AnyInsertion
收藏arXiv2025-04-21 更新2025-04-23 收录
下载链接:
https://song-wensong.github.io/insert-anything/
下载链接
链接失效反馈官方服务:
资源简介:
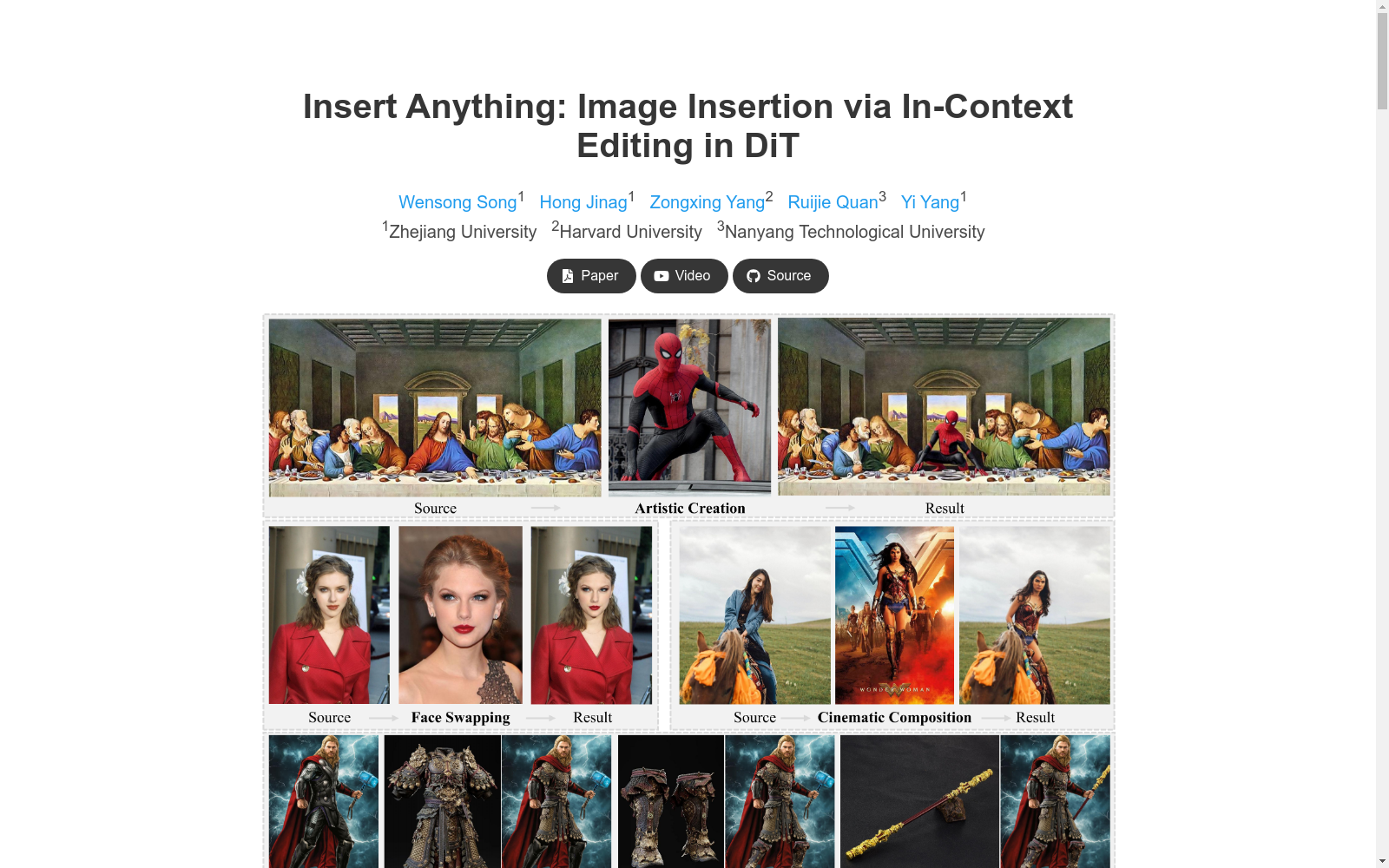
AnyInsertion数据集是由浙江大学、哈佛大学和南洋理工大学共同创建的大型数据集,包含12万对提示-图像对,涵盖了人物、物体和服装插入等多种任务。该数据集支持面具提示和文本提示两种控制模式,提供了高分辨率的图像,适用于各种实际插入任务。数据集的构建过程包括从互联网、人类视频和多视角图像中收集图像对,并生成相应的标签。该数据集旨在支持多样化的图像插入任务,如艺术创作、真实人脸交换、电影场景布局、虚拟试穿、配饰定制和数字道具替换等。
提供机构:
浙江大学, 哈佛大学, 南洋理工大学
创建时间:
2025-04-21
搜集汇总
数据集介绍
构建方式
AnyInsertion数据集的构建采用了多源数据采集与智能处理相结合的策略。通过整合电商平台、HumanVid视频数据集和MVImgNet多视角图像库,构建了包含12万提示-图像对的大规模数据集。针对不同插入类别(人物、物体、服装)设计了混合掩码策略,结合基于Bessel曲线的形状增强和分割掩码,确保模型能够处理自由形态的编辑区域。数据生成阶段采用GroundedDINO和SAM模型自动生成参考掩码和目标掩码,并通过文本引导的编辑模型创建多样化的文本提示对,形成结构化数据元组。
使用方法
使用该数据集需区分两种控制模式:掩码提示模式下,模型接收(参考图像、参考掩码、目标图像、目标掩码)四元组输入,通过指定区域完成元素插入;文本提示模式下则采用(参考图像、参考掩码、目标图像、源图像、文本描述)五元组结构,依据自然语言指令实现编辑。评估时建议采用PSNR、SSIM、LPIPS和FID多指标体系,特别注意复杂场景下身份特征保留与视觉协调性的平衡。对于小区域插入任务,推荐启用自适应裁剪机制以增强细节表现。
背景与挑战
背景概述
AnyInsertion数据集由浙江大学、哈佛大学和南洋理工大学的研究团队于2025年创建,旨在解决基于参考图像的多样化图像插入任务。该数据集包含12万组提示-图像对,覆盖人物、物体和服装等多种插入场景,支持掩码提示和文本提示两种控制模式。通过利用扩散变换器(DiT)的多模态注意力机制,AnyInsertion为图像编辑领域提供了统一的解决方案,显著提升了虚拟试穿、艺术创作和场景合成等实际应用的性能。该数据集的创新性在于其广泛的任务覆盖范围和灵活的提示方式,为图像编辑研究树立了新的基准。
当前挑战
AnyInsertion数据集面临的挑战主要体现在两个方面:在领域问题方面,传统的图像插入方法通常针对单一任务设计,缺乏统一处理多样化插入场景的能力,且难以同时保持插入元素的特征完整性和与目标场景的视觉协调性;在构建过程方面,数据收集需解决多视角图像匹配、运动模糊过滤和高质量人物姿态对齐等技术难题,同时需平衡掩码提示和文本提示数据的比例,确保模型能够灵活适应不同的控制模式。此外,保持插入元素的高频细节和语义一致性也是数据集构建中的关键挑战。
常用场景
经典使用场景
在计算机视觉领域,AnyInsertion数据集为图像插入任务提供了多样化的参考图像与目标场景组合,其经典使用场景包括虚拟试衣、人脸替换以及数字道具替换等。通过提供丰富的图像对和多样化的控制模式,该数据集成为训练和评估图像编辑模型的理想选择,特别是在需要保留参考元素身份特征的同时实现与目标场景自然融合的任务中。
解决学术问题
AnyInsertion数据集解决了图像插入领域中的三个核心学术问题:任务特定性限制、控制模式单一性以及视觉参考一致性不足。通过涵盖人物、物体和服装等多种插入任务,并支持掩码和文本两种控制模式,该数据集推动了通用图像插入框架的发展,显著提升了模型在复杂场景下的适应性和编辑质量。
实际应用
在实际应用层面,AnyInsertion数据集为电子商务、影视制作和数字艺术创作提供了强大支持。例如,在虚拟试衣场景中,该数据集能够帮助生成逼真的服装试穿效果;在影视后期制作中,可实现数字道具的无缝替换;而在艺术创作领域,则为创意图像的合成提供了高效工具。
数据集最近研究
最新研究方向
在计算机视觉领域,AnyInsertion数据集代表了图像编辑技术的最新突破,特别是在基于参考的图像插入任务中。该数据集通过提供12万对提示-图像对,覆盖了人物、物体和服装插入等多种任务,为统一框架的开发奠定了基础。前沿研究集中在利用扩散变换器(DiT)的多模态注意力机制,实现掩码和文本引导的编辑,并通过上下文编辑机制将参考图像作为上下文信息处理,确保插入元素与目标场景的视觉和谐。这一方向不仅解决了传统方法在任务特定性和控制模式上的局限性,还在创意内容生成、虚拟试穿和场景合成等实际应用中展现出巨大潜力。
相关研究论文
- 1Insert Anything: Image Insertion via In-Context Editing in DiT浙江大学, 哈佛大学, 南洋理工大学 · 2025年
以上内容由遇见数据集搜集并总结生成


