CLESC
收藏资源简介:
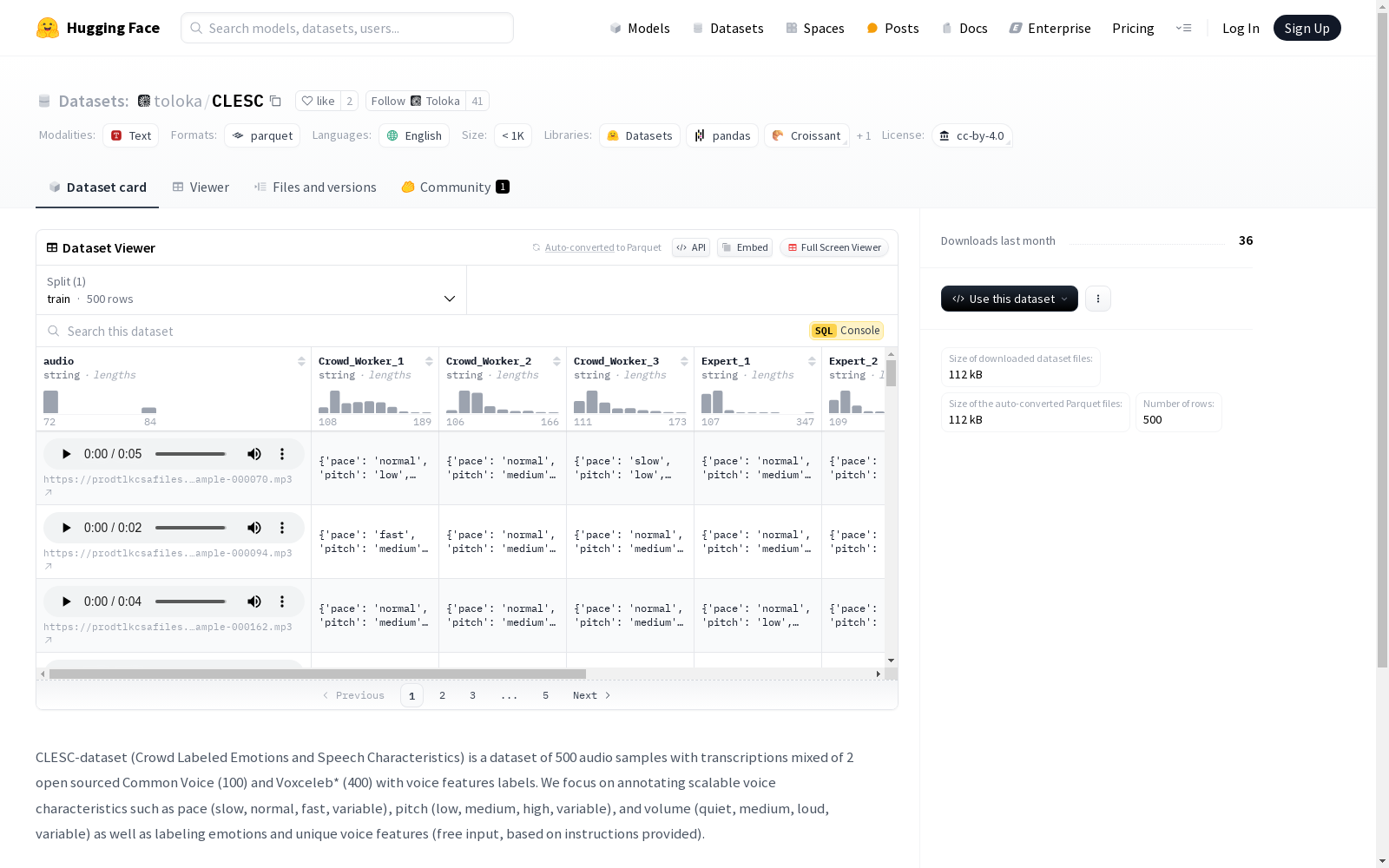
CLESC-dataset是一个包含500个音频样本的数据集,这些样本混合了来自Common Voice(100个)和Voxceleb(400个)的开源数据。数据集专注于标注可扩展的语音特征,如语速(慢、正常、快、变化)、音调(低、中、高、变化)和音量(安静、中、响亮、变化),以及标注情感和独特的语音特征(自由输入,基于提供的指导)。
CLESC-dataset is a dataset consisting of 500 audio samples, which are compiled from open-source data of Common Voice (100 samples) and Voxceleb (400 samples). This dataset focuses on annotating scalable speech features including speech rate (slow, normal, fast, variable), pitch (low, medium, high, variable), and volume (quiet, medium, loud, variable), as well as annotating emotions and unique speech characteristics (free-form input based on provided guidelines).
CLESC 数据集概述
数据集信息
- 名称: CLESC-dataset (Crowd Labeled Emotions and Speech Characteristics)
- 语言: 英语 (en)
- 许可证: CC BY 4.0
- 数据集大小: 475376 字节
- 下载大小: 112382 字节
数据特征
- 音频: 字符串类型
- Crowd_Worker_1: 字符串类型
- Crowd_Worker_2: 字符串类型
- Crowd_Worker_3: 字符串类型
- Expert_1: 字符串类型
- Expert_2: 字符串类型
- Expert_3: 字符串类型
- source_dataset: 字符串类型
- index_level_0: 整数类型 (int64)
数据集配置
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: data/train-*
数据集描述
CLESC 数据集包含 500 个音频样本,这些样本来自两个开源数据集:Common Voice (100 个样本) 和 Voxceleb (400 个样本)。数据集专注于标注可扩展的语音特征,如语速(慢、正常、快、变化)、音调(低、中、高、变化)和音量(安静、中、响亮、变化),以及标注情感和独特的语音特征(自由输入,基于提供的指导)。
贡献者
- Evgeniya Sukhodolskaya
- Ilya Kochik (Toloka)
参考文献
- J. S. Chung, A. Nagrani, A. Zisserman. VoxCeleb2: Deep Speaker Recognition. INTERSPEECH, 2018.
- A. Nagrani, J. S. Chung, A. Zisserman. VoxCeleb: a large-scale speaker identification dataset. INTERSPEECH, 2017.