2508-wds-evals
收藏Hugging Face2025-11-24 更新2025-11-26 收录
下载链接:
https://huggingface.co/datasets/HPLT/2508-wds-evals
下载链接
链接失效反馈官方服务:
资源简介:
HPLT 3.0:基于Web Document Scorer (WDS)阈值采样的细粒度评估结果,包括西班牙语和法语的比较。
提供机构:
HPLT创建时间:
2025-11-18
原始信息汇总
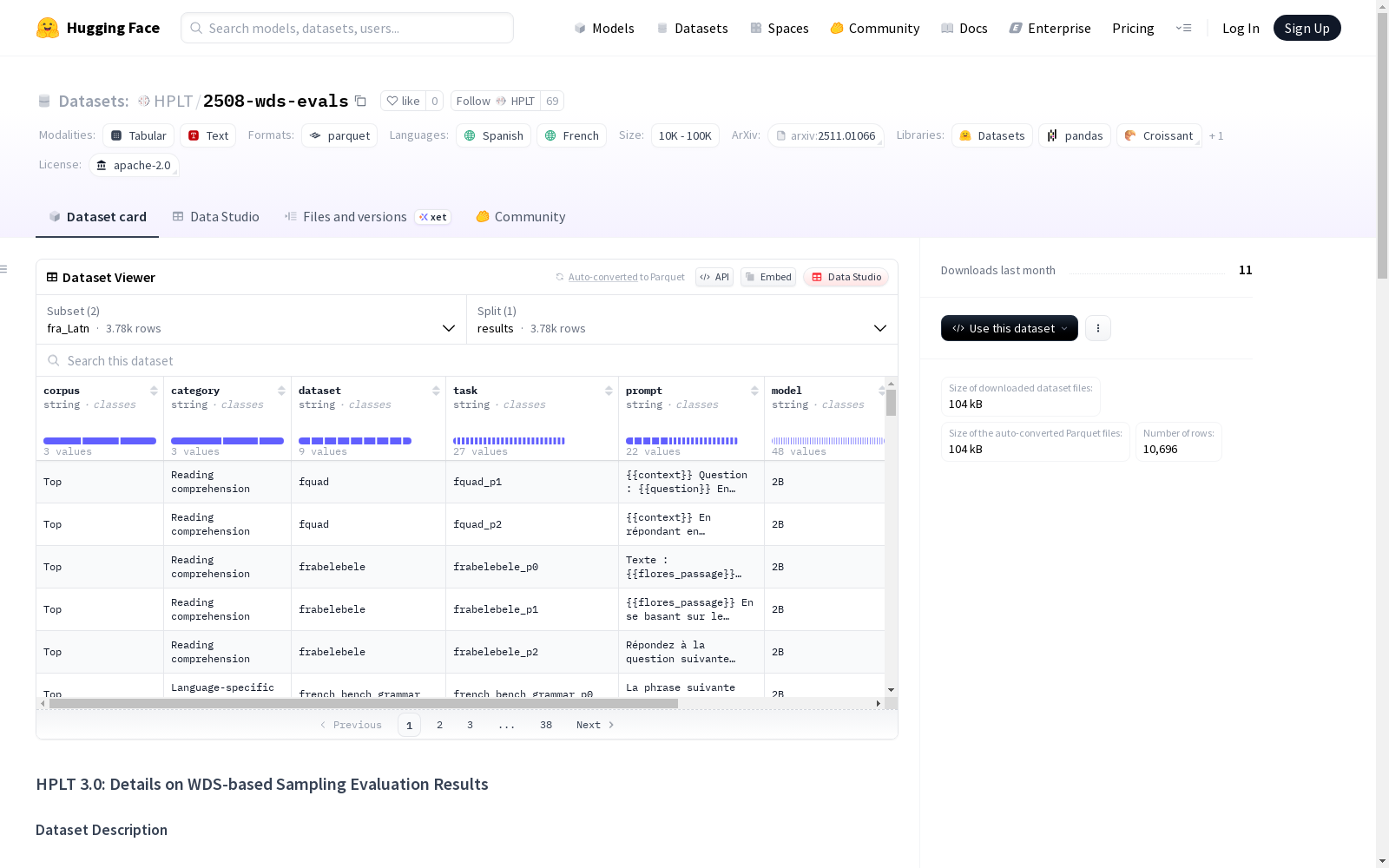
数据集概述
基本信息
- 数据集名称: HPLT 2508-wds-evals
- 许可协议: Apache 2.0
- 支持语言: 西班牙语、法语
- 维护机构: High Performance Language Technologies (HPLT)
- 论文链接: https://arxiv.org/abs/2511.01066
- 代码仓库: https://github.com/hplt-project/hplt-e/tree/main
数据集描述
本数据集包含HPLT 3.0发布评估的细粒度结果,比较使用不同Web Document Scorer (WDS)阈值采样的新HPLT 3.0语料库,重点关注西班牙语和法语。比较三种配置:Top、Random和Bottom。
配置信息
法语配置 (fra_Latn)
- 特征字段:
- corpus: string
- category: string
- dataset: string
- task: string
- prompt: string
- model: string
- ckpt_num: int64
- score: float64
- 数据分割: results
- 样本数量: 3784
- 数据集大小: 909987字节
- 下载大小: 33013字节
西班牙语配置 (spa_Latn)
- 特征字段:
- corpus: string
- category: string
- dataset: string
- task: string
- prompt: string
- model: string
- ckpt_num: int64
- score: float64
- 数据分割: results
- 样本数量: 6912
- 数据集大小: 1511136字节
- 下载大小: 71232字节
字段说明
corpus: 语料库名称 (Top,Random,Bottom)category: 任务类别dataset: 评估数据集名称task: 评估任务(指向特定提示)prompt: 用于评估的提示model: 预训练标记数量 (B)ckpt_num: 模型的检查点编号score: 标准指标性能得分
使用方式
python from datasets import load_dataset dataset = load_dataset("HPLT/2508-wds-evals", "spa_Latn", split="results").to_pandas()
引用格式
@article{oepen2025hplt, title={HPLT~{} 3.0: Very Large-Scale Multilingual Resources for LLM and MT. Mono-and Bi-lingual Data, Multilingual Evaluation, and Pre-Trained Models}, author={Oepen, Stephan and Arefev, Nikolay and Aulamo, Mikko and Ba{~n}{o}n, Marta and Buljan, Maja and Burchell, Laurie and Charpentier, Lucas and Chen, Pinzhen and Fedorova, Mariya and de Gibert, Ona and others}, journal={arXiv preprint arXiv:2511.01066}, year={2025} }
联系方式
- Vladislav Mikhailov: vladism@ifi.uio.no
- Stephan Oepen: oe@ifi.uio.no
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,数据质量对模型性能具有决定性影响。该数据集通过Web文档评分器(WDS)对HPLT 3.0语料库进行分层采样,构建了三种实验配置:从高评分端采样的Top组、随机均匀采样的Random组以及从低评分端采样的Bottom组。每种配置均基于100B训练令牌规模,采用2.2B参数规模的Llama架构解码器模型进行预训练,并通过多语言评估框架HPLT-E在124项任务中系统验证不同采样策略的效果。
特点
作为多语言模型评估的重要基准,该数据集涵盖西班牙语与法语两种典型罗曼语族语言,包含3784至6912个评估实例。其核心特征体现在细粒度的评估维度设计:每个数据实例完整记录语料来源、任务类别、评估数据集、具体任务指令、提示模板、模型参数及性能得分,并通过标准化字段呈现九种类型学多样语言的全方位评估结果,为语言模型质量评估提供多维参照体系。
使用方法
研究者可通过HuggingFace数据集库直接加载该评估结果,指定语言配置(如spa_Latn)即可获取结构化数据。典型应用流程包括使用load_dataset函数加载目标语种评估集,转换为pandas数据结构进行分析。数据实例包含语料策略、任务分类、提示模板和模型性能等关键字段,支持研究者进行跨语料采样策略的对比分析、多任务性能评估以及预训练模型能力诊断等深度研究。
背景与挑战
背景概述
在自然语言处理领域,大规模多语言语料库的构建与评估对于提升预训练模型性能至关重要。HPLT项目团队于2025年发布了2508-wds-evals数据集,该数据集聚焦西班牙语和法语,通过对比基于Web文档评分器(WDS)阈值的三种采样策略(Top、Random、Bottom),系统评估了2.2B参数Llama架构模型在百亿 tokens 训练数据上的表现。该研究依托HPLT-E多语言评估框架,涵盖九种类型学多样语言的124项任务与500余提示模板,为语料筛选策略的优化提供了实证依据。
当前挑战
该数据集致力于解决多语言预训练模型在语料质量筛选与评估标准化方面的核心难题。构建过程中面临双重挑战:其一需设计能准确反映语料质量梯度的WDS阈值划分方法,确保Top与Bottom采样能有效区分高低质量语料;其二需克服多语言评估的复杂性,通过统一框架协调九种语言在文本分类、释义检测等任务中的指标对齐问题,同时保持提示模板在不同语言间的语义一致性。
常用场景
经典使用场景
在自然语言处理领域,该数据集为大规模多语言预训练模型的评估提供了关键基准。其经典使用场景聚焦于比较不同Web文档评分器阈值下采样的语料性能,通过Top、Random和Bottom三种配置系统分析模型在西班牙语和法语上的表现。研究人员可借助该数据集深入探索数据筛选策略对模型泛化能力的影响,为优化预训练数据选择提供实证依据。
衍生相关工作
基于该数据集衍生的经典研究包括多语言评估框架HPLT-E的持续优化,以及文档质量评分机制的改进工作。相关团队进一步扩展了评估语言范围至捷克语、乌克兰语等九种语言,推动了跨语言模型评估标准的统一。这些衍生工作共同构成了数据驱动的大语言模型评估体系,为后续研究提供了可复现的基准范式。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模多语言预训练模型的评估方法正成为研究热点。该数据集聚焦于基于网络文档评分器的采样策略比较,通过对比Top、Random和Bottom三种配置在西班牙语和法语上的表现,揭示了数据质量筛选对模型性能的深层影响。当前研究前沿集中于探索多语言评估框架下数据采样策略与模型泛化能力的关系,特别是在低资源语言场景中的迁移效果。随着多语言大模型需求的增长,该数据集为优化训练数据选择提供了实证基础,推动了数据高效利用与模型性能平衡的研究进程。
以上内容由遇见数据集搜集并总结生成


