voa_myanmar_audio
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/freococo/voa_myanmar_audio
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含缅甸语语音数据的数据集,适用于自动语音识别、音频转音频和音频分类任务。数据集中包含了来自美国之音和缅甸之声的音频内容,大小在1MB到10MB之间。
创建时间:
2025-06-17
原始信息汇总
数据集概述
基本信息
- 名称: voa_myanmar_audio
- 许可证: PDDL (Public Domain Dedication and License)
- 任务类别:
- 自动语音识别 (Automatic Speech Recognition)
- 音频到音频 (Audio-to-Audio)
- 音频分类 (Audio Classification)
语言与标签
- 语言: 缅甸语 (my)
- 标签:
- Burmese
- Myanmar
- ASR (Automatic Speech Recognition)
- VOA (Voice of America)
- BurmeseVOA
数据规模
- 规模分类: 1M < n < 10M (数据量在1百万到1千万之间)
搜集汇总
数据集介绍
构建方式
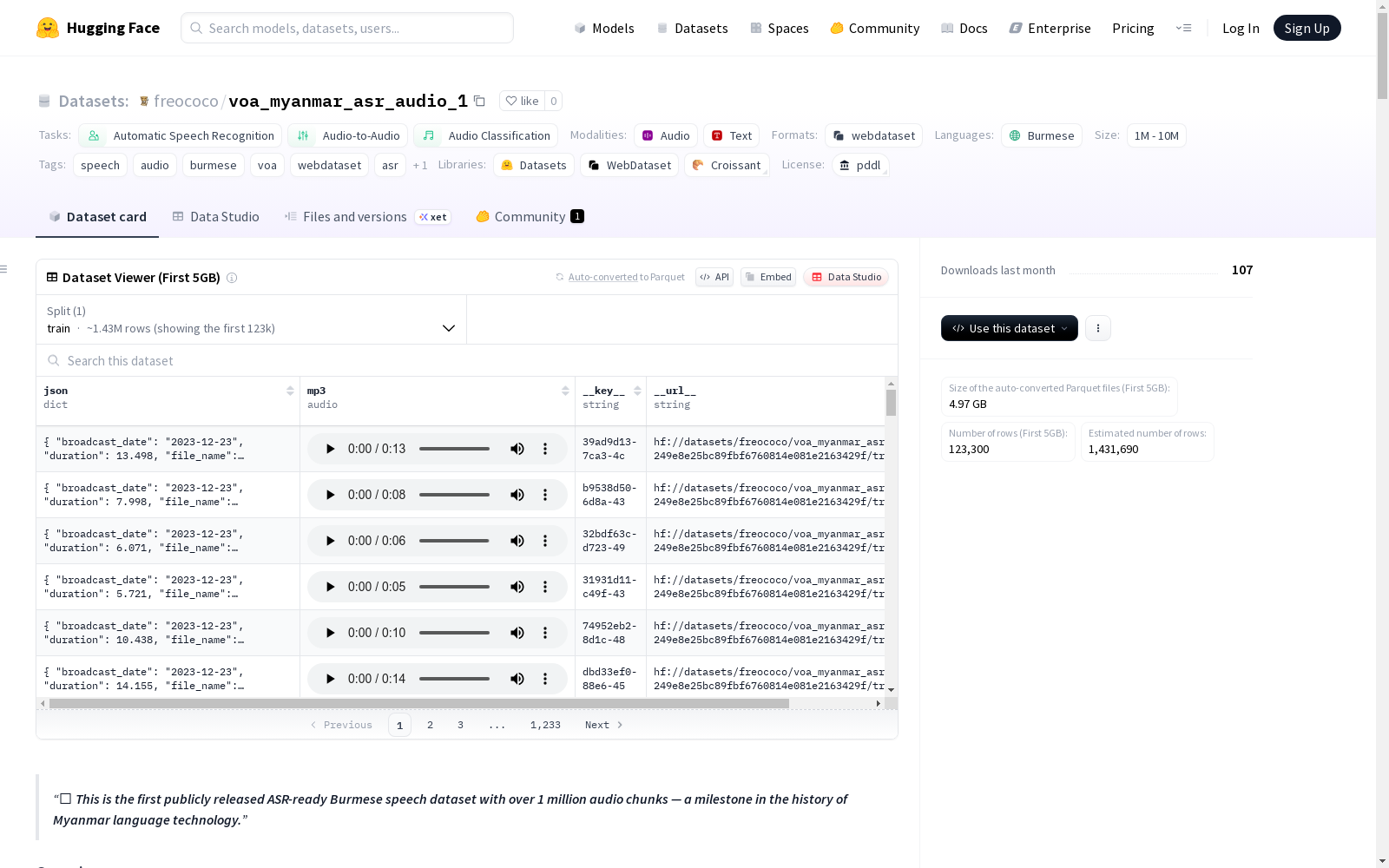
该数据集构建于美国之音缅甸语广播节目的完整档案,通过自动化流程对3,267个原始MP3文件进行精细处理。采用ffmpeg工具基于静音检测的边界划分技术,将每段广播切割为5-15秒的语义单元,配合Python生态链中的pydub进行音频切片、uuid生成唯一标识符、pandas管理元数据,最终通过webdataset工具打包成121个标准化TAR文件。每个音频片段均附带包含文件名、原始广播日期、URL等12项元数据的JSON文件,形成严格对齐的多模态数据结构。
特点
作为缅甸语首个百万量级开源语音数据集,其核心价值体现在时空维度上的丰富性。3,267小时的音频素材跨越2015至2025年十年周期,完整覆盖缅甸社会变迁的语音记录。1.8万个音频片段平均时长6.5-7.5秒,符合ASR模型输入的理想长度分布。数据多样性表现为多说话人、多场景的语音特征,包含新闻播报、现场采访等不同语音模态,且通过WebDataset技术实现流式加载,为低资源语言研究提供了前所未有的实验基础。
使用方法
研究者可通过Hugging Face数据集库直接流式加载该资源,每个样本包含MP3音频字节流及结构化元数据。典型应用场景包括:使用load_dataset方法加载train分片后,可提取音频波形与广播日期、时长等元信息组合训练。对于自监督学习,建议利用音频片段间的时序关系构建对比学习任务;在语音识别领域,需配合外部转录数据对模型进行微调。数据流的动态加载特性特别适合GPU内存受限的研究环境,而分片存储机制支持分布式训练场景下的高效数据调度。
背景与挑战
背景概述
VOA缅甸语音频数据集是由freococo团队于2025年创建的缅甸语语音资源,标志着缅甸语言技术发展的重要里程碑。该数据集基于美国之音缅甸语晨间广播节目的完整档案,通过系统化的采集与处理流程构建而成。数据集涵盖了2015至2025年间的3,267个完整广播节目,包含约180万句级音频片段,总时长超过3,267小时。作为首个公开的大规模缅甸语语音数据集,它不仅填补了该语言在自动语音识别领域的资源空白,更为自监督学习、语音建模等研究提供了重要基础。美国之音作为数据来源,确保了内容的多样性与时效性,使数据集能够反映缅甸语在真实场景中的语音特征和变化。
当前挑战
构建该数据集面临多重技术挑战:在领域问题层面,缅甸语作为低资源语言,其语音数据稀缺且缺乏标准化处理方案,数据集需解决语音边界检测、多说话人识别等核心问题;在工程实现层面,原始广播包含音乐、环境噪声等干扰因素,需开发基于ffmpeg的静音检测算法实现精准分段。数据处理过程中,团队需应对3,687个MP3文件的异构性,设计分布式处理流程确保元数据与音频的精确对齐,最终通过WebDataset技术实现海量数据的高效组织。此外,数据集未包含文本转录信息,这为后续的语音识别研究带来了标注挑战。
常用场景
经典使用场景
在缅甸语语音技术研究中,voa_myanmar_audio数据集作为首个公开的大规模缅甸语语音语料库,为自监督学习提供了丰富的素材。其经典使用场景包括缅甸语自动语音识别系统的预训练与微调,尤其在低资源语言环境下,该数据集通过提供超过180万条句子级音频片段,显著提升了模型对缅甸语语音特征的捕捉能力。
实际应用
在实际应用中,该数据集支撑了缅甸语智能语音助手、广播内容自动转录系统等产品的开发。新闻机构利用其构建的ASR模型可实现广播内容的实时转写,而教育领域则通过语音活性检测技术优化语言学习应用。数据集包含的丰富说话人变体也为声纹识别系统提供了测试基准。
衍生相关工作
基于该数据集衍生的经典工作包括缅甸语wav2vec2预训练模型的优化研究,以及跨语言语音表示迁移实验。部分团队结合外部转录数据开发了端到端ASR系统,另有研究利用其音频片段长度一致性,探索了语音合成中的韵律建模。这些工作显著提升了缅甸语在NLP社区的可见度。
以上内容由遇见数据集搜集并总结生成


