MotionVid
收藏arXiv2025-04-01 更新2025-04-02 收录
下载链接:
https://humandreamer.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
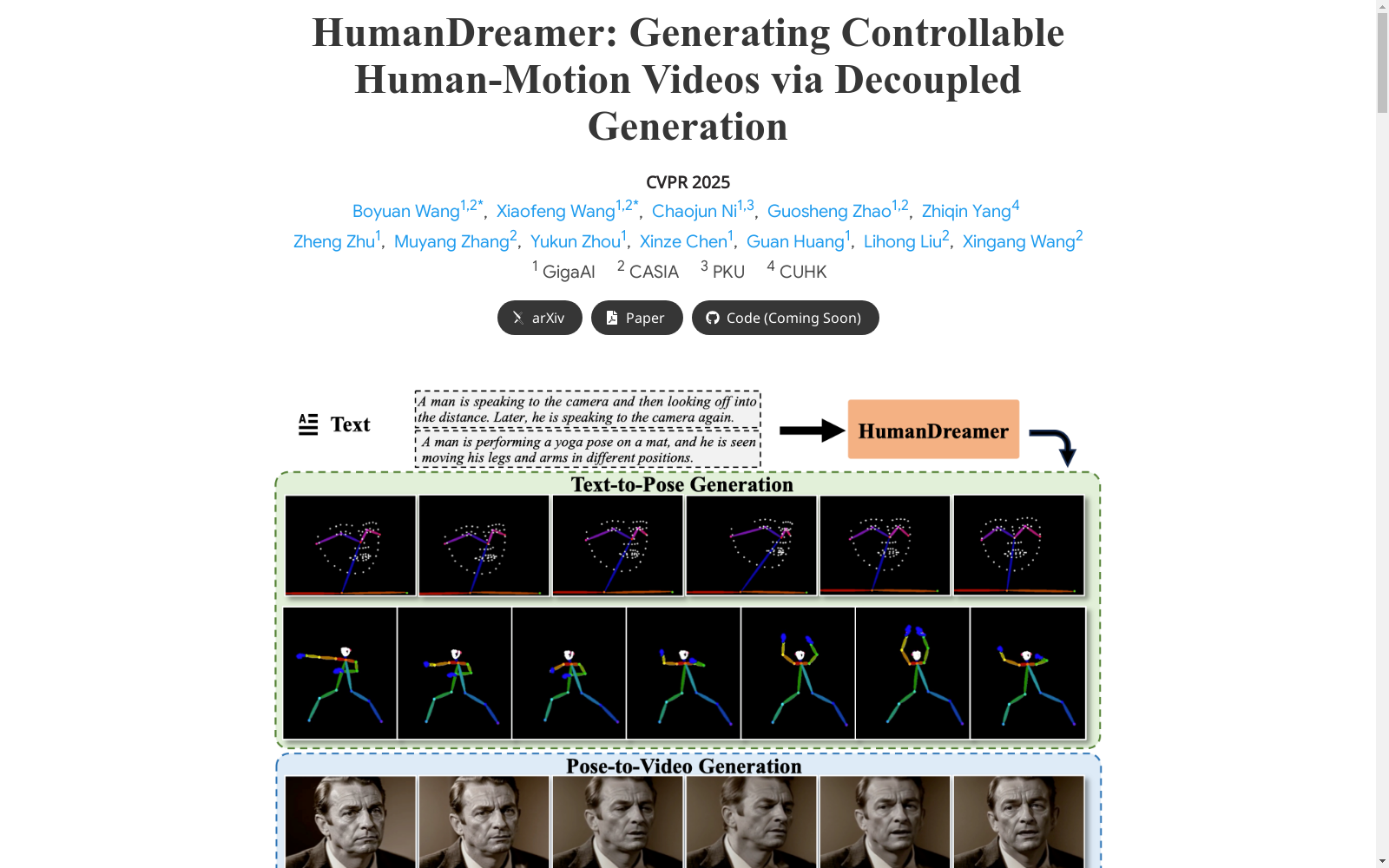
MotionVid是一个大规模的人类运动姿态生成数据集,由中国科学院自动化研究所创建。该数据集包含了约120万文本-姿态对,是目前为止最大的用于人类运动姿态生成的数据集。数据集通过综合互联网和公共数据集中的视频,经过视频质量筛选、数据标注、人类质量筛选和字幕质量筛选等多个步骤,确保了数据的高质量。该数据集旨在支持文本到姿态的生成任务,推动人类运动视频生成领域的研究进展。
MotionVid is a large-scale human motion pose generation dataset created by the Institute of Automation, Chinese Academy of Sciences. It contains approximately 1.2 million text-pose pairs, making it the largest dataset for human motion pose generation to date. The dataset is constructed by comprehensively collecting videos from the Internet and public datasets, and undergoes multiple processing steps including video quality filtering, data annotation, human quality screening and subtitle quality filtering to ensure high data quality. This dataset aims to support text-to-pose generation tasks and promote research progress in the field of human motion video generation.
提供机构:
中国科学院自动化研究所
创建时间:
2025-03-31
搜集汇总
数据集介绍
构建方式
MotionVid数据集的构建采用了多源数据整合与严格的质量过滤流程。研究团队从公开视频数据集(如Kinetics400、Kinetics-700等)和互联网资源中收集了约1000万视频样本,通过镜头分割模型预处理后,采用四级过滤机制:视频质量过滤器基于光流运动强度、文本区域占比、美学评分和模糊度评估;数据标注环节利用视觉语言模型生成动作描述并配合DWPose模型提取2D姿态;人类质量过滤器通过运动幅度、人体占比等指标筛选;最后通过CLoP模型计算文本-姿态语义相似度进行对齐优化。该流程最终从原始数据中保留约12.7%的高质量样本,形成120万对文本-姿态数据。
特点
作为当前最大规模的人体运动姿态数据集,MotionVid具有三个显著特征:其数据多样性体现在覆盖舞蹈、瑜伽等200余类动作,且包含面部和手部关键点;质量可靠性通过四级过滤机制保障,特别采用创新的LAMA损失函数提升文本-姿态语义对齐;技术兼容性表现为支持64帧以上长序列处理,并提供2D/3D运动转换接口。相比同类数据集Holistic-Motion2D,其样本量提升20倍且全量公开,在FID指标上实现62.4%的改进。
使用方法
该数据集支持端到端的文本驱动视频生成流程:首先通过MotionDiT模型将文本描述转化为结构化姿态序列,该模型融合全局注意力机制与局部特征聚合模块;继而采用基于ControlNet的Pose-to-Video框架,将初始参考图像与生成姿态输入时空注意力网络合成视频。下游任务应用时,研究者可提取子集进行动作预测或2D-3D运动提升实验。数据集已按动作类别划分训练/验证集,并提供标准化评估脚本计算FID、R-precision等指标。
背景与挑战
背景概述
MotionVid数据集由GigaAI和中国科学院自动化研究所等机构的研究团队于2025年推出,旨在解决文本到人体运动视频生成中的关键挑战。作为当前最大规模的人体运动姿态生成数据集,MotionVid包含120万文本-姿态对,覆盖舞蹈、瑜伽、日常活动等多样化动作类别。该数据集的创新性在于将视频生成过程解耦为文本到姿态和姿态到视频两个阶段,突破了传统方法依赖现有视频姿态的局限性,显著提升了生成视频的多样性和可控性。其严格的四阶段数据清洗流程(视频质量过滤、数据标注、人体质量过滤和描述质量过滤)确保了数据可靠性,为文本驱动的人体运动生成研究设立了新基准。
当前挑战
MotionVid主要应对两大核心挑战:在领域问题层面,传统文本到视频生成模型难以准确建模人体运动的复杂时空特征,常产生肢体断裂或不真实动作。数据集通过解耦生成框架将高维像素空间映射分解为可控的姿态中间表示,解决了人体运动语义对齐难题。在构建过程中,研究团队面临多模态数据对齐的挑战,包括从原始视频提取的2D姿态与文本描述的精确匹配、处理视频中多人交互场景的歧义性,以及确保长序列姿态的时间连贯性。此外,数据清洗需平衡运动幅度、人脸可见度、人体覆盖率等13项质量指标,最终仅保留约25%的原始数据。
常用场景
经典使用场景
MotionVid数据集在人体动作生成领域具有广泛的应用场景,特别是在文本到姿态生成和姿态到视频生成的任务中。该数据集通过提供大规模的文本-姿态对,支持生成多样化且高质量的人体动作视频。经典使用场景包括虚拟角色动画、体育动作分析以及影视特效制作,其中生成的动作序列能够精确匹配文本描述,满足高保真度的视觉需求。
实际应用
在实际应用中,MotionVid数据集被广泛用于虚拟现实、增强现实和游戏开发中的人体动作合成。例如,在影视制作中,导演可以通过文本描述快速生成角色动作序列,大幅减少动作捕捉的成本和时间。此外,该数据集还支持康复训练中的动作模拟,为医疗领域提供高效的动作分析工具。
衍生相关工作
MotionVid数据集衍生了多项经典工作,包括基于扩散变换器的MotionDiT模型和对比学习框架CLoP。这些工作进一步推动了文本到视频生成领域的发展,例如Animate-X和UniAnimate等模型均借鉴了该数据集的构建方法。此外,数据集还被用于2D-3D动作提升和姿态序列预测等下游任务,扩展了其在多模态生成中的影响力。
以上内容由遇见数据集搜集并总结生成


