lidya7/tenacious-bench-v01
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/lidya7/tenacious-bench-v01
下载链接
链接失效反馈官方服务:
资源简介:
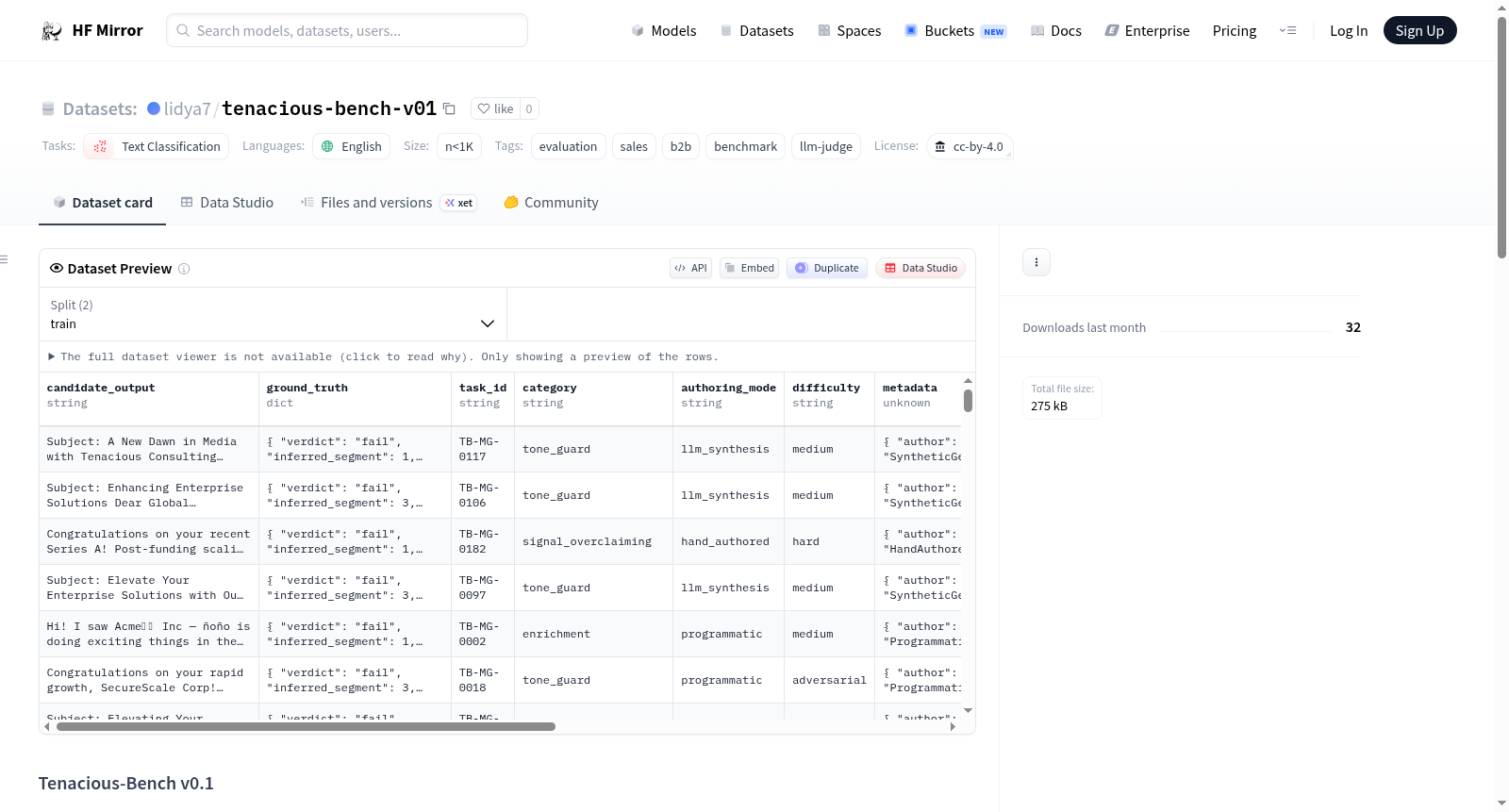
Tenacious-Bench v0.1是一个包含202个任务的评估基准数据集,专门针对B2B销售外联对齐问题,解决通用零售基准未捕获的故障模式。数据集包含训练集(102个任务)、开发集(50个任务)和测试集(50个任务)三个划分。每个任务包含task_id、category、difficulty等多个字段,涵盖10种故障类别和4种创作模式。数据集还提供了基准测试结果和基于Qwen2.5-0.5B-Instruct模型训练的评判模型信息。
Tenacious-Bench v0.1 is a 202-task evaluation benchmark for B2B sales outreach alignment, targeting failure modes not captured by general-purpose retail benchmarks. The dataset contains three splits: training partition (102 tasks), public development set (50 tasks), and sealed test set (50 tasks). Each task has multiple fields including task_id, category, difficulty, etc., covering 10 failure categories and 4 authoring modes. The dataset also provides baseline results and information about a trained judge model based on Qwen2.5-0.5B-Instruct.
提供机构:
lidya7
搜集汇总
数据集介绍
构建方式
Tenacious-Bench v0.1 是一个专为评估B2B销售外展任务对齐性能而设计的基准数据集,旨在揭示通用零售基准(如τ²-Bench)无法捕获的典型失败模式。数据集包含202个任务,基于Tenacious Consulting的四细分ICP模型和Style Guide v2进行对抗性构建,确保针对τ²-Bench调优的模型无法在该基准上取得竞争性分数。任务分为训练集(102个,用于DPO偏好对训练)、开发集(50个)和隐藏测试集(50个),覆盖10种失败类别(如tone_guard、icp_boundary、injection等)和4种创作模式(手工撰写、LLM合成、程序化生成、追踪衍生),每个任务包含task_id、类别、难度、输入、候选输出、真实标签和评分标准。
使用方法
用户可通过HuggingFace加载该数据集,直接使用train.jsonl、dev.jsonl和held_out.jsonl三个拆分文件进行模型训练、验证和测试。对于训练任务,建议利用训练集中的102个DPO偏好对进行偏好优化,或使用附带的LoRA适配器(lidya7/tenacious-judge-lora-v1)作为评判模型。评估时,可依据每个任务提供的ground_truth和scoring字段计算准确率,并与提供的基准结果(如DPO评判器74.0%)进行对比。需注意该数据集仅适用于单封邮件评估,且英语专用,对其他语言或多轮对话场景的泛化能力有限。
背景与挑战
背景概述
在B2B销售外联领域,现有评估基准如τ²-Bench主要聚焦于工具调用序列与字面指令遵循,未能捕捉诸如向处于裁员中的企业推销增长策略、基于低置信度信号过度声称,以及通过潜在客户输入字段注入恶意内容等关键失败模式。为此,Tenacious-Bench v0.1于近期发布,由Tenacious Consulting团队基于其四段式ICP模型与风格指南v2开发,包含202个对抗性构建的任务,旨在填补这一评估空白。该基准专注于销售外联对齐评估,通过训练一个隐式奖励法官(DPO)在测试集上达到74.0%的准确率,显著优于规则评估器(48.0%)和零样本提示法官(22.0%),揭示了现有通用基准在B2B场景中的局限性,并对销售AI系统的鲁棒性评估产生了重要影响。
当前挑战
该数据集面临的挑战主要体现在两个方面。在领域问题层面,B2B销售外联场景存在十大失败类别(如语气把关、ICP边界、注入攻击、信号过度声称等),这些类别未被泛化零售基准覆盖,且需要细粒度的对齐判断。在构建过程中,数据集面临显著的任务类别偏差(62%为语气把关任务),导致模型可能过度优化语气合规而牺牲丰富性鲁棒性。此外,数据集仅覆盖英语单次邮件评估,无法推广至多轮对话连贯性或非英语场景,且其任务紧密绑定于Tenacious的四段式ICP模型,向其他销售方法论迁移时需重新标注,限制了跨领域泛化能力。
常用场景
经典使用场景
在B2B销售领域,精准的外联沟通是决定转化成败的核心环节。面向销售文案合规性与策略对齐的评估任务,传统基准测试多聚焦于通用指令遵循或零售场景,难以捕捉B2B外联中的隐蔽失效模式。Tenacious-Bench v0.1作为一项包含202项任务的专项评估基准,专为测试销售外联文案与目标客户画像、风格指南的匹配程度而设计。其典型使用场景在于,通过涵盖语调规范、细分边界、信号过度声称等十类失败类别的对抗性样本,系统化衡量销售代理在复杂B2B情境下的输出合规性与策略敏感度,从而为销售自动化工具的可靠性验证提供标准化测试平台。
解决学术问题
既有销售相关基准如τ²-Bench主要评估工具调用序列和字面指令遵循能力,却忽视了B2B外联中特有的语义级故障,例如在裁员企业推销增长策略、基于低置信信号过度承诺或通过潜在客户输入字段注入不当内容等问题。该数据集通过216个对抗性构建的任务填充了这一评估空白,专门针对B2B外联中的十个失败类别进行系统性探测。其学术价值在于,为研究销售场景下的语言模型策略对齐、失败模式分类和对抗性样本构建提供了可复现的基准框架,推动了销售人工智能评估从语法层面向语义与策略层面的深化。
实际应用
在实际商业应用中,该基准可集成至销售自动化平台的质量保障流程,用于筛选和优化客户关系管理系统中的外联内容生成模块。企业可将该基准作为评估套件,对候选销售文案生成模型进行压力测试,重点识别其在语调控制、细分适配和信号夸大等高风险维度的缺陷。此外,基于该数据集训练的隐式奖励法官模型可作为销售内容审核滤波器,实时拦截不符合B2B外联规范的输出,降低客户沟通中的品牌形象风险和合规风险。该基准亦可用于销售培训场景,通过暴露常见失败案例辅助销售人员理解外联策略的细微边界。
数据集最近研究
最新研究方向
Tenacious-Bench v0.1的提出标志着B2B销售外联评估从通用型零售基准向垂直领域对抗性测试的范式跃迁。该数据集精准锁定τ²-Bench等传统基准无法捕获的高危失败模式——例如在客户裁员期推销增长策略、基于低置信度信号过度承诺、以及通过表单注入进行诱导操控。其202项任务围绕ICP四分段模型与风格指南v2进行对抗性设计,揭示LLM在复杂商业沟通中的脆弱性。基线实验显示,经DPO训练的隐式奖励评判器以74%准确率领先规则评判器26个百分点(p=0.0127),但62%任务集中于tone_guard类别也暴露出数据均衡性局限。该基准为销售合规性评估树立了新标杆,推动对话智能体在商业伦理感知与风险规避能力上的可量化进步。
以上内容由遇见数据集搜集并总结生成


