genter
收藏资源简介:
GENTER数据集是一个基于BookCorpus的过滤版本,专门包含名字与其正确第三人称单数代词(he/she)关联的句子。这些句子被转换为模板句子(masked),包含两个模板键:[NAME]和[PRONOUN]。该数据集可用于生成不同名字的句子,并插入正确的代词。数据集的结构包括原始文本、模板文本、性别标签、原始名字、原始代词和代词出现次数等字段。数据集的创建目的是为了训练一个性别偏见模型(GRADIEND模型),以评估与性别相关的梯度信息。数据集的来源是BookCorpus,经过过滤和提取模板结构生成。数据集的创建过程包括过滤BookCorpus的条目,确保每个句子包含至少50个字符、一个名字、正确的代词,并且排除了其他名字、反身代词、所有格代词和性别名词。最终数据集包含83772个句子,并通过BERT模型进一步筛选,确保代词预测的准确性。数据集被分为训练集(87.5%)、验证集(2.5%)和测试集(10%)。
GENTER 数据集概述
数据集简介
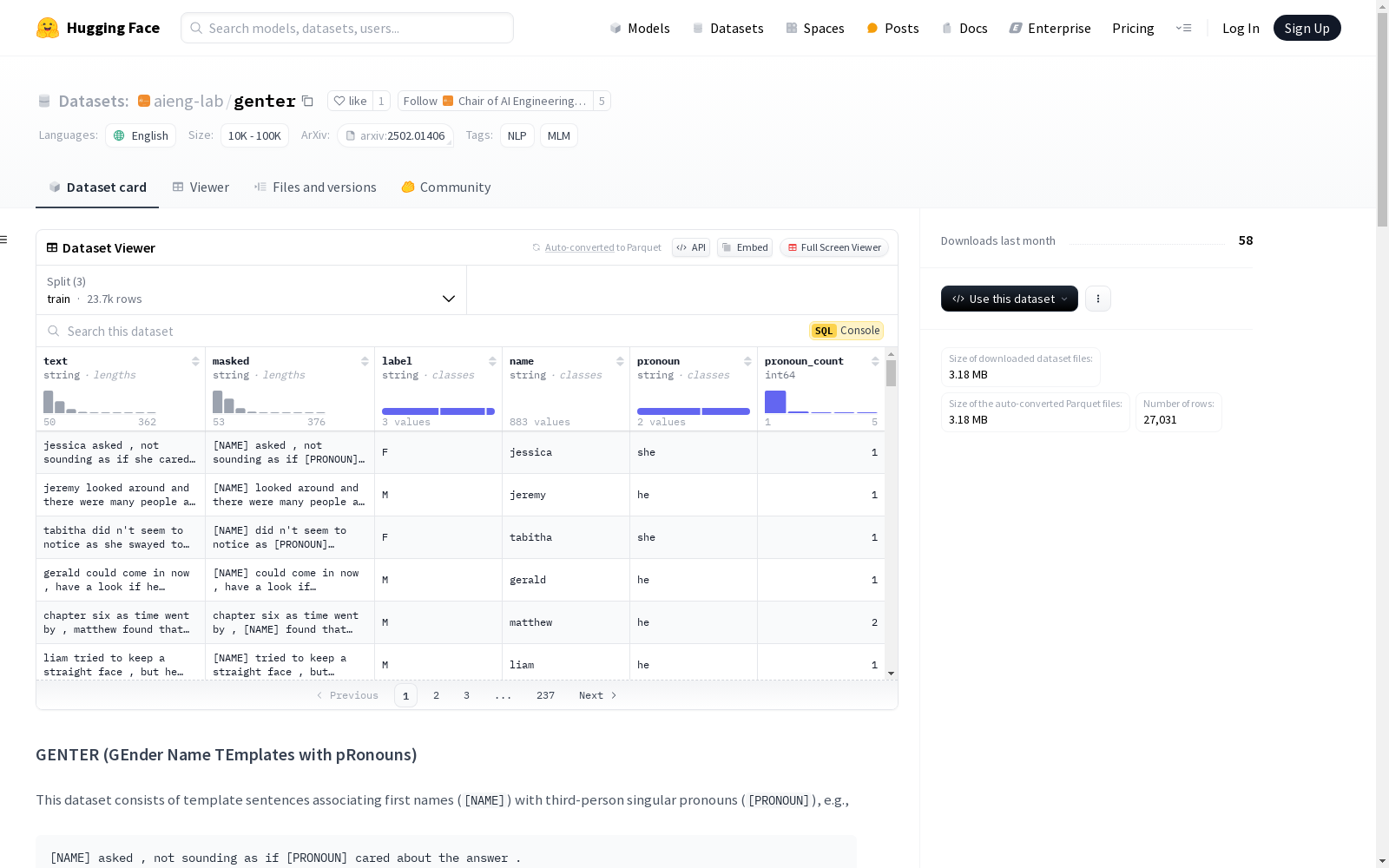
GENTER(GEnder Name TEmplates with pRonouns)数据集是一个包含模板句子的数据集,这些句子将名字([NAME])与第三人称单数代词([PRONOUN])关联起来。该数据集是从BookCorpus中筛选出来的,仅包含名字与其正确的第三人称单数代词(he/she)同时出现的句子。通过这些句子,生成了包含两个模板键([NAME]和[PRONOUN])的模板句子(masked),从而可以生成包含不同名字和相应代词的多样化句子。
数据集结构
- text: BookCorpus中的原始句子。
- masked: 带有模板掩码的句子版本,即包含名字(
[NAME])和代词([PRONOUN])的模板。 - label: 原始名字的性别标签(
F表示女性,M表示男性)。 - name: 原始句子中的名字,在
masked中被掩码为[NAME]。 - pronoun: 原始句子中的代词,在
masked中被掩码为[PRONOUN](he/she)。 - pronoun_count: 代词在句子中出现的次数(通常为1,最多为4)。
数据集划分
- train: 23,653个样本,大小为5,047,914字节。
- validation: 675个样本,大小为144,116字节。
- test: 2,703个样本,大小为579,900字节。
数据集来源
- 原始数据: BookCorpus
- 论文: arXiv:2502.01406
- 代码库: github.com/aieng-lab/gradiend
数据集创建
筛选标准
- 每个句子至少包含50个字符。
- 句子中仅包含一个来自aieng-lab/namexact的名字。
- 句子中不包含其他名字。
- 句子中至少包含一次与名字性别匹配的第三人称代词(he/she)。
- 所有代词出现在名字之后。
- 句子中不包含反身代词(himself/herself)和所有格代词(his/her/him/hers)。
- 排除性别相关的名词(如actor/actress)。
数据处理
使用BERT模型(bert-base-uncased)作为判断模型,确保模型能够正确预测代词。最终筛选出27,031个句子,并将其划分为训练集(87.5%)、验证集(2.5%)和测试集(10%)。
数据集限制
- 由于源自BookCorpus,所有句子均为小写。
引用
bibtex @misc{drechsel2025gradiendmonosemanticfeaturelearning, title={{GRADIEND}: Monosemantic Feature Learning within Neural Networks Applied to Gender Debiasing of Transformer Models}, author={Jonathan Drechsel and Steffen Herbold}, year={2025}, eprint={2502.01406}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2502.01406}, }
数据集作者