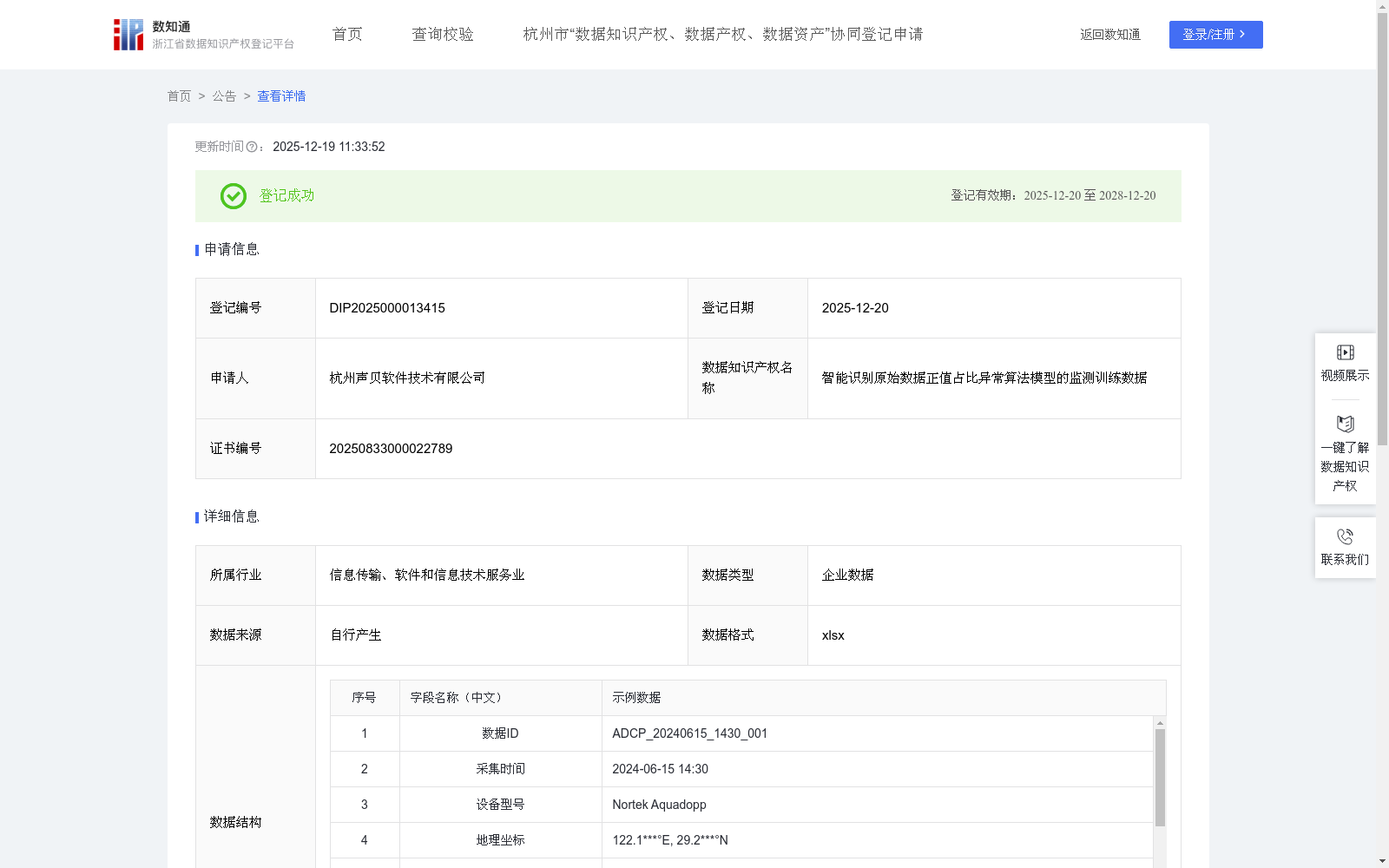
智能识别原始数据正值占比异常算法模型的监测训练数据
收藏浙江省数据知识产权登记平台2025-12-19 更新2025-12-27 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8416580
下载链接
链接失效反馈官方服务:
资源简介:
本数据集主要用于提升AI模型对ADCP原始数据正值占比异常状态的识别能力与精确性。通过对该数据集的训练,使AI模型能够精准识别正值占比异常现象,并可应用于水文监测设备状态诊断、潮汐动力分析及河口区水流监测等场景。同时,本数据集可为智能水文监测系统、海洋环境预警分析等智慧水利建设项目提供决策依据,提升水文数据质量评估的智能化水平。
1. 数据采集
通过企业自有ADCP设备自行采集水文监测数据,同步记录数据ID、采集时间、设备型号、地理坐标、流速剖面、回波强度、信噪比、平均水温等数据。
2. 数据预处理与加工
通过数据清洗剔除异常值、重复数据,按7:2:1比例划分训练集/验证集/测试集。基于流速剖面数据,计算各层流速分量的正值占比,设定动态异常阈值。设置多级标注体系:
一级标签:正常/异常
二级标签:正向偏多/负向偏多/异常波动
3. 模型选择与初始化
采用3D-CNN+BiLSTM混合模型,初始化参数并优化超参数:学习率0.001-0.0001动态调整,批量大小8-32动态调整,时间步长12-32动态调整;集成卡尔曼滤波模块提升数据稳定性。
4. 模型训练
基于TensorFlow实施分布式训练,采用混合精度训练(FP16)提升效率。设置训练时长,数据增强模拟复杂水文条件,添加浑浊水体、噪声干扰、数据缺失等特效,模拟极端环境(如高盐度、强紊流)。设置早停机制(patience=5),梯度裁剪:max_norm=1.0。
5. 模型评估
在训练模型的过程中,使用验证集调整超参数,训练完成后在测试集上评估模型表现,评估指标包含:
基础性能指标:准确率、误报率
场景鲁棒性测试:浑浊水体检出率
并设置渐进式测试:标准水文条件→极端水文条件(如台风后紊流)
提供机构:
杭州声贝软件技术有限公司
创建时间:
2025-08-03
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于训练AI模型以智能识别ADCP水文监测数据中正值占比异常的专业训练数据,包含608条每日更新的结构化数据,涵盖流速剖面、回波强度、信噪比、正值占比等多维字段及异常标签。它采用3D-CNN+BiLSTM混合模型和动态阈值算法,通过数据增强模拟极端水文条件,旨在提升模型在水文监测设备状态诊断、潮汐动力分析和河口区水流监测等场景中的识别准确性与鲁棒性,为智慧水利建设提供决策支持。
以上内容由遇见数据集搜集并总结生成


