KGQAGen-10k
收藏KGQAGen-10k 数据集概述
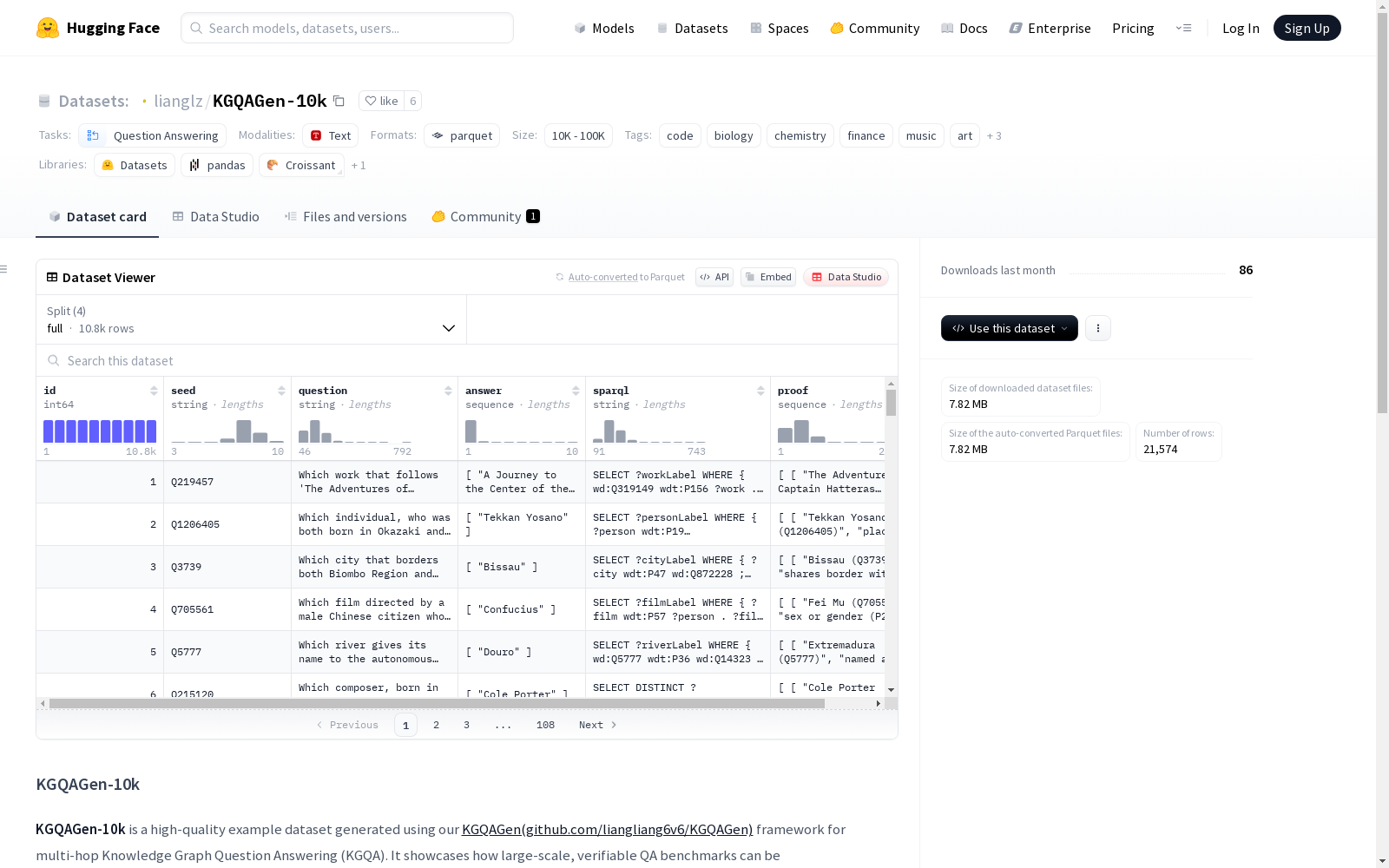
数据集基本信息
- 任务类别: 问答系统
- 标签: 代码、生物学、化学、金融、音乐、艺术、医学、气候、法律
- 规模分类: 10K<n<100K
- 下载大小: 7,822,383 字节
- 数据集大小: 18,956,365 字节
数据集结构
特征
id: 整型,唯一标识符seed: 字符串,种子信息question: 字符串,自然语言问题answer: 字符串序列,标准答案集sparql: 字符串,机器可执行的SPARQL查询proof: 字符串序列的序列,支持子图(证据)
数据划分
full: 9,480,145 字节,10,787 个样本train: 7,583,651 字节,8,629 个样本dev: 938,332 字节,1,079 个样本test: 954,237 字节,1,079 个样本
数据集描述
KGQAGen-10k 是一个高质量的多跳知识图谱问答(KGQA)示例数据集,通过KGQAGen框架从Wikidata自动构建。该数据集展示了如何通过子图扩展、SPARQL验证和LLM引导生成来构建大规模、可验证的QA基准。
示例内容
每个实例包含:
- 自然语言问题
- 标准答案集
- 机器可执行的SPARQL查询
- 最小支持子图(证据)
示例: json { "id": 23, "seed": "Q61391", "question": "Which sport that is a subclass of both gymnastics and dance is the main subject of an item, described by Girl Culture: An Encyclopedia, and associated with a piece of equipment that has use in that sport?", "answer": ["cheerleading"], "sparql": "SELECT ?sport ?sportLabel WHERE { ?sport wdt:P279 wd:Q43450 . ?sport wdt:P279 wd:Q11639 . ?sport wdt:P1343 wd:Q116876043 . SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } }", "proof": [ ["cheerleading (Q61391)", "subclass of (P279)", "gymnastics (Q43450)"], ["cheerleading (Q61391)", "subclass of (P279)", "dance (Q11639)"], ["Q1770162 (Q1770162)", "main subject (P921)", "cheerleading (Q61391)"], ["cheerleading (Q61391)", "described by source (P1343)", "Girl Culture: An Encyclopedia (Q116876043)"], ["pom-pom (Q1187538)", "has use (P366)", "cheerleading (Q61391)"], ["cheerleading (Q61391)", "subclass of (P279)", "human activity (Q61788060)"] ] }
- 1Diagnosing and Addressing Pitfalls in KG-RAG Datasets: Toward More Reliable BenchmarkingRensselaer Polytechnic Institute, University of Toronto, Pennsylvania State University, AT&T Chief Data Office, Griffith University · 2025年


