ScienceGlossary
收藏Hugging Face2025-03-16 更新2025-03-17 收录
下载链接:
https://huggingface.co/datasets/JonyC/ScienceGlossary
下载链接
链接失效反馈官方服务:
资源简介:
科学术语和短语词典数据集包含来自不同学科的术语和短语,通过抓取网络上的科学术语表和使用ChatGPT-4.0生成的术语编译而成。该数据集旨在用于标记分类任务,并用于辅助简化科学论文,提高实体识别和分类的准确性。
创建时间:
2025-03-06
搜集汇总
数据集介绍
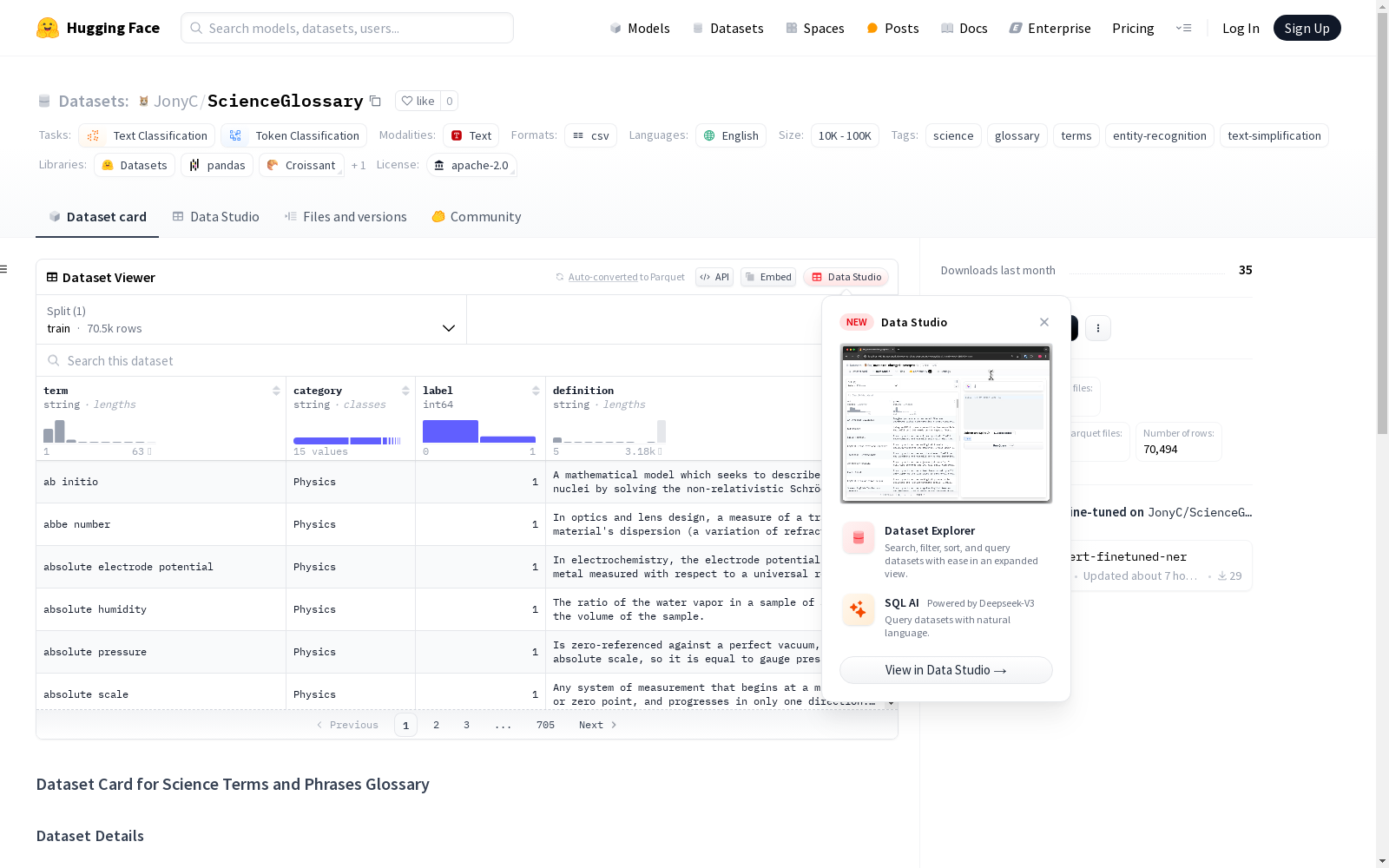
构建方式
ScienceGlossary数据集的构建,是通过从维基百科、NASA以及其他学术资源中网络抓取科学术语和短语的方式进行的。此外,利用ChatGPT-4.0生成了一些术语,以丰富数据集的内容。该数据集旨在为标记分类任务提供支持,包含了科学和非科学词汇,进而为实体识别和分类提供训练基础。
使用方法
在使用ScienceGlossary数据集时,用户可以通过Python的spaCy库来进行实体识别,例如使用'en_core_web_sm'模型。此外,创建者在训练分类模型时发现,该数据集对于命名实体的分类存在一定偏差,因此建议结合使用专门的实体识别工具,以获得更佳的分类效果。
背景与挑战
背景概述
ScienceGlossary数据集,作为一份科学术语与短语汇编,汇集了来自不同学科领域的专业词汇与表述,其创建宗旨在于助力科研文献的简化。该数据集的构建始于近期,由Joni Cohen通过从维基百科、NASA以及其他学术资源中进行网页抓取,并辅以ChatGPT-4.0生成的术语而形成。它旨在服务于实体识别和分类任务,对科研文献处理与自然语言处理领域具有显著的应用价值。
当前挑战
ScienceGlossary数据集在其实践应用中面临若干挑战。首先,在构建过程中,数据集混合了科学和非科学词汇,导致分类模型在区分命名实体时易出现误分类现象。其次,数据集在科学术语的全面性与准确性方面仍有待提升。此外,如何有效融合AI生成的术语与现有学术资源,以确保数据集的质量和可靠性,也是构建过程中的一大挑战。
常用场景
经典使用场景
在科学文献处理与理解的研究领域,ScienceGlossary数据集的经典使用场景主要在于辅助文本分类与实体识别任务。其提供了丰富的科学术语与短语,使得研究者能够通过该数据集训练模型,以区分科学文本中的专业术语与通用词汇,进而实现对科学文档的高效分类与内容提取。
解决学术问题
ScienceGlossary数据集解决了学术研究中对专业术语识别与分类的难题。它通过整合多个学科领域的术语,为实体识别和文本简化提供了有力支撑,有助于提高学术文献处理的自动化程度,降低科研人员的工作负担,增强学术研究的效率。
实际应用
在实际应用中,ScienceGlossary数据集可被用于构建更加智能的文献搜索系统、学术搜索引擎以及辅助科学写作的工具。它能够帮助科研人员在阅读和撰写科学文献时,更快地识别和理解专业术语,从而促进科学知识的传播与普及。
数据集最近研究
最新研究方向
ScienceGlossary数据集的近期研究方向主要集中于提升科学文献中的实体识别与分类准确性,进而促进科学论文文本的简化。该数据集整合了多学科的科学术语和短语,旨在为自然语言处理任务如文本分类和标记分类提供支持。当前研究的热点在于优化模型对命名实体的识别,以降低误分类率,从而更好地服务于文本简化和信息提取等领域。这对于科学知识的普及和学术交流具有显著影响,有助于提高公众对科学概念的理解和学术研究的可及性。
以上内容由遇见数据集搜集并总结生成


