instructpoet-ar
收藏Hugging Face2026-04-20 更新2026-04-21 收录
下载链接:
https://huggingface.co/datasets/MBZUAI/instructpoet-ar
下载链接
链接失效反馈官方服务:
资源简介:
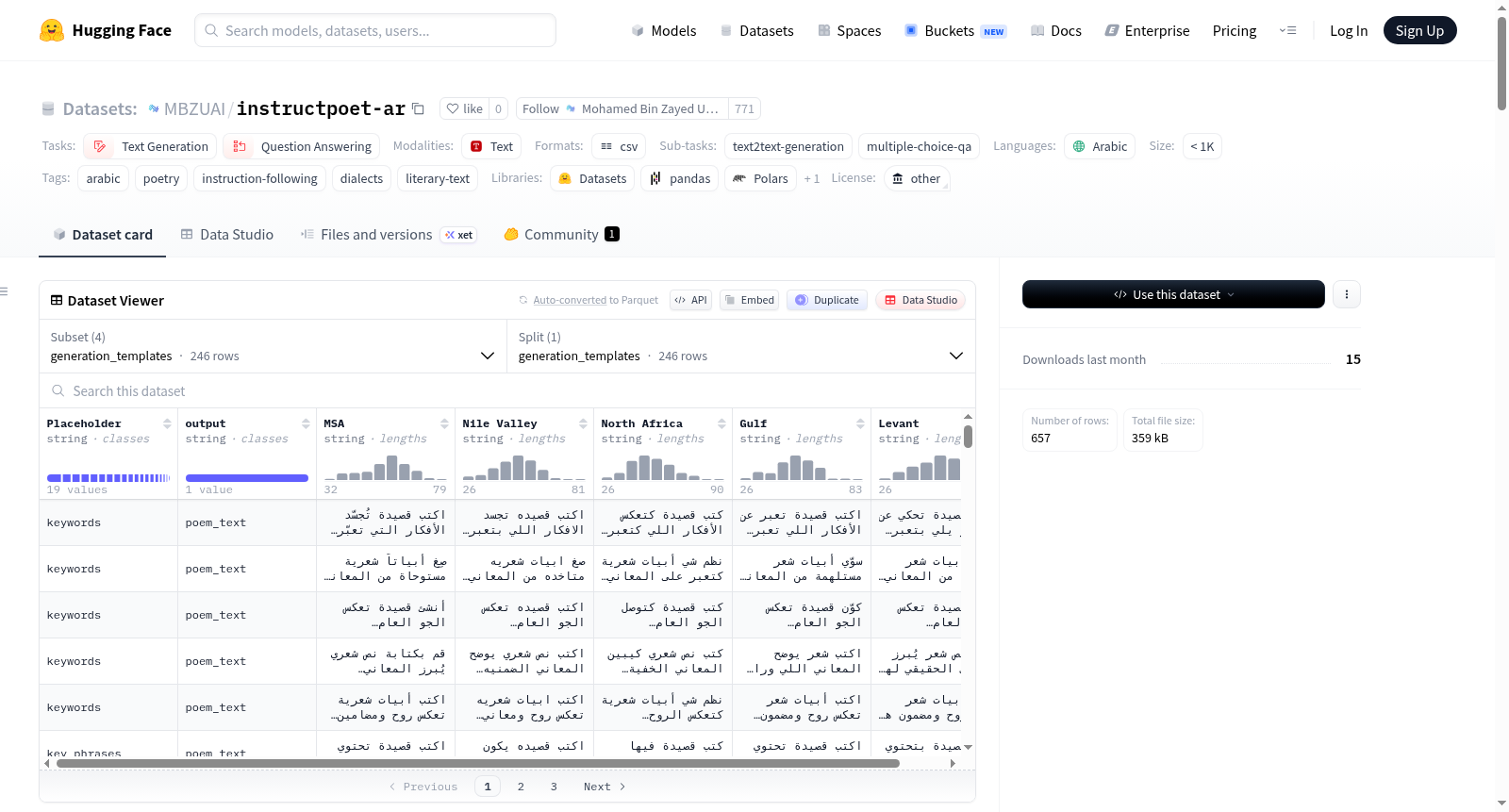
Arabic Poetry IFT 是一个大规模阿拉伯诗歌理解与共同创作的指令跟随数据集,支持生成、续写、修订/恢复和多选分析四大任务家族。数据集涵盖现代标准阿拉伯语(MSA)及四种地区方言(海湾、黎凡特、尼罗河谷和北非阿拉伯语)。数据集包含1,350,897个训练对和24,815个测试对,总计1,375,712个示例。数据来源包括多个公开文学资源,经过统一格式、丰富元数据和去重处理。元数据包括诗歌文本、标题、诗人、时代、体裁、韵律等。数据集通过手动设计的指令模板扩展至五种阿拉伯语变体,适用于阿拉伯诗歌能力语言模型的指令调优、可控生成研究及诗歌分析基准测试。
提供机构:
Mohamed Bin Zayed University of Artificial Intelligence
创建时间:
2026-04-20
搜集汇总
数据集介绍
构建方式
在阿拉伯诗歌研究领域,数据集的构建需兼顾文学传统与计算需求。该数据集通过整合多个公开文学资源,如Ashaar、PoetsGate等,汇集了超过42万首诗歌,并经过统一格式化与元数据丰富处理。为确保数据质量,研究团队进行了去重与规范化操作,包括移除单节诗歌、自动推断押韵模式,并采用Gemini 2.5 Pro自动生成关键词与关键短语。为避免训练与测试数据泄露,与FannOrFlop基准重叠的诗歌均从训练集中剔除。最终,通过人工设计的644个基础指令模板,扩展至涵盖现代标准阿拉伯语及四种方言变体的3220个模板,形成了覆盖生成、续写、修订与分析四大任务的大规模指令遵循数据集。
特点
该数据集在阿拉伯诗歌计算语言学领域展现出多维度特色。其核心在于覆盖现代标准阿拉伯语及海湾、黎凡特、尼罗河谷、北非四种方言变体,为研究方言对诗歌生成的影响提供了丰富语料。数据规模庞大,包含约135万训练样本与2.4万测试样本,支持生成、续写、修订与分析四类任务,其中修订任务更细分为八种诗歌破坏类型,如韵律结构破坏、时代风格腐蚀等。元数据体系完备,涵盖诗人、时代、体裁、韵律、押韵等关键属性,且关键词自动提取经人工验证达到96%的质量合格率。这种多任务、多方言、多属性的综合设计,使其成为探索阿拉伯诗歌可控生成与深度分析的理想资源。
使用方法
在应用层面,该数据集为阿拉伯诗歌的语言模型研究提供了结构化路径。研究者可直接将其用于指令微调,以提升模型在诗歌生成、续写及风格控制方面的能力。数据集内嵌的四大任务配置允许用户针对特定目标进行训练,例如利用生成模板进行条件创作,或通过分析模板构建诗歌元数据问答系统。测试基准FannOrFlop的独立存在确保了模型评估的公正性。使用时可依据四个子集(生成、续写、分析、破坏模板)加载对应CSV文件,每个示例均包含指令、输出及多方言指令列,支持跨方言的鲁棒性研究。该设计使得数据集既能服务于端到端的模型训练,也能支撑诗歌计算领域的专项评测与对比分析。
背景与挑战
背景概述
阿拉伯诗歌作为世界文学宝库中的璀璨明珠,其语言精妙、格律严谨,承载着深厚的文化内涵。然而,传统阿拉伯诗歌的计算语言学研究长期面临数据稀缺与任务单一的困境,尤其在方言诗歌与指令跟随任务方面缺乏系统性资源。为应对这一挑战,研究团队于2026年发布了instructpoet-ar数据集,该数据集由Abdelrahman Sadallah、Kareem Elozeiri、Preslav Nakov等多位学者联合构建,旨在通过大规模指令微调框架推动阿拉伯诗歌的理解与协同创作。该数据集的核心研究问题聚焦于如何利用现代自然语言处理技术,实现对古典与现代阿拉伯诗歌的生成、续写、修复及多维度分析,其创新性地覆盖了现代标准阿拉伯语及四大方言变体,为阿拉伯语诗歌计算模型的发展奠定了重要基础。
当前挑战
在阿拉伯诗歌计算化领域,核心挑战在于如何精准建模诗歌的复杂格律、韵脚与风格,同时处理方言变体带来的语言变异问题。instructpoet-ar数据集构建过程中,研究团队面临多重技术难题:首先,诗歌源数据的收集与整合需从多个异构文学资源中提取,并进行去重与元数据标注,其中韵律的自动推断依赖严格的归一化与匹配阈值;其次,为创建高质量的指令模板,需由方言母语者手动编写并修订数千条模板,以确保语言的地道性与任务多样性;此外,数据泄露控制要求严格剔除与测试基准重叠的诗歌,而关键词与关键短语的自动生成虽借助大语言模型,仍需人工抽样验证以确保质量。这些挑战共同指向了诗歌计算化中数据质量、语言多样性及任务泛化能力的平衡问题。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,InstructPoet-AR数据集为诗歌生成与理解任务提供了结构化基准。该数据集最经典的应用场景在于训练指令跟随模型,使其能够根据标题、诗人、时代、格律、韵脚等多维度约束条件,生成符合古典与现代诗学规范的阿拉伯语诗歌。通过覆盖现代标准阿拉伯语及四大方言区的指令模板,模型能够学习跨语言变体的诗歌创作规律,实现从元数据到完整诗篇的端到端生成。
衍生相关工作
该数据集已衍生出系列经典研究工作:基于其多任务架构开发的PoetCoder模型,在阿拉伯语诗歌生成质量评估中刷新了BLEU与人工评测指标;借鉴其方言指令模板构建的Dialect-Aware Poetry Transformer,首次实现了跨五种阿拉伯语变体的风格自适应生成;其诗歌修复任务启发的Rhyme-Consistent Restoration框架,被应用于《一千零一夜》古典诗篇的数字化修复工程;而数据集中的元数据关联分析范式,更催生了计算诗学领域对阿拔斯时期与现代诗歌格律演变的量化比较研究。
数据集最近研究
最新研究方向
在阿拉伯语诗歌生成与理解领域,instructpoet-ar数据集正推动着多方言指令微调的前沿探索。该数据集巧妙融合了现代标准阿拉伯语及四大区域方言的指令模板,为诗歌的生成、续写、修复与分析任务提供了结构化支持。当前研究热点集中于利用其大规模指令对进行模型微调,以提升生成诗歌在韵律、格律和风格上的可控性与文化适应性,同时探索方言指令对模型鲁棒性的影响。这一进展不仅促进了阿拉伯语文化遗产的数字化保存与创新,也为低资源方言的自然语言处理任务提供了重要范例,在计算语言学与数字人文的交叉领域具有深远意义。
以上内容由遇见数据集搜集并总结生成


