Infra数据集,是在深度学习模型训练与推理过程中,为了帮助研究界更好地理解通信计算融合策略及底层实现细节而公开共享的剖析数据。该数据集的创建,源自于DeepSeek Infra的研究工作,由DeepSeek AI团队负责实施。其核心研究问题聚焦于优化深度学习模型中的通信与计算效率,特别是针对Mixture of Experts架构的剖析。数据集自发布以来,对深度学习模型性能优化领域产生了显著的影响,推动了相关技术的发展。
当前挑战
该数据集在研究领域面临的挑战主要涉及两个方面:一是如何准确解析通信与计算重叠策略在深度学习模型中的具体影响,二是剖析数据在构建过程中,如何有效模拟平衡的MoE路由策略,以及如何在不同的训练与推理阶段(如prefilling和decoding)优化数据并行与模型并行的配置。此外,数据集在构建过程中还需克服如何保持GPU计算单元的高效利用,以及如何精确量化all-to-all通信对计算性能的影响等挑战。
常用场景
经典使用场景
在深度学习模型训练与推理的优化研究领域,Profiling Data in DeepSeek Infra数据集提供了关键的通信与计算重叠策略的低层实现细节。该数据集通过PyTorch Profiler捕获,可直观地展现DualPipe框架中前向与反向传播的个体块的重叠策略,对于理解并优化通信与计算资源分配具有不可或缺的作用。
解决学术问题
该数据集解决了深度学习模型在训练与推理过程中如何有效利用计算资源与通信资源的问题。通过分析数据集中的配置和策略,研究人员能够更深入地了解MoE路由策略的平衡性,以及如何通过微批处理实现计算与通信的优化重叠,进而提升模型的整体性能和效率。
实际应用
实际应用中,该数据集为优化大规模深度学习模型的部署提供了重要参考。通过数据集提供的训练和推理配置,开发者能够针对特定的硬件环境调整模型参数,实现更高效的资源利用和更快的模型响应时间,这对于在线服务和实时数据处理等领域尤为重要。
数据集最近研究
最新研究方向
在深度学习模型的训练与推理过程中,有效管理计算与通信的协同是提升效率的关键。Profiling Data in DeepSeek Infra数据集公开了深度学习训练与推理框架的详细分析数据,旨在帮助研究界深入理解通信与计算融合策略以及底层实现细节。近期研究集中于利用该数据集优化MoE路由策略,并针对DualPipe框架中的前向和反向传播块进行重叠策略的实证分析。此研究有助于优化大规模预训练模型的并行计算效率,特别是在处理长序列和大规模批处理时,对于平衡计算负载和通信延迟具有重要意义。
以上内容由遇见数据集搜集并总结生成


