Flmc/DISC-Med-SFT
收藏Hugging Face2023-08-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Flmc/DISC-Med-SFT
下载链接
链接失效反馈资源简介:
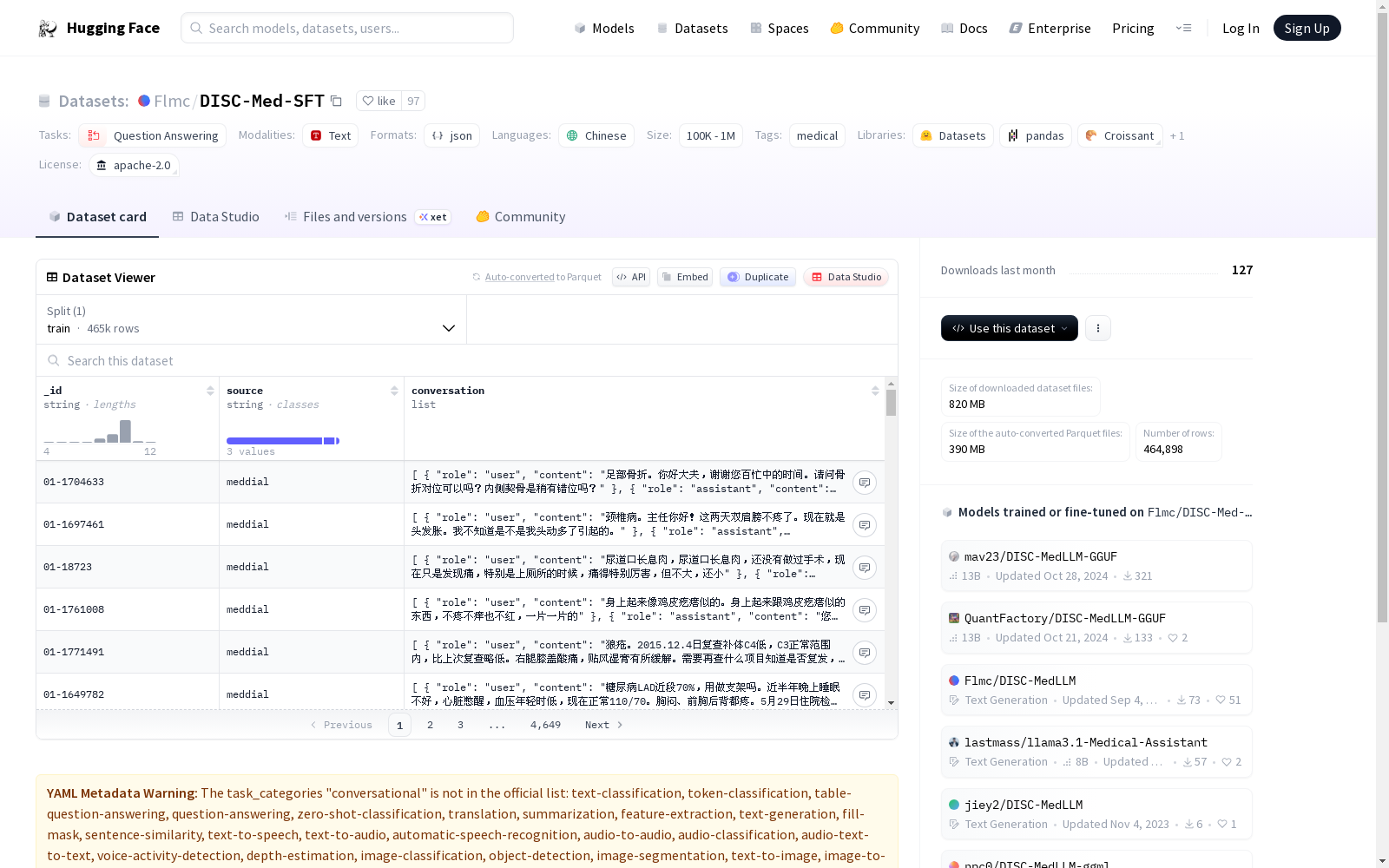
这是一个包含DISC-Med-SFT数据集子集的仓库,主要用于医疗领域的问答和对话任务,数据量为10万到100万之间,语言为中文。
这是一个包含DISC-Med-SFT数据集子集的仓库,主要用于医疗领域的问答和对话任务,数据量为10万到100万之间,语言为中文。
提供机构:
Flmc
原始信息汇总
数据集概述
许可证
- Apache 2.0
任务类别
- 问答
- 对话
语言
- 中文
标签
- 医疗
数据集大小
- 100K<n<1M
搜集汇总
数据集介绍
构建方式
Flmc/DISC-Med-SFT数据集的构建,是在广泛收集医疗健康领域相关文本的基础上,通过专业筛选与处理后,形成了包含数十万至百万量级的语料集合。该数据集的构建注重于真实医疗场景中的对话和问答,旨在为自然语言处理技术在医疗健康领域的应用提供高质量的数据支撑。
使用方法
用户在使用Flmc/DISC-Med-SFT数据集时,需遵循Apache-2.0协议,确保合法合规使用。数据集适用于构建医疗问答系统、对话系统等,用户可通过数据集提供的接口或下载数据文件的方式进行应用开发与研究。在应用过程中,应关注数据隐私保护,确保符合相关法律法规要求。
背景与挑战
背景概述
在医学信息处理领域,自然语言处理技术正日益发挥重要作用。Flmc/DISC-Med-SFT数据集,作为医学问答与对话系统研究的重要资源,由复旦大学自然语言处理实验室于近年来创建。该数据集聚焦于中文医学文本,旨在促进医学领域内的自然语言理解与生成任务,为研究人员提供了丰富的语料资源,对于推动医疗信息处理技术的发展具有显著的影响力。
当前挑战
该数据集在解决医学问答与对话系统中面临诸多挑战,包括数据集的规模、数据质量以及数据的多样性。首先,构建大规模且高质量的医学问答数据集本身就是一项艰巨的任务。其次,医学领域的专业知识复杂度高,对数据标注的准确性提出了更高的要求。再者,如何确保数据集在满足研究需求的同时,兼顾患者隐私与数据安全,亦是构建过程中的重要考量。
常用场景
经典使用场景
在医学信息处理领域,Flmc/DISC-Med-SFT数据集被广泛用于构建与医疗健康相关的问题回答系统。该数据集涵盖了大量的医疗对话记录,使得研究者能够基于此开发出能够准确理解和回应患者咨询的智能助手。
解决学术问题
该数据集解决了医学自然语言处理中的一项关键问题,即医学术语的识别与理解。它为研究者提供了一个丰富的语料库,使得模型能够学习并掌握专业医学术语,从而在医疗健康咨询、疾病诊断辅助等方面发挥重要作用。
实际应用
实际应用中,基于Flmc/DISC-Med-SFT数据集开发的系统已经应用于医院智能问答、远程医疗咨询等多个场景,极大地提高了医疗服务效率,降低了医患交流的成本。
数据集最近研究
最新研究方向
在医学问答与对话系统研究领域,Flmc/DISC-Med-SFT数据集的构建旨在推动自然语言处理技术在医疗健康信息处理中的应用。该数据集近期的研究方向主要集中在深度学习模型在医疗问答中的性能优化,以及医患对话系统的自然性和有效性提升。其研究成果不仅为医疗信息检索提供了新的视角,也为医疗人工智能的发展提供了可靠的数据支撑,对于促进智慧医疗建设具有深远的影响。
以上内容由遇见数据集搜集并总结生成


